
欢迎Java工程师关注专栏
Java架构技术进阶
本专栏收录各种Java相关技术,面试题,以及学习感悟,心得!
随着微服务技术日趋成熟,越来越多的企业使用Spring Cloud构建微服务架构。Eureka作为Spring Cloud微服务架构中的注册中心,扮演着重要的角色。本文将从Spring Cloud源码角度出发,让大家能够了解到相关组件内部的运行机制,从而更好的回馈开发的流程和配置上,为用户提供更好的方案。
Spring Cloud提供了微服务架构中的众多组件,例如API网关、注册中心、负载均衡、熔断限流、服务追踪。下图是Spring官方给出的一个类似于Spring Cloud微服务框架的解决方案架构图。
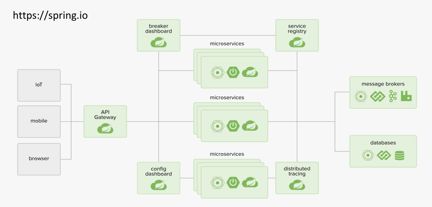
Spring Cloud Netflix Eureka
Spring Cloud里面包含众多组件,第一个需要介绍的组件就是Eureka。Eureka作为一个注册中心,其核心功能是保存注册信息,就像手机的电话簿一样,在电话簿中会保存着每一个人的联系方式。同时,Eureka会把保存的这些信息分享给每一个客户端,以便于客户端向服务器发起调用。所以会有一个注册、续约、取消和内部的剔除机制。
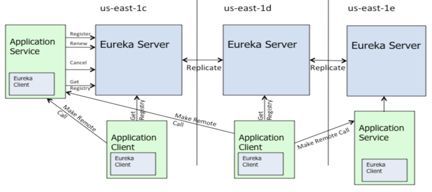
下图是Netflix Eureka Github官方给出的架构图,比较重要的部分是箭头的走向。从左向右看,最左边是Eureka Client,可以看到Eureka Client跟Eureka Server之间通信包括了注册事件、续约事件、取消事件,同时Eureka Client也会从Eureka Server当中获取到相关的注册信息,另外Server与Server之间存在复制的机制。
下图中介绍的是注册事件如何发生的。蓝色的小笑脸代表的是新Client启动之后,信息是如何保存到Eureka Server中的。同时,Eureka Server又做了哪些事情。可以看到,Eureka Server给前端提供了一个API,这个API是完成注册请求。首先,Eureka Server中保存信息的数据结构是双层MAP。当Client发起注册请求时,这个实例首先要做的事情是保存到内部Eureka中的数据结构。同时,Eureka Server当中会维护一个最近改变的队列,为什么会存在这样的队列?因为Eureka Client向Eureka Server发起同步时,通常有两种方式。一种方式是拉取全量的信息,每一个Client都想从Server中获取全量的信息,但并不是一次性获取完全量信息之后,信息传输的过程整个结束了。Eureka Client还会定期通过后台的定时任务,向Eureka Server获取增量的信息,而这些增量信息数据需要从Eureka Server当中维护的、最近改变的队列中获取。
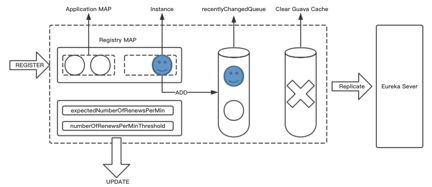
因此,当一个注册事件到来之后,除了会把信息保存到自身的数据结构中,同时还会把这些信息放置到最近改变的队列当中。
ExpectedNumberOfRenewsPerMin和NumberOfRenewsPerMinThreshold这两个属性是Eureka Server中十分重要的属性。因为Eureka Server中存在一个自我保护机制,在15分钟之内默认情况下,阈值低于85%将开启自我保护。当阈值高于85%时,系统会进行一系列的剔除操作,这个剔除指的是一个Client向Server发生注册之后,并没有按时完成续约功能。Server会认为这个远程的Client坏死,需要把它移除。根据什么来判断呢?就是根据上述两个属性来做阈值的参考。
同时,因为Eureka Server中维护着一个Cache,所以当一个信息来临时,在保存着最近队列的同时,系统会清空这个Guava Cache,也会把这个事件复制给远端其他相邻的Eureka Server。
上述注册过程只是一个单一的步骤,并不是完成一次注册后就能一次性解决所有问题。这个Client会定期的向Server发起同步,目的是为了向Server定期发出“我还活着,不要把我剔除”的信息。通常默认发送的频率是30秒一次,Eureka Client会持续向Eureka Server发起同步。关于同步的流程,大致上是根据用户的请求信息,在Eureka Server的数据结构中找到该次续约对应的Eureka Client,同时把Eureka Client对应的时间进行更新。从下图右侧的源代码可以看出,这种更新只是把对应的节点取出来,更新到对应的时间戳。同时,再把这个信息复制给相邻的Eureka Server节点。

当远程的服务确认停止,需要对其发送一次事件通知Eureka Server,把该Client从Eureka Server中剔除,对应的流程是怎样的呢?其实跟注册的逻辑大体相似,也是从双层的MAP当中找到对应的Client信息,同时把Client信息维护到最近改变的队列里面去。这个最近改变的队列中并不意味着只存在新增的,同时也存在删除的。因为删除和新增这两个过程从Eureka Server的角度来看,都是最近改变了的数据结构内部的一些信息。同时,因为原来Server的节点如果少了一个,必定会导致两个阈值的属性发生变化,所以也会去更新这两个阈值的属性,最后把信息复制给相邻的Eureka Server节点。
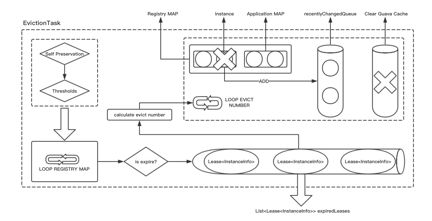
Eureka Server内部自身剔除的机制是什么?首先,上文中提到在Eureka Server中存在一个自我保护的概念,自我保护的概念可以理解成什么呢?假设开启了自我保护,如果Eureka Server没有收到Eureka Client,那并不意味着Eureka Client本身已经坏死了。可能是由于网络造成的问题,而没有收到部分更新请求。远端的Eureka Client还在良好的运行中。所以当以自我保护开启,同时会有一个阈值的判断,这个阈值的判断就相当于前面介绍的注册或Cancel机制,Eureka Server会去定时更新这两个阈值判断。
经过校验之后,会在整个内部数据结构,即保存的所有注册信息的处把实例都会去循环一遍,判断是否过期,每一个小圆圈代表的就是一个过期的实例,同时拿到这些实例之后,Eureka Server会再次计算这次应该剔除多少个服务。
这里面有一个问题,Eureka Server再计算出十个实例之后,是一次性剔掉,还是按照顺序一个一个剔掉?如何保证每一次剔掉的实例是公平的呢?Eureka Server通过洗牌算法,来保证每一次随机拿到的概率是相等的。从而把实例从数据结构当中剔除掉,同时放到最近的变更的队列,然后进行保存。这个Task是定时在Eureka Server后台运行的。
在上文的注册和取消里都提到了Cache,要把这个Cache清空。那么在Eureka Server中,Cache的实现机制是什么?Eureka Server本质上是有两层缓存机制的,这个设定也比较灵活,用户可以通过一个参数让使用者决定是否开启二级缓存。就是说我们可以开启二级缓存,也可以不开启二级缓存。
第一层就是第一级的缓存,本质上是一个Guava Cache,是存在过期时间的,这个过期时间的参数是可以设置的。二级缓存是一个Hashmap,本质上是没有过期实例时间的。其机制是:如果启用了二级缓存,所有的信息会先从二级缓存获取,如果从二级缓存获取不到,则会从一级缓存获取。如果一级缓存同样获取不到,由于Cache存在一个load机制,实现这个自定义的load之后,会出现Cache中获取不到数据及用户的自定义行为,因此在源码中的实现是,当一级缓存也获取不到信息时,会在保存信息最完整的数据结构中调取。

另外后台会启动另一项任务,即从一级缓存向二级缓存同步数据。为什么是从一级缓存向二级缓存同步,而不是二级缓存向一级缓存同步呢?是因为二级缓存的数据有可能会比一级缓存的数据要多。
下图是从Client向Eureka Server获取数据的整体逻辑。当Eureka Client启动时,需要从Eureka Server获取全量的信息,放置到Eureka Client本地。在信息同步的过程中必然会面临两个问题,第一个问题是增量同步还是全量同步?这取决于当时的实际情况,针对不同的现场状况所采取的同步方式是不一样的。当Eureka Client在完成启动时,第一次通常情况下进行的是全量的同步。如果增量同步失败,那么会去拉取进行全量的同步。在Eureka Server中会具有一个参数,表示是否在后台的log当中会看到增量与全量的区别。如果这个参数开启,那也会去拉取全量的数据。

增量信息获取的流程其实很简单,后台会有一个Task功能定期发送一次请求,从Eureka Server当中获取到增量的信息。这里需要注意的是,在上文中也提到过,增量同步失败,来获取全量。这个环节会出现一个问题,什么情况下认为增量同步失败呢?还以上图为例,图中展示了Eureka Client和Eureka Server的一致性hash校验。比如,用户当前的Eureka Server中注册信息实例有十个,十个Eureka Client都会在当前的Eureka Server信息当中。而这十个Eureka Client中可能会有七个是还在提供服务的,在没有剔除之前,另外三个实例已经坏死了,那么当前显示的状态是down。此时,Eureka Server会保持一个HashCode,这个HashCode的值就是拼接状态是up的个数以及状态是down的个数的SpringBuilder。
具体的流程过程是,当一个Eureka Client在启动时,首次获取全量,直接拿取全量信息保存到本地。当获取增量信息时,在Eureka Server中会出现一个参数,这个参数代表着是否开启二级缓存。如果Eureka Server这个参数代表开启了二级缓存,会从HashMap当中获取数据。如果获取不到数据会从一级缓存进行获取同时把这个数据同步到二级缓存并把结果返回到Eureka Client。如果一级缓存获取不到,则会从数据结构中获取。
同时后台会计算这次获取完数据的HashCode,也就是当前Eureka Server所有实例的HashCode值,然后作为一个返回结果,返回给Eureka Client。这个时候Eureka Client如果是第一次启动,那么本地的数据是空的。如果是增量的情况下,前期Eureka Client已经会存在存量的信息了。从Eureka Server获取数据后,本地的数据要完成一个合并的动作,合并完之后,拿合并的结果去按照相同的方法,这个方法就是Eureka Server的方法,去计算此时在Eureka Client本地的HashCode是多少。
但上述过程存在一个不严谨的地方,就是用户无法单纯通过实例的个数来判断此时Client保存的信息与Eureka Server保存的信息是否完全一致。因为在某些极端的情况下,这种判断是不严谨的。但从大概率的角度来讲,这种情况是没有问题的。一次可能同步不正确,可以通过发起多次来检验最终结果是否一致。Eureka Server的设计原则保证的是AP,而并不是CP,因此能够保证最终数据的一致性。
至此,Eureka的整个组件已经全部介绍完毕。简单概括一下,从Server的角度来说,包括注册、续约以及取消,内部还有剔除的机制。同时Eureka Client也会和Eureka Server同步信息,同步信息的时候可能会分为首次的全量以及每一次定时的增量信息。判断增量是否成功与失败呢,可以通过一个HashCode这个值,即通过所有实例的up和down状态的表述来判断是否同步成功。如果同步成功,等待下一次同步即可。如果同步不成功,则要进行全量的拉取。
Spring Cloud Netflix Ribbon
通过Eureka组件,用户能够获得的不仅仅是一个简单的服务,可能是相同服务的一个集群。用户需要在众多的服务中选取一个最优服务来发起资源调用,实现这个功能的组件,就是Spring Cloud Netflix Ribbon。Ribbon这个组件是客户端的负载均衡,从字面上看,Ribbon可以分为两部分,一部分是客户端,另一部分是负载均衡。
假设下图中的蓝色笑脸代表Ribbon,那么Ribbon如何工作?当Client发起一次request调用时,作为客户端的负载均衡,用户想要的是请求没有发送时就已经能够知道哪一个服务是最优的,从而在这个最优的基础上组装request调用。简单概括一下实际流程,相当于一个拦截机制,当request进入的时候,Ribbon的功能是拦同时拦截众多的Server,并在其中选取一个最优的,然后向它发起一次调用。
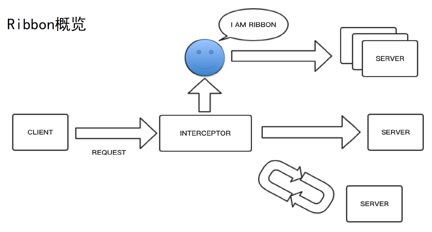
右下方的循环代表什么?有可能第一次调用失败,需要重试操作。当Client发起一次调用,在调用之前先将其拦截,从而从众多的Server当中选取一个Server,发起一次真正的调用。如果成功选取最优Server,则进入下一环节。如果不成功,可能需要经过多次重试,从而使它达到成功的目的。
第一个问题是如何进行拦截。这里就需要用到RestTemplate的特性。其实在使用Ribbon的时候,需要在RestTemplate上加一个注解,当容器在启动时,会先搜索所有在RestTemplate上打过注解的RestTemplate,这也意味着要找到所有将要实现Ribbon的这些RestTemplate,要把它抓取到。
接下来进入真正的拦截步骤,此时Ribbon将利用Spring的另外一个接口,当实现这个接口时,在容器中完成的某一个节点,Spring会自动去回调这个接口的方法。因为首先已经找到了所有要实现RestTemplate,把这个RestTemplate取出来,因为RestTemplate里面会有一个特性是一个intercepter,它会把当前所有的intercepter拿到,然后把这两个拦截器加入到现成的拦截器里面。
完成拦截之后,需要从众多的Server当中获取一个数据,这也是Ribbon的核心功能。如果将Ribbon比作一个人,这个人的作用是要从众多的Server当中选取一个在当前状况下它认为最优的Server。这个人的四肢就如同Ribbon的核心行为,即IPing、IRule、ServerListUpdater、ServerListFilter。要从众多的Server当中选取一个Server,先决条件是要存在Server,这些Server通常来源于以下两种。

第一种方式是静态的,可以通过硬编码进行配置, Ribbon将根据输入的Server数量从中选取一个发起一次调用。还有一种方式是结合上文中的Eureka,可以通过Eureka当中获取远程的Server。这是方式是动态的,因为有一个服务正在被启用。启用的这个服务就会注册到Eureka Server当中,同时Eureka Client会定期拿到这个最新的数据,而完成动态的功能。
选取最优Server的规则是什么?有些情况下当用户向Server发起真正调用时,想知道这个Server此时真正的状态是否良好。或者假设认为所有的Server是好的,也可以通过Eureka Server中获取的Client信息的状态是否是up来判断这个Server的好坏。另一种方式是真正的向Server发起Ping操作,通过Ping操作来查看Server是否存活。
Ribbon的处理过程分为两类,一类是普通的非重试需求,第二类是重试的需求。非重试的请求是已经在RestTemplate中加载进行拦截的功能,同时去创造具有了选取最优Server的行为的能力,选取到最优的Server完成调用。而在重试的情况下,选取一个Server,发起一次远程调用,如果成功会获得反馈,如果不成功就会根据自定义的操作和行为发起下一次调用。需要注意的是,Spring Cloud虽然用了原生组件,但所有的重试机制都是基于Spring Retry实现的,如果想要通过Ribbon重试这个功能,需要加入Spring Retry这个工具包来完成重试。

第一次重试和第二次重试的间隔需要做什么?是等待一段时间,还是立马发起调用?这些需要根据具体情况来解析,不同的自定义行为会带来不同的操作。这就是Spring Retry相关的一些接口,帮助开发者判断并确定每一阶段的自定义行为是什么。
总之,通过Ribbon这个组件来完成一次远端最优Server的选择过程,可以理解成首先需要怎么把它移植到客户端,在客户端没有发起请求之前,就要实现拦截。拦截到之后,选取众多的Server发起调用,调用如果成功,大功告成。如果失败,也可以通过重试来解决。
Spring Cloud Netflix Zuul
Spring Cloud Netflix Zuul可以理解为边缘服务,服务化的一个API网关。如下图所示,当请求进来时,会有前置、路由、后置的三种Filter类型。通过串型架构,最终找到要代理的那个服务并返回。
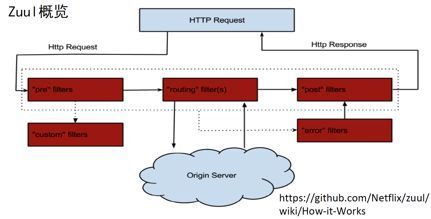
Spring Cloud Netflix Zuul内置了很多Filter,在启动时Spring会自动将这些Filter注入到当前的容器。
ZuulServlet和ZuulController是Zuul中比较重要的两个类。ZuulServlet本身就是一个Servlet。ZuulServlet主要工作是执行前置、路由、后置Filter。ZuulController主要工作是拦截请求,并将请求转发给ZuulServlet进行处理。
在定义Zuul的Filter时我们不仅可以在Filter中编写具体的业务逻辑同时也可以指定Filter的执行顺序,另外也可以指定是否执行该Filter。
Zuul的动态路由方式有两种,第一种方式是将路由规则维护在外部,我们一般利用DB+Redis。
另一种是在Edgware以及后续版本中,当远端服务启动的时候(Zuul本身也是Eureka Client)会获取到最新的服务列表,并利用最新服务列表更新现有的路由规则(完成动态路由的功能)。
更新路由具体逻辑参见下图

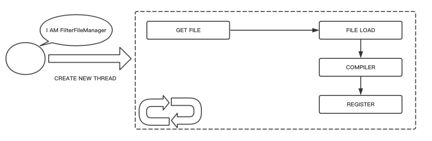
我们也可以使用Groovy编写Zuul的Filter,在Zuul的内部维护着一个定时任务,会扫描指定路径下的Groovy Filter文件,并进行加载。通过这种机制我们可以做到在不重启Zuul的情况下动态添加Filter。具体的逻辑如下
Spring Cloud Openfeign
Feign这个单词英文的含义是伪装,或者可以理解成虚假的,这个意思其实可以清晰地反映出这个组件本质的含义。在服务之间调用的时候,可能通过十行、二十行代码就能够完成一次调用。对于调用过程中涉及到的公共代码,有没有一种办法把它抽离出来,经过框架设计之后让使用变得更加简单?只需要定义接口,接口中定义方法,然后通过某种手段直接完成一次调用。所以这也是Feign的一个初衷,就是并不关心请求是怎样的,只为了让用户方便去使用HTTP调用的一个代理。
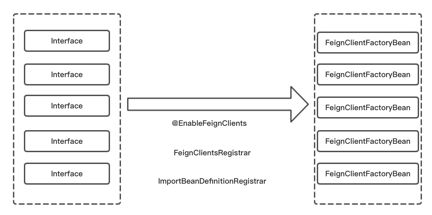
要使用Feign,首先要做的就是使用EnableFeignClients注解,并在对应的Interface上添加。FeignClient的注解。在Spring启动时会将带有FeignClient注解的Interface注入到Spring容器中。如下图所示
在注入Spring容器的同时会利用JAVA的动态代理机制,这种机制会在利用Interface发起真正调用时完成拦截,在拦截内部完成组装HTTP请求的操作。具体生成代理机制如下图所示

在使用Feign时我们可以开启Hystrix功能,通过Hystrix可以做到快速容错的功能。当使用Hystrix时我们需要指定fallback方法(容错方法)。此时调用过程被封装在一个HystriCommand中,具体机制如下图所示
