【case】并发环境下HashMap引起full gc排查
现象
最近上线一个需求,完成需求的过程对代码进行了一次重构。应用发布后半个小时左右,发现一个机器报警,load过高。登陆机器看CPU使用情况,发现load已经正常,看下CPU使用情况,发现有一个核跑满,其他CPU使用率很低。大概一个小时后,其他机器陆续报警,发现同样的问题,紧急回滚应用。
应用运行在16G内存的虚机上,整个JVM11G内存,其中新生代3G,CMS gc,JDK7。
第一反应是JVM可能在进行full gc,因为只有一个线程跑满,其他线程被JVM暂停了。先去应用日志看下应用运行情况,果然日志已经没有任何输出。jstat -gcutil查看JVM内存使用情况,发现Old区使用已经100%。
摘掉服务
考虑到full gc导致RT变得超长,去ateye摘掉应用注册的HSF服务,但是操作失败,整个JVM已经没有响应。
保留现场
jmap -F -dump:format=b,file=atw.bin 'jid'把整个堆dump到本地,dump失败,JVM已经僵死。
jmap -histo 'jid' > histo.log
保留histo内存快照成功。
jstack 'jid' > statck.log
JVM线程信息保存成功。
初步分析
首先看下JVM线程栈信息,看看下是否应用线程阻塞,一般情况下,如果大量线程阻塞,每个线程都持有一定量的内存,很可能导致内存吃紧,而这些阻塞的线程又没有处理完请求,占用的heap空间不能被minor gc回收掉,导致产生full gc,cat stack.log | grep atw | sort | uniq -c | sort -nr | head -10
结果如下(重新排版过):
177 at ...service.impl...searchInterProduct(AtwSearchServiceImpl.java:505)
104 at ...service.impl..searchOneWay(AtwSearchServiceImpl.java:260)
80 at ...service.impl.executor...execute(OneWayCommonAgentSearchExecutor.java:419)
70 at ...service.impl.executor...handleFlights(AbstractSearchExecutor.java:689)
47 at ...service.impl...searchOneWay(AtwSearchServiceImpl.java:257)
31 at ...service.impl.executor...getFlightInfoAndStock(AbstractSearchExecutor.java:1073)
30 at ...service.impl.executor...getFlightInfoAndStock(AbstractSearchExecutor.java:1087)
22 at ...util.stlog.FarePolicyCounter.addFail(FarePolicyCounter.java:249)
20 at ...service.impl.executor...execute(OneWayCommonAgentSearchExecutor.java:424)
20 at ...service.impl.executor...getAllFares(AbstractSearchExecutor.java:892)
com.taobao.trip.atw.service.impl.AtwSearchServiceImpl.searchInterProduct(AtwSearchServiceImpl.java:505),一共177个,小于HSF线程数,属于正常,其他线程数量也在正常范围内。线程的锁和其他的信息也未发现异常。
接下来看下histo.log:
num #instances #bytes class name
----------------------------------------------
1: 204258 4368429800 [B
2: 6812683 926524888 com.taobao.trip.atw.domain.AtwInterFareDO
3: 22639343 724458976 java.util.HashMap$Entry
4: 22304135 538457776 [S
5: 21614962 518759088 java.lang.Long
6: 13867918 443773376 com.taobao.trip.atw.util.LongReferenceConcurrentHashMap$HashEntry
7: 6812439 326997072 com.taobao.trip.atw.domain.AtwInterFareSegmentDO
8: 421442 211696296 [J
9: 557827 199825568 [Ljava.util.HashMap$Entry;
10: 6812439 163498536 [Lcom.taobao.trip.atw.domain.AtwInterFareSegmentDO;初步猜测可能本次上线代码还有new byte[]的地方,即查看代码,发现本次新增功能没有这样的代码。而且整个应用的代码也无可疑地方产生byte数组。
继续分析可能是依赖的二方或者三方jar包引起,重新申请分支,提发布单,查看发布包变化:

通过对比发现,本次发布涉及jar包变更很小,而且无三方包变更,只有内部包发生变化。
对变化的包进行分析没有找到new byte[]地方。
继续分析histo.log,找打一台线上正常机器,生成histo,用故障机器数据减去正常值,得到差值如下(top 10):
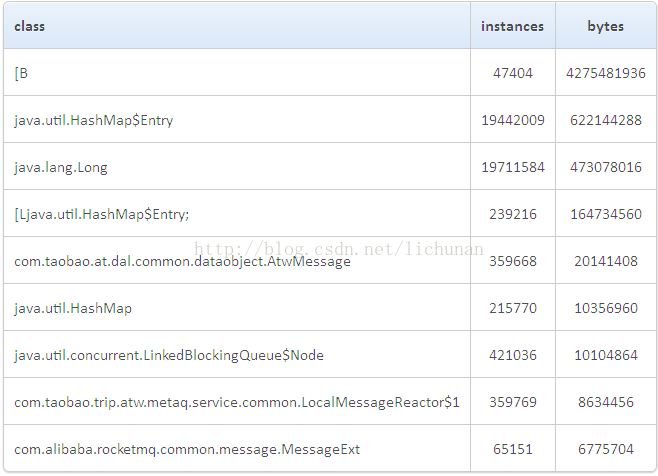
除了byte[]外,java.util.HashMap$Entry比正常机器多2kw,查看代码也没有明显证据能解释HashMap和byte[]同时增大的场景。
至此,分析思路阻塞,需要找到新的线索。
通过GC日志找到新线索
通过上面的分析,已经找到现象:应用出现了full gc,而且伴随大量byte[]和java.util.HashMap$Entry不能回收。然而,full gc最直接的产物gc.log还没有被挖掘。根据full gc时间点,发现新线索(重新排版过):)
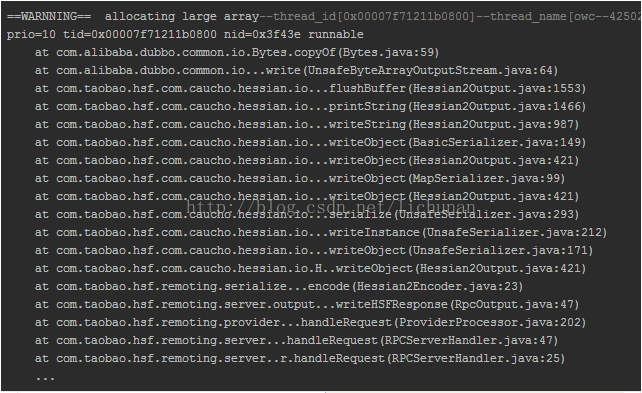
阿里定制的JVM增加了许多自己的新特性,其中一个就是在full gc不能回收的情况下,会把当前分配最大内存的线程信息和分配的内存信息打印出来!
==WARNNING== allocating large array–thread_id[0x00007f71211b0800]–thread_name[owc–425027705]–array_size[2132509912 bytes]–array_length[2132509891 elememts]线程owc--425027705,这是一个应用自己处理HSF请求的线程,它在分配一个巨大的数据组!通过gc日志的堆栈信息发现当前这个线程正在处理byte[]的拷贝:
at com.alibaba.dubbo.common.io.Bytes.copyOf(Bytes.java:59)至此找到了byte[]产生的原因,还有java.util.HashMap$Entry未解决。
根据线程名字owc--425027705去JVM的线程日志查找信息,发现owc--425027705是处理请求的主线程,下面有四个子线程都在处理这样的堆栈:
"owc--425027705-344" daemon prio=10 tid=0x00007f710278f800 nid=0x3f414 runnable [0x0000000051906000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.getEntry(HashMap.java:469)
at java.util.HashMap.get(HashMap.java:421)
at com.taobao.trip.atw.result.impl.DefaultPriceMergerOW.processHeightQuality(DefaultPriceMergerOW.java:327)
at com.taobao.trip.atw.result.impl.DefaultPriceMergerOW.extendedProductProcess(DefaultPriceMergerOW.java:179)
at com.taobao.trip.atw.result.impl.DefaultPriceMergerOW.mergeOneWay(DefaultPriceMergerOW.java:137)
at com.taobao.trip.atw.result.PriceMergerProxy.mergeOneWay(PriceMergerProxy.java:184)
...
HashMap多线程下成死循环原因
简短的说,多线程下对HashMap的put操作,会导致内部的Entry链表形成环形数据结构。
首先,put操作会检查容量是否充足,如果不足,会resize内部数组。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}问题就在于resize内部会遍历Entry的链表:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}这样的代码在多线程情况下,会出现环。
对于成环的Map,get遍历Entry链表时会导致死循环:
final Entry getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} 处理逻辑
主线程收到请求后,会分配4个子线程去计算结果,然后由主线程去完成对结果的合并。如果子线程处理失败或者超时,那么这个子线程的结果会被丢弃,不会被合并。从日志上看,4个子线程的处理都已经超时,但是由于HashMap并发操作造成死循环,4个子线程仍然在运行,主线程丢弃了子线程的结果,那数量量应该非常小才对,为何会产生如此大的byte[]?
追根溯源,从主线程分配任务找到了端倪。4个子线程处理计算的结果对象都是从主线程拷贝过来的:
BeanUtils.copyProperties(main, rsp);private MapMap> agentItemGroup;
public MapMap> getAgentItemGroup() {
if (agentItemGroup == null) {
agentItemGroup = new HashMapMap>();
}
return agentItemGroup;
}
public void setAgentItemGroup(MapMap> agentItemGroup) {
this.agentItemGroup = agentItemGroup;
} agentItemGroup的get方法会判断是否null,如果是的话,会生成一个新的map。
在org.springframework.beans.BeanUtils#copyProperties(java.lang.Object, java.lang.Object)方法中,对象属性的赋值会调用get/set方法,(参考:org.springframework.beans.BeanUtils#copyProperties(java.lang.Object, java.lang.Object, java.lang.Class, java.lang.String[]))这样就导致4个子线程用的map跟主线程是同一个map,而且就算子线程的结果被放弃了,主线程的map已经被搞坏。
com.taobao.hsf.com.caucho.hessian.io.MapSerializer.writeObject(MapSerializer.java:99)
HSF在对Map的序列化时候,对遍历Map,进行序列化:
public void writeObject(Object obj, AbstractHessianOutput out) throws IOException {
if(!out.addRef(obj)) {
Map map = (Map)obj;
Class cl = obj.getClass();
if(!cl.equals(HashMap.class) && this._isSendJavaType && obj instanceof Serializable) {
out.writeMapBegin(obj.getClass().getName());
} else {
out.writeMapBegin((String)null);
}
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Entry entry = (Entry)iter.next();
out.writeObject(entry.getKey());
out.writeObject(entry.getValue());
}
out.writeMapEnd();
}
}
由于主线程的map已经成环形数据结构,遍历的迭代器会死循环执行。
至此,full gc现象全部排查完毕,解决方案,一行代码到搞定:
BeanUtils.copyProperties(main, rsp);
rsp.setAgentItemGroup(new HashMapMap>());
总结
并发环境下被HashMap坑不止一次,很多时候,写代码没有考虑并发场景,熟知写的代码已经是在并发环境运行了。这样就酿成大错,其实后来想想,HashMap也可以做一下改进,get中如果循环超过size次了,抛出个异常,也不会导致死循环和full gc了 :)
但这并不能根治问题,写代码还是要多想想,加强reivew!