上周听了院长讲了一课ES之后,绕梁三日,并对里面关于节点failover 的逻辑非常好奇,乃至自己这两天捣鼓一下,没事做设定一个很简单的场景,想看ES是怎么走的。看了不少文章翻了不少代码,有收获顾记录之。
本篇打算讨论下面这个很简单的问题:
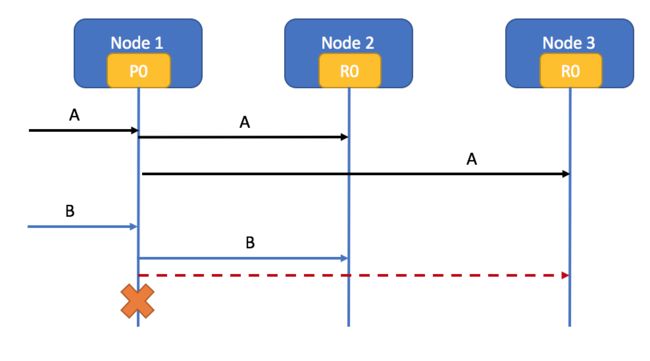
- 客户端首先发送文档A到Node1 也就是Primary Shard 索引文档A(简单起见就假设直接发送给Primary),并且文档A已正常同步到所有的Replica
- 接着客户端发送文档B到Node1 并索引文档B,这时Node1 会同步到Node2 和Node3
- 假设Node1 到Node3 的链路超时了并且这时Node1 挂了。
其实大家都知道这时Cluster会是红色,因为shard0 的 primary 挂了。那么ES会做下面两件事的哪一件呢?
- 随便找到一个replica 并推选为primary,如果它保存的数据不是最新的,则replica之间会先进行一次同步(在INITIALIZING 阶段)
- ES能找出Node2 的R0是包含了最新代码的,因此直接推举Node2 的R0 为primary
答案是:如果是Elasticsearch 5.x 则是后者,其他版本不详(没看其他版本代码),ES会把当前状态标成RED,并且会把Node2 的R0晋升到primary,然后会把剩下的一个R0 标记成UNassigned,待Node1 重新加入集群时,会为Node1 分配这个UNassigned的R0。
下面就来过一遍代码!
预备知识
这里先分享Jasper兄的两篇博文,这两篇博文详细介绍了ES的Gateway 模块和Allocation 模块,本文是跟着Jasper兄的思路继续走读完剩下的代码而已。
elasticsearch源码分析之Gateway模块
elasticsearch源码分析之Allocation模块
拜读完后你基本能够了解到ES在什么时候会执行一个Allocation 操作。这里再简单总结一下几个贯穿其中的类:
-
ShardStateAction响应Shard State 改变时间的逻辑入口 -
AllocationServiceAllocation 的主逻辑类,它回答的问题是index 的shards 应该在nodes 间如何分配,这个类封装了RoutingNodes、GatewayAllocator等,我们要关注的自然就是里面的applyFailedShards()方法 -
Allocator有很多子类,具体的子类通过makeAllocationDecision()方法来决定某个策略并会产生一个是否进行allocation的Decision 决策,举个例子,PrimaryShardAllocator会决策一个primary shard 是否应该存放在本 Node 上,Decision类就会有一堆的枚举结果。 -
RoutingNodes,用源码上的描述说就是代表了clusterState对象的信息,封装出很多用于本次clusterState变更事件需要用到的很多属性,例如当前的nodesToShards、unassignedShards、assignedShards等
源码分析
从#Jasper 的博文#你应该会了解到一个Cluster初始化会如何去allocate index的所有的shards,那我还是接着来看我的这个场景,当Node1 的P0 挂了,会做些什么事情。
首先从最顶层入口开始
ShardStateAction ::ShardFailedClusterStateTaskExecutor
它有一个逻辑方法execute(),其中一段逻辑是先把当前ClusterState中的shards 归类
ShardRouting matched = currentState.getRoutingTable().getByAllocationId(task.shardId, task.allocationId);
if (matched == null) {
Set inSyncAllocationIds = indexMetaData.inSyncAllocationIds(task.shardId.id());
// mark shard copies without routing entries that are in in-sync allocations set only as stale if the reason why
// they were failed is because a write made it into the primary but not to this copy (which corresponds to
// the check "primaryTerm > 0").
if (task.primaryTerm > 0 && inSyncAllocationIds.contains(task.allocationId)) {
logger.debug("{} marking shard {} as stale (shard failed task: [{}])", task.shardId, task.allocationId, task);
tasksToBeApplied.add(task);
staleShardsToBeApplied.add(new StaleShard(task.shardId, task.allocationId));
} else {
// tasks that correspond to non-existent shards are marked as successful
logger.debug("{} ignoring shard failed task [{}] (shard does not exist anymore)", task.shardId, task);
batchResultBuilder.success(task);
}
} else {
// failing a shard also possibly marks it as stale (see IndexMetaDataUpdater)
logger.debug("{} failing shard {} (shard failed task: [{}])", task.shardId, matched, task);
tasksToBeApplied.add(task);
failedShardsToBeApplied.add(new FailedShard(matched, task.message, task.failure));
}
上面代码完成了把所有fail的shards进行归类,并把所有已经处于stale状态的节点都筛选出来,这段代码对于ES < 5 来说都是新概念,所以逐个技术点做介绍;
AllocationId 这个是master 在保存一个具体的index的shard时配置的一个唯一标识一个物理shard data的标识,在代码里用getByAllocationId(shardId, allocationId)可以唯一找到一个ShardRouting 对象,在这个例子里我们可以认为原始的P0,两个R0都具有自己的allocationID,最后Node1 的那个allocationID将会标记为UNassigned.
stalesShards 标识为不是包含最新数据的shard,在ES5 里这种shard是不会被推举成primary的
failedShards 本次clusterState change事件中fail 的shard。
indexMetaData.inSyncAllocationIds ES5 中的cluster state中维护着这样一个Set,在这个里面的allocationId的集合才会被认为是包含最新的data的。
那么用我假设的例子来演绎的话就是:node1 的P0 是failShard,Node3的R0 是staleShard
想要了解更详细信息的可以参考下面这个Elasticsearch 的Blog,这里就是介绍了ES5 的这个新功能,它能维护着一个具有最新数据集合的shards的ID集合
Elasticsearch Internals - Tracking in-sync shard copies
(https://www.elastic.co/blog/tracking-in-sync-shard-copies)
Allocation IDs are assigned by the master during shard allocation and are stored on disk by the data nodes, right next to the actual shard data. The master is responsible for tracking the subset of copies that contain the most recent data. This set of copies, known as in-sync allocation IDs, is stored in the cluster state, which is persisted on all master and data nodes. Changes to the cluster state are backed by Elasticsearch’s consensus implementation, called zen discovery. This ensures that there is a shared understanding in the cluster as to which shard copies are considered as in-sync, implicitly marking those shard copies that are not in the in-sync set as stale.
好了对fail 的shard 分好类后就会调allocationService 的方法
try {
maybeUpdatedState = applyFailedShards(currentState, failedShardsToBeApplied, staleShardsToBeApplied);
batchResultBuilder.successes(tasksToBeApplied);
}
ClusterState applyFailedShards(ClusterState currentState, List failedShards, List staleShards) {
return allocationService.applyFailedShards(currentState, failedShards, staleShards);
}
在allocationService的applyFailedShards()里面最开始做的就是先把所有的staleShards 排除在可以做Routing 之外,并产生出一个临时的clusterState,进而构造出一个RoutingNodes对象。
ClusterState tmpState = IndexMetaDataUpdater.removeStaleIdsWithoutRoutings(clusterState, staleShards);
RoutingNodes routingNodes = getMutableRoutingNodes(tmpState);
// shuffle the unassigned nodes, just so we won't have things like poison failed shards
routingNodes.unassigned().shuffle();
上面介绍也说了,这个routingNodes解析了一次clusterState,并计算出当前的一些assigned,UNassigned,failed,stale 之类的所有的shards的集合,因此这个构造函数值得拜读一下,构造方法中有两点比较重要的东西需要留意,一是特别注意此时的routingTable 其实已经并没有包含Node3中的R0 这个shard了;二是留意一下在什么时候把一个shard标记为assignedShard。
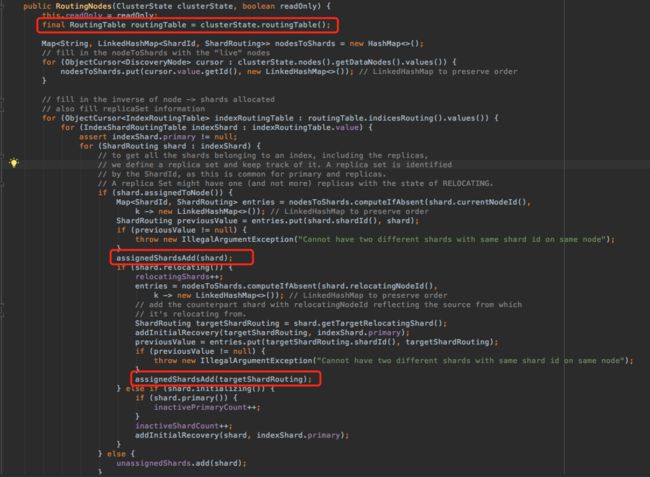
用我假设的例子来演绎的话就是:Node3的R0 不在assignedShardList 里。
最后就是最核心的方法routingNodes的failShard方法了,因为之前的疑点都在前面方法里找到结果了,所以带着这些结果来理解这个方法就比较好懂了,anyway这个方法从头到结尾都是比较重要的,所以这里也不吝啬全贴出来了
/**
* Applies the relevant logic to handle a cancelled or failed shard.
*
* Moves the shard to unassigned or completely removes the shard (if relocation target).
*
* - If shard is a primary, this also fails initializing replicas.
* - If shard is an active primary, this also promotes an active replica to primary (if such a replica exists).
* - If shard is a relocating primary, this also removes the primary relocation target shard.
* - If shard is a relocating replica, this promotes the replica relocation target to a full initializing replica, removing the
* relocation source information. This is possible as peer recovery is always done from the primary.
* - If shard is a (primary or replica) relocation target, this also clears the relocation information on the source shard.
*
*/
public void failShard(Logger logger, ShardRouting failedShard, UnassignedInfo unassignedInfo, IndexMetaData indexMetaData,
RoutingChangesObserver routingChangesObserver) {
ensureMutable();
assert failedShard.assignedToNode() : "only assigned shards can be failed";
assert indexMetaData.getIndex().equals(failedShard.index()) :
"shard failed for unknown index (shard entry: " + failedShard + ")";
assert getByAllocationId(failedShard.shardId(), failedShard.allocationId().getId()) == failedShard :
"shard routing to fail does not exist in routing table, expected: " + failedShard + " but was: " +
getByAllocationId(failedShard.shardId(), failedShard.allocationId().getId());
logger.debug("{} failing shard {} with unassigned info ({})", failedShard.shardId(), failedShard, unassignedInfo.shortSummary());
// if this is a primary, fail initializing replicas first (otherwise we move RoutingNodes into an inconsistent state)
if (failedShard.primary()) {
List assignedShards = assignedShards(failedShard.shardId());
if (assignedShards.isEmpty() == false) {
// copy list to prevent ConcurrentModificationException
for (ShardRouting routing : new ArrayList<>(assignedShards)) {
if (!routing.primary() && routing.initializing()) {
// re-resolve replica as earlier iteration could have changed source/target of replica relocation
ShardRouting replicaShard = getByAllocationId(routing.shardId(), routing.allocationId().getId());
assert replicaShard != null : "failed to re-resolve " + routing + " when failing replicas";
UnassignedInfo primaryFailedUnassignedInfo = new UnassignedInfo(UnassignedInfo.Reason.PRIMARY_FAILED,
"primary failed while replica initializing", null, 0, unassignedInfo.getUnassignedTimeInNanos(),
unassignedInfo.getUnassignedTimeInMillis(), false, AllocationStatus.NO_ATTEMPT);
failShard(logger, replicaShard, primaryFailedUnassignedInfo, indexMetaData, routingChangesObserver);
}
}
}
}
if (failedShard.relocating()) {
// find the shard that is initializing on the target node
ShardRouting targetShard = getByAllocationId(failedShard.shardId(), failedShard.allocationId().getRelocationId());
assert targetShard.isRelocationTargetOf(failedShard);
if (failedShard.primary()) {
logger.trace("{} is removed due to the failure/cancellation of the source shard", targetShard);
// cancel and remove target shard
remove(targetShard);
routingChangesObserver.shardFailed(targetShard, unassignedInfo);
} else {
logger.trace("{}, relocation source failed / cancelled, mark as initializing without relocation source", targetShard);
// promote to initializing shard without relocation source and ensure that removed relocation source
// is not added back as unassigned shard
removeRelocationSource(targetShard);
routingChangesObserver.relocationSourceRemoved(targetShard);
}
}
// fail actual shard
if (failedShard.initializing()) {
if (failedShard.relocatingNodeId() == null) {
if (failedShard.primary()) {
// promote active replica to primary if active replica exists (only the case for shadow replicas)
ShardRouting activeReplica = activeReplicaWithHighestVersion(failedShard.shardId());
if (activeReplica == null) {
moveToUnassigned(failedShard, unassignedInfo);
} else {
movePrimaryToUnassignedAndDemoteToReplica(failedShard, unassignedInfo);
promoteReplicaToPrimary(activeReplica, indexMetaData, routingChangesObserver);
}
} else {
// initializing shard that is not relocation target, just move to unassigned
moveToUnassigned(failedShard, unassignedInfo);
}
} else {
// The shard is a target of a relocating shard. In that case we only need to remove the target shard and cancel the source
// relocation. No shard is left unassigned
logger.trace("{} is a relocation target, resolving source to cancel relocation ({})", failedShard,
unassignedInfo.shortSummary());
ShardRouting sourceShard = getByAllocationId(failedShard.shardId(),
failedShard.allocationId().getRelocationId());
assert sourceShard.isRelocationSourceOf(failedShard);
logger.trace("{}, resolved source to [{}]. canceling relocation ... ({})", failedShard.shardId(), sourceShard,
unassignedInfo.shortSummary());
cancelRelocation(sourceShard);
remove(failedShard);
}
routingChangesObserver.shardFailed(failedShard, unassignedInfo);
} else {
assert failedShard.active();
if (failedShard.primary()) {
// promote active replica to primary if active replica exists
ShardRouting activeReplica = activeReplicaWithHighestVersion(failedShard.shardId());
if (activeReplica == null) {
moveToUnassigned(failedShard, unassignedInfo);
} else {
movePrimaryToUnassignedAndDemoteToReplica(failedShard, unassignedInfo);
promoteReplicaToPrimary(activeReplica, indexMetaData, routingChangesObserver);
}
} else {
assert failedShard.primary() == false;
if (failedShard.relocating()) {
remove(failedShard);
} else {
moveToUnassigned(failedShard, unassignedInfo);
}
}
routingChangesObserver.shardFailed(failedShard, unassignedInfo);
}
assert node(failedShard.currentNodeId()).getByShardId(failedShard.shardId()) == null : "failedShard " + failedShard +
" was matched but wasn't removed";
}
上面的几个if可以总结为:
- 如果fail的是一个primary shard,那么这个shardId的所有replica 都应该标记fail
- 如果fail 了一个primary 的shard,那么就会从replica中promote 一个replica晋升为primay
答案就是这里,刚刚说了,routingNodes里的assignedShards已经把stale的shards剔除出去了,所以这里只要随便找一个作为primary即可
- 如果fail 了一个正在relocating的primary的shard,那么会把relocating的目标也清理了(等于源挂了,目标也不要了)
- 如果fail 了一个正在relocating的replica,那么直接把目标值为initializing 就可以了,源直接删掉
这几点都很好理解,就不解释了。
那么本篇开头设计的例子和推论就基本演绎了一遍并成立了,不过多说一句就是,所谓的保证那些replica 具有最新的数据,这是ES的索引文档内部机理决定的,当ES索引一个doc时,primary 写入完成之后,需要等待quorum个replica完成写入才会认为这个doc已经写入,这个操作是并发异步操作,因此才会出现这个所谓的某些replica是最新的这种问题出现。
https://www.elastic.co/guide/en/elasticsearch/guide/current/distrib-write.html
全篇完,如有错漏欢迎指正和交流。