STM32-基于汇编来分析延时
STM32-基于汇编来分析延时
上一篇文章写了一个延时函数,是这样的:
void Delay(uint32_t nCount)
{
for(; nCount != 0; nCount--);
}
为了延时1秒,设置了一个值:1600000。
为什么取这样一个值,这是我实测出来的一个值,是通过多次累计闪灯次数,对应电脑时间,计算出来的。
看见这个值之后,我有一个推测:
1.6M=8M/5
我没有使用外部晶振HSE,使用了默认的内部晶振HSI,主频为8M。
所以,可能这个延时函数循环一次所需要的机器周期数就是5!
怎么验证?
可以看下汇编代码来进行分析。
具体操作步骤:
在成功编译程序后,点击工具栏上一个红色的"D",进入调试状态,再把鼠标点到c代码处,右键查看汇编代码,就可以看到所有c代码编译后的汇编代码了。
延时函数的汇编是这样的:
53: for(; nCount != 0; nCount--);
0x08000206 E000 B 0x0800020A
0x08000208 1E40 SUBS r0,r0,#1
0x0800020A 2800 CMP r0,#0x00
0x0800020C D1FC BNE 0x08000208
可以看到有4条汇编指令:
B,跳转
SUBS,减
CMP,比较
BNE,根据标志跳转
大体理解,就是这样:进入循环后,先跳转去进行比较。比较后,查看比较结果,若不相等,则跳转去执行减操作。
对于循环次数很多的情况,可以忽略第一次的跳转,所以一般情况下的循环一次,就是执行3条指令:
0x08000208 1E40 SUBS r0,r0,#1
0x0800020A 2800 CMP r0,#0x00
0x0800020C D1FC BNE 0x08000208
3条指令,5个机器周期,能对应上么?
我上网查了一下,大概的结论是:
stm32 属于ARM ,ARM都是精简指令集,大部分的指令(除STM、LDM、BNE等外)都是单周期指令。
对于跳转指令,需要增加两个指令周期。
按这种方式来估算:
SUBS,1
CMP,1
BNE,3
则 1+1+3=5 ,应该是符合的。
但是我心里不太踏实,毕竟没有谁明确说哪个指令是几个周期,这中间还是有部分猜测的。是否有更靠谱的方式呢?
然后又找到一个好方法:
具体步骤参见:
https://blog.csdn.net/qq_41092963/article/details/82759097
大概说下步骤:
进keil的调试模式,单步调试,记录时间。
查看时间:Logic Analyzer窗口
汇编代码:Disassembly窗口
另外,还可以开一个Watch窗口,查看我们关心的变量值。
其样式见下图:
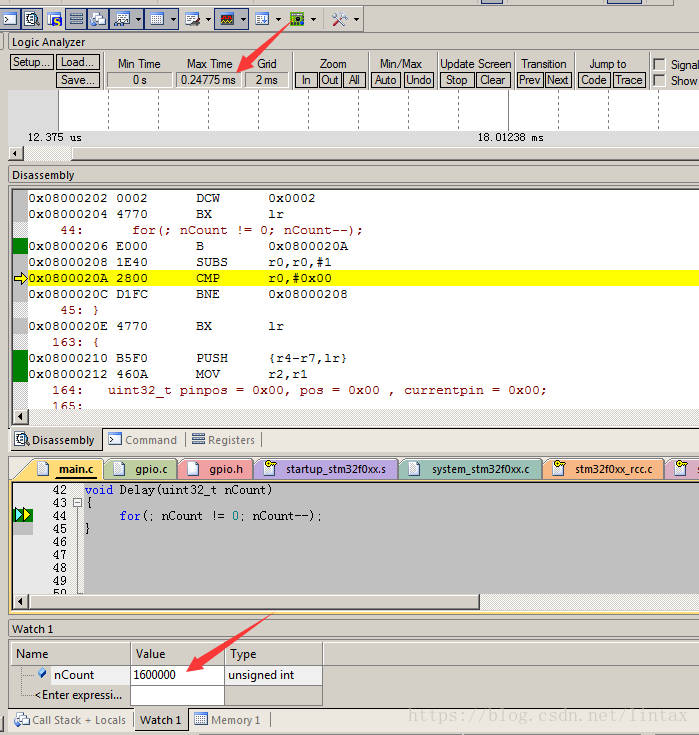
通过几次单步操作,记录下时间,然后我们可以列出一个表来:
| 累计(ns) | 指令耗时(ns) | |
| 初始 | 247750 | |
| CMP | 247875 | 125 |
| BNE | 248250 | 375 |
| SUBS | 248375 | 125 |
125ns,一个机器周期,即频率的倒数:1/8M,完全吻合。
这样,就确实验证了之前的猜测:
SUBS,1个机器周期(125ns)
CMP,1个机器周期(125ns)
BNE,3个机器周期(375ns)
这样,我们就可以从微观的循环周期向宏观的时间进行计算了:
循环一次所需机器周期数: 1+1+3=5 。
5个机器周期,耗时就是125ns*5=625ns
循环1.6M次的耗时:625ns*1600000=625*1.6ms=1000ms=1s
如此,心里就踏实了。
如果试试不同的延时函数的写法呢?
写成while循环,结果会怎样呢?
看看汇编,基本上是一样的:
0x080012D8 E000 B 0x080012DC
0x080012DA 1E40 SUBS r0,r0,#1
368: while(TimeDelay > 0){
369: TimeDelay--;
370: }
0x080012DC 2800 CMP r0,#0x00
0x080012DE D1FC BNE 0x080012DA
也是这样3个指令:SUBS,CMP,BNE。还是5个机器周期,没有问题。
如果选择不一样的编译方式呢?
之前使用的是o0优化,现在使用o3优化(Options for Target --> C/C++ -->Optimization),看看:
42: void Delay(uint32_t nCount)
43: {
0x0800048C 4C03 LDR r4,[pc,#12] ; @0x0800049C
0x0800048E 4620 MOV r0,r4
0x08000490 1E40 SUBS r0,r0,#1
44: for(; nCount != 0; nCount--);
0x08000492 D1FD BNE 0x08000490
主循环中只有2个指令了:SUBS,BNE。居然只有4个机器周期了!
现在来推测一下,需要循环多少次:
4*125*n=1000,000,000ns
n=2000,000
来放心的验证吧!
对比上面两种循环的差异,就是少了一个CMP指令。
可是,这样也有点奇怪吧,难道,cmp指令,是可有可无的吗?
这里需要理解下BNE指令。
BNE指令,是个条件跳转,即:是“不相等(或不为0)跳转指令”。如果不为0就跳转到后面指定的地址,继续执行。
而“不相等(或不为0)”,是什么不相等,什么不为0?其实它判断的是CPSR中的 Z 标记。
具体关于 Z 标记怎么设置的?那就依赖于上一个执行指令了。
再看上一条指令,两种优化模式下编译的结果不同,分别是CMP与SUBS。
CMP比较指令,用于把一个寄存器的内容和另一个寄存器的内容或一个立即数进行比较,同时更新CPSR中条件标志位的值。
对于减法,本来有一个SUB。而SUBS的差异,就是多了一个S,它的作用就是会根据执行结果来更新CPSR中的 N、Z、C 和 V 标记。
简单总结一下,BNE的判断依赖于Z标志,而CMP与SUBS会影响标志位,具体是如何影响的,我也不想再深入研究了,大体了解到这里,基本能满足我的好奇心了。
再补充一句,就是关于BNE指令的耗时。
前面我们知道,跳转时它的耗时是3个机器周期。后面我又测试了一下,若不跳转,例如是最后一次比较,结果恰好为0,则顺序往下执行,此时,BNE指令的耗时是1个机器周期。
可见,汇编里面的内容是很深奥的,所幸,我不需要花太多时间去研究,在此,只是大体了解下,解解几个小疑惑即可。