GAN--提升GAN训练的技巧汇总
翻译自:https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b
译者:刘威威
编辑:黄俊嘉
前 言
GAN模型相比较于其他网络一直受困于三个问题的掣肘:
1. 不收敛;模型训练不稳定,收敛的慢,甚至不收敛;
2. mode collapse; 生成器产生的结果模式较为单一;
3. 训练缓慢;出现这个原因大多是发生了梯度消失的问题;
本文主要以下几个方面入手,聚焦于解决以上三个问题的一些技巧:
改变损失函数,更换更好的优化目标
在损失函数中增加额外的惩罚机制或者正则手段
避免过拟合
更好的优化模型
使用监督学习
01
特征匹配
生成器试图生成最好的图像来欺骗鉴别器。 当两个网络不断对抗时,“最佳”图像会不断变化。 然而,优化可能变得过于贪婪,并使其成为永无止境的猫捉老鼠游戏。 这是模型未收敛且模式崩溃的情景之一。
特征匹配改变了生成器的损失函数,以最小化真实图像的特征与生成的图像之间的统计差异。 通常,我们测量其特征向量均值之间的L2距离。因此,特征匹配将目标从零和博弈扩展到真实图像中的匹配特征。 下面是特征匹配新的目标函数:
![]()
其中$f(x)$是一个从判别器D中提取出来的特征向量,如下图所示:
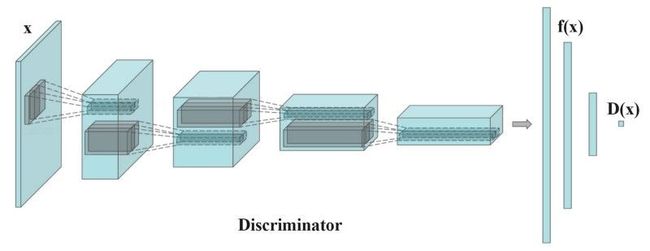
训练过程中,每个batch计算实际图像特征的平均值,每个batch都会有波动,可以减轻mode collapse,特征匹配它引入了随机性,使得鉴别器更难以过拟合。
当GAN的训练不稳定时,使用特征匹配是很有效的。
02
减小判别器的batch
出现mode collapse时,生成的图像看起来都差不多,为了缓解这个问题,我们将不同batch的实际图像和生成的图像分别送入判别器,并计算图像x与同一批次图像的相似度。 我们在鉴别器的一个密集层中附加相似度![]() ,以分类该图像是真实的还是生成的。
,以分类该图像是真实的还是生成的。
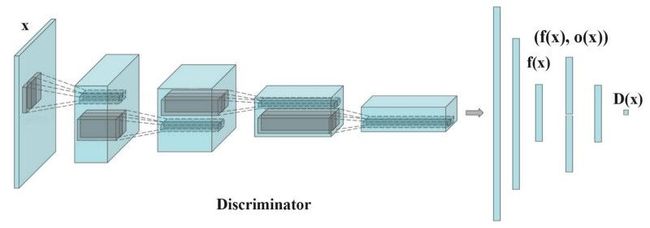
如果出现了mode collapse,则生成的图像的相似性增加。 如果模式崩溃,则鉴别器可以使用这个值来检测出生成的图像不够好进而给生成器更多的惩罚。
图像![]() 与同一批次中的其他图像之间的相似度
与同一批次中的其他图像之间的相似度![]() 由变换矩阵T计算。
由变换矩阵T计算。

在上图中,![]() 是输入的图像,
是输入的图像,![]() 是同一个batch里剩下的部分。使用变换阵T去转换特征
是同一个batch里剩下的部分。使用变换阵T去转换特征![]() 到
到![]() (维度B*C):
(维度B*C):
![]() ;
;
进而,我们可以使用L1-norm得出图像i和图像j之间的相似度![]() :
:![]() ;
;
图像![]() 和同一个batch里的图像的相似度
和同一个batch里的图像的相似度![]() 是:
是:
 以下是公式总览:
以下是公式总览:
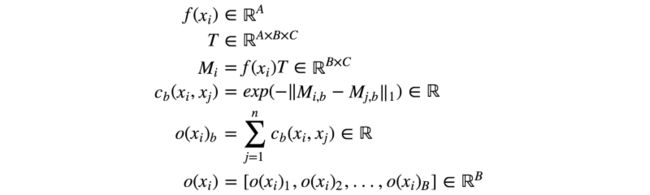
引自paper:Improved Techniques for Training GANs
Minibatch的判别方法能够非常快速地生成视觉上较好的样本,并且在这方面它比特征匹配更好用。
03
标签平滑
深度网络可能会发生过拟合。 例如,它使用很少的特征来对对象进行分类。 为了缓解这个问题,深度学习使用正则话和dropout来避免过拟合。
在GAN中,如果鉴别器依赖于一小组特征来检测真实图像,则生成器可以仅生成这些特征以仅利用鉴别器。 优化可能变得过于贪婪并且不会产生长期效益。 在GAN中,过拟合受到严重伤害。 为了避免这个问题,当任何真实图像的预测超过0.9(D(实际图像)> 0.9)时,我们会对鉴别器进行惩罚。 这是通过将目标标签值设置为0.9而不是1.0来完成的。 这是伪代码:
p = tf.placeholder(tf.float32, shape=[None, 10])
# Use 0.9 instead of 1.0.
feed_dict = { p: [[0, 0, 0, 0.9, 0, 0, 0, 0, 0, 0]] # Image with label "3"}
# logits_real_image is the logits calculated by
# the discriminator for real images.
d_real_loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=p, logits=logits_real_image)04
Historical averaging
此方法中,旨在对过去训练留下的t个参数求平均,以对当前模型的参数做正则。
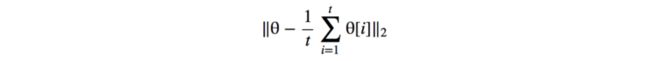
对于使用非凸目标函数的GAN来说,历史平均可以使模型绕平衡点停止并充当阻尼力以收敛模型。(有点类似二阶优化方法)
05
使用标签
许多数据集都带有样本对象类型的标签。 训练GAN已经很难了,因此,指导GAN训练的任何额外帮助都可以大大提高性能。 将标签添加为潜在空间z的一部分有助于GAN训练。 以下是CGAN中用于利用样本中标签的数据流。
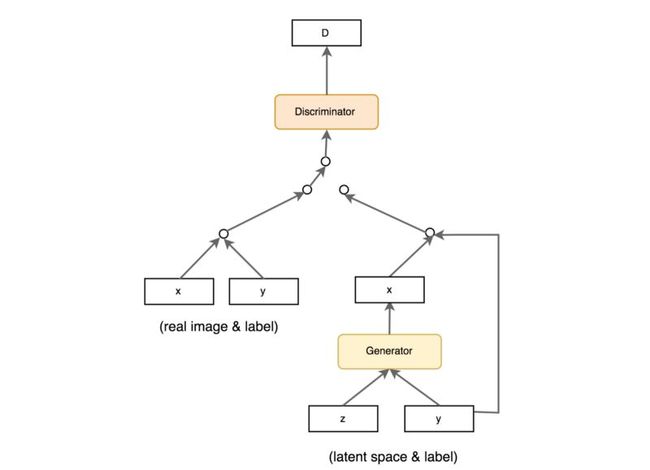
06
损失函数
研究员们提出了很多的损失函数,见下图:

我们决定不在本文中详细介绍这些损失函数,详细的解释可以去参考相应论文。
以下是某些数据集中的一些FID分数(衡量图像质量,值越小越好)。 这是一个参考点,但需要注意的是,对于哪些损失函数表现最佳还为时尚早。 实际上,目前还没有单一的损失函数在所有不同数据集中表现最佳,所以,做实验的时候不妨多试几个损失函数,不要看网上传什么损失函数好就用哪个。
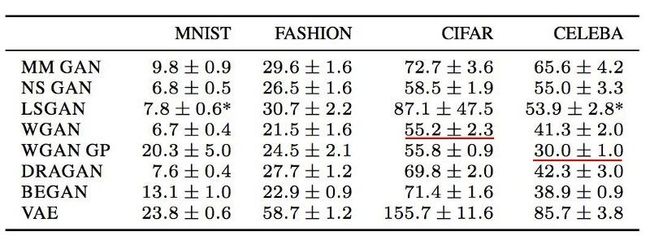
(MM GAN是原始论文中的GAN成本函数。NS GAN是解决同一篇论文中消失的渐变的替代损失函数。)
但是想训练好GAN,仍需要小心的去拟合和调参,在随意的更换损失函数之前,不妨先耐心地调调参。
07
一些小技巧
将图像像素值缩放在-1和1之间。使用tanh作为生成器的输出层
用高斯分布实验取样z
BN通常可以稳定训练
使用PixelShuffle和转置卷积进行上采样
避免最大化池用于下采样,使用带步长的卷积
Adam优化器通常比其他方法更好(在GAN中)
在将图像输入鉴别器之前,将噪声添加到实际图像和生成的图像中
GAN模型的动态尚未得到很好的理解。 所以一些提示只是建议,里程可能会有所不同。 例如,LSGAN报告称RMSProp在他们的实验中有更稳定的训练,所以,调参很重要。
08
Virtual batch normalization (VBN)
BN成为许多深度网络设计中的必备项。 BN的均值和方差来自当前的小批量。但是,它会在样本之间创建依赖关系,生成的图像不是彼此独立的。
![]()
下图的图像是训练失败的图像,也反映了在生成的图像显示同batch中的颜色色调相似。

最初,我们从随机分布中抽样z,为我们提供独立样本。 但是,BN产生的偏差超过了z的随机性。
虚拟批量标准化(VBN)在训练之前对参考批次进行采样。 在前向传递中,我们可以预先选择参考batch来计算BN的归一化参数(μ和σ)。 但是,由于我们在整个训练中使用相同的batch,因此有可能使用此参考batch发生过拟合。 为了缓解这种情况,我们可以将引用批处理与当前批处理相结合,以计算规范化参数。
09
随机种子(Random Seed)
用于初始化模型参数的随机种子影响GAN的性能。如下所示,测量GAN性能的FID分数在50次单独运行(训练)中有所不同。 但是范围相对较小,可能仅在稍后的微调中完成。
10
Batch Normalization
DGCAN强烈建议将BN添加到网络设计中。 BN的使用也成为许多深度网络模型的一般实践。 但是,会有例外。 下图演示了BN对不同数据集的影响。 y轴是FID得分越低越好。 正如WGAN-GP论文所建议的那样,BN最好不使用。 我们建议读者检查BN上使用的损失函数和相应的FID性能,并通过实验验证来设置。
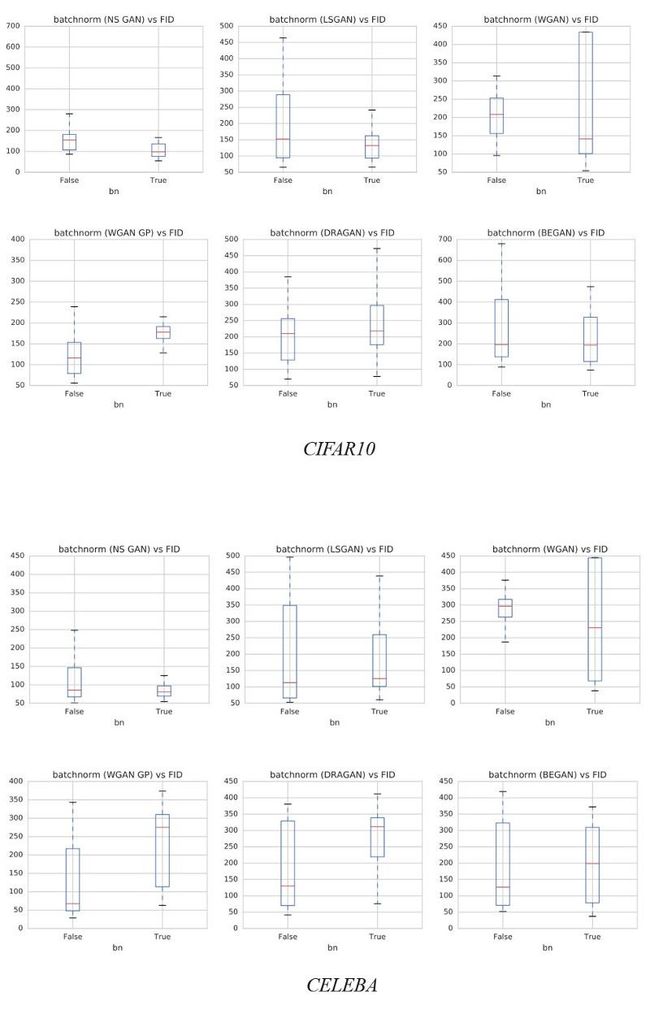
11
多重GAN
模式崩溃可能并不全是坏事。 当模式崩溃时,图像的某些区域质量通常会提高。 实际上,我们可能会为每种模式收集最佳模型,并使用它们来重建不同的图像模式(玄学调参)。

12
平衡生成器和判别器
判别器和生成器总是处博弈中以相互削弱。模式崩溃和梯度减小通常被解释为判别器和生成器之间的不平衡。我们可以通过关注平衡生成器和判别器之间的损耗来改进GAN。不幸的是,解决方案似乎难以捉摸。我们可以保持判别器和生成器上的梯度下降迭代次数之间的静态比率。即使这看起来很吸引人,但很多人怀疑它的好处。通常,我们保持一对一的比例。但是一些研究人员还测试了每个生成器更新的5个判别器迭代的比率。还提出了使用动态力学平衡两个网络。但直到最近几年,我们才对它有所了解。
另一方面,一些研究人员挑战平衡这些网络的可行性和可取性。一个训练有素的判别器无论如何都会给生成器提供高质量的反馈。而且,训练生成器总是赶上判别器并不容易。相反,我们可能会将注意力转向寻找在生成器性能不佳时不具有接近零梯度的损失函数。
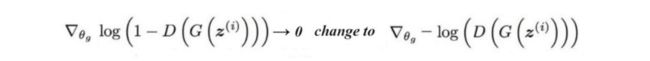
13
生成器、判别器的容量
判别器的模型通常比生成器更复杂(更多的权重和更多的层),良好的判别器提供高质量的信息。 在许多GAN应用中,我们可能遇到瓶颈,增加生成器容量(增加生成器的层数)显示没有质量改进。 在我们确定瓶颈并解决它们之前,增加生成器容量似乎并不是调参的优先考虑项。
14
进一步阅读
本文中,我们没有对某一具体方向做深入的探讨,只是给出了一个大概的方向,GAN的训练仍是一个遗留问题,需要诸位亲自探究。

END
往期回顾之作者刘威威
【1】免费使用谷歌GPU资源训练自己的深度模型
【2】手把手教你实现GAN半监督学习
【3】DeepMind探索AI医疗黑箱问题,眼科疾病诊断水平超人类专家
【4】Kaggle机器学习比赛前top2%成绩的技巧
【5】就怕你迷路!力荐!论文资源获取和AI论文阅读指导
机器学习算法工程师
一个用心的公众号

进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助