利用MyCat的数据切分搭建切片数据库
一、Mycat的目的
数据切分,数据切分,数据切分重要的事情讲三遍!
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果,而我们的应用在操作时可以忽略数据在哪个服务器上,我们的应用只需要和mycat交互即可。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
二、解决方法、途径
先来看看其官方权威指南上的一个图片,用图最能阐述一个软件的中心思想,也最直接。

一张表的数据切分存储在不同的物理数据库中,那么第一步要确定的是如何切分,如何知道那个物理数据库存了那些数据?当然不能乱切分,必须有一定的规则,这个规则必须有规律可寻的。
假如我们先人为把所有省份为wuhan(武汉是湖北省的省会,不是省)的订单都存放在DB1@Mysql1物理数据库上,把所有省份为sh的订单都存放在DB2@Mysql2物理数据库上。现在有一个SQL说我要wuhan省的所有订单,你现在是否已经知道要去DB1@Mysql1去拿数据呢?
Mycat实现也是如此,在这个图片中间就是Mycat中间件,在这你可以简单把它理解成为一个伪装的中间数据库(实质不存储任何数据),它负责接收前段所有应用链接到这个伪装数据库的SQL,根据表的配置获取分片规则(rule)把存储在真是数据库内的数据读出,并且返回给应用,当然还有对应的新增(I)、修改(U)、删除(D)操作到真正的分片数据库。
那么图中的SQL:select * from Orders where prov=’wuhan’,prov列字段就是分片规则,在这个例子可以简单理解为枚举类型:所prov列字段为‘wuhan’和‘bi’的它们的数据都去DB1@Mysql1物理机上操作,所prov列字段为‘sh’的数据都去DB2@Mysql2物理机上去操作.
三、几个重要概念和对应文件
从上面的我们知道了三个主要的名词分别是:表、分片规则、数据库物理机。接下看看Mycat如何处理这几个概念的关系。
1.分片规则(rule)
一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
分片规则的基础配置都在 rule.xml文件内,这些分片规则都必须应用到一个表上。
2. 节点主机(dataHost)
数据库实例,数据库运行的地方。
3.分片节点(dataNode)
在节点主机和表之间一个概念,其官方解释:数据节点,也就是我们通常说所的数据分片。
4. 逻辑表(table)、
所有需要拆分的表。这里记录了表、分片节点和分片规则的关系。
至此,所有数据切分的逻辑关系都已经很明确了,见图
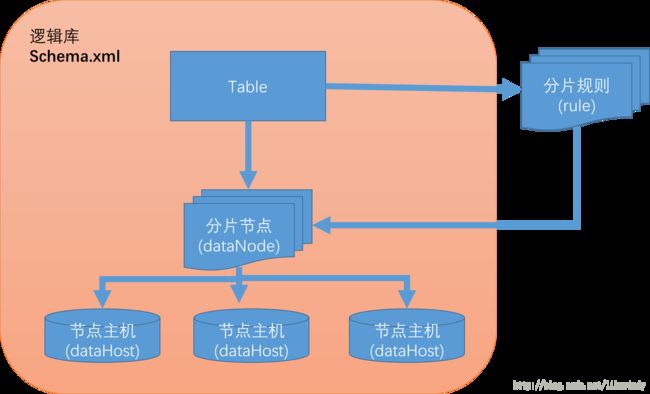
这样就可以就知道了一个表有那些分片节点,分片的规则是什么,根据分片规则返回唯一的分片节点索引,再根据分片节点找到唯一的节点主机(物理机)。
四、实践部署
(1)创建数据库
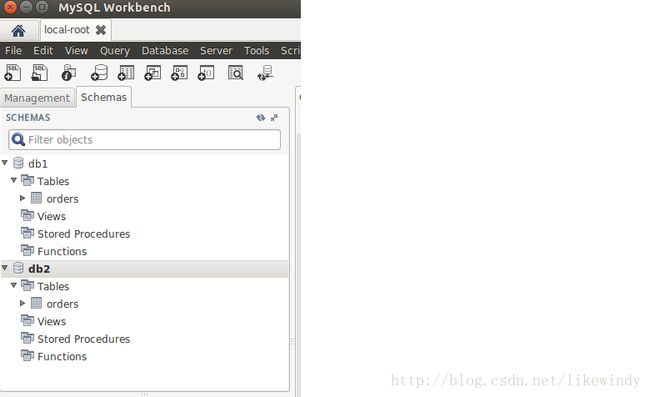
在这里我们在mysql数据库下建立两个数据库,分别是db1和db2,在每个数据库下都有orders数据库表。
CREATE TABLE `orders` (
`prov` varchar(20) NOT NULL,
PRIMARY KEY (`prov`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
(2)配置文件rule.xml
<tableRule name="split_by_prov">
<rule>
<columns>provcolumns>
<algorithm>plit_by_prov_funcalgorithm>
rule>
tableRule>
<function name="plit_by_prov_func" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">plit_by_prov.txtproperty>
<property name="type">1property>
<property name="defaultNode">0property>
function>这里根据表的prov列进行上图省份的枚举,其配置都在plit_by_prov.txt中,
wuhan=0
sh=1
bi=0
sx=1(3)配置文件schema.xml
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="orders" dataNode="dn1,dn2" rule="split_by_prov" />
schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost2" database="db2" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="user"
password="user">
writeHost>
dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="user"
password="user">
writeHost>
dataHost>(4) 配置文件server.xml
其它默认
name="user">
<property name="password">userproperty>
<property name="schemas">TESTDBproperty>
(5) 启动Mycat
./mycat start (6)使用Mycat
使用mysql客户端建立与Mycat的链接,见图片
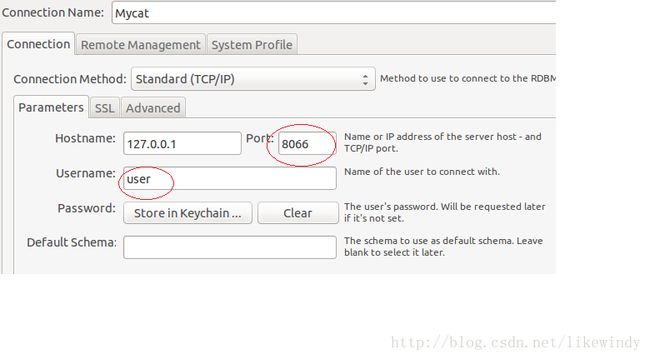
链接好后,执行以下语句
INSERT INTO orders (`prov`) VALUES ('wuhan');
INSERT INTO orders (`prov`) VALUES ('bi');
INSERT INTO orders (`prov`) VALUES ('sh');
INSERT INTO orders (`prov`) VALUES ('sx');
INSERT INTO orders (`prov`) VALUES ('bbb');
(7)验证数据存储
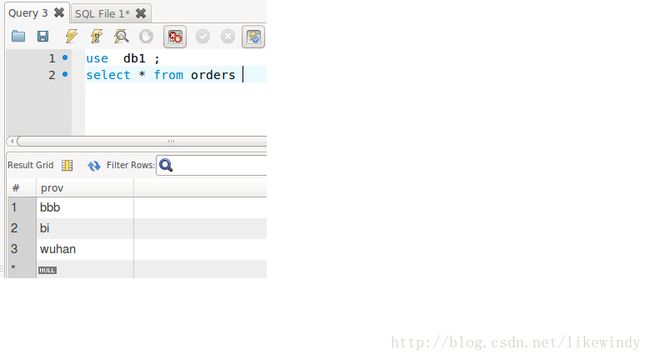
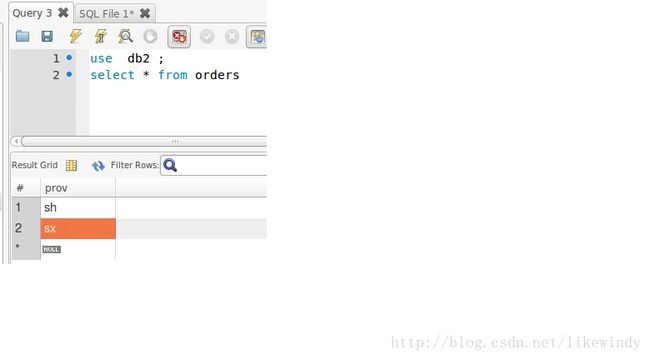
如图所示,所有数据都按照plit_by_prov.txt文件中的配置进行了存储,把wuhan和bi的都储在了db1中,把sh和sx的存储到了db2中,其中bbb在文件中没有配置,其按照分片函数的默认设置(defaultNode)分配到了db1中。
五、总结
本文在这里只是简单介绍了数据在分片的情况下的简单原理,其中间件还有很复杂情况下的各种处理,具体可以参考其权威指南(文中有些与新版本有出入)。
写的较仓促,若有不正确之处,欢迎指正。
其官方网站:Mycat
Mycat权威指南 :Mycat权威指南