机器学习的学习曲线和验证曲线
最近在复盘优达学城的机器学习项目, 重新写了一下波斯顿放假预测的项目,除了模型的选择及网格搜索进行选择参数的相关知识外,还着重复习了关于学习曲线和复杂度曲线(验证曲线)
首先学习曲线和复杂度曲线(验证曲线)的区别,学习曲线是指在参数值确定的情况下,训练集和验证集的得分情况的对比,复杂度曲线(验证集曲线)是展示某个参数在取不同值时候,训练集与测试集得分情况的对比。
学习曲线的X轴是数据的数量,y轴是得分;复杂度曲线(验证曲线)的x轴是一个参数的值:比如max_depth(1,2,3,4,5,6,7,8,9,10),y轴是训练集和测试集在各个参数取值情况下的得分
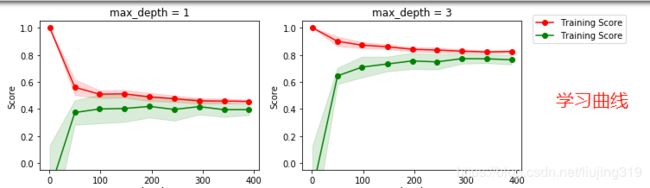
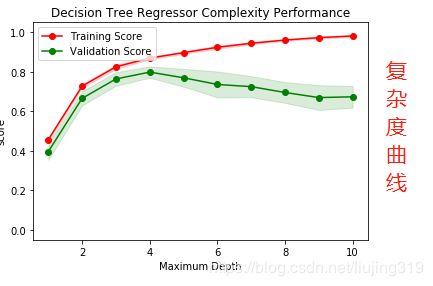
上面两张图分别是学习曲线和复杂度曲线
下面来说一下学习曲线或者验证曲线的数据集合的划分
1 ShuffleSplit 划分
上面的两个图中就是用ShuffleSplit 方式对数据集合进行划分的,代码如下:
cv = ShuffleSplit(features.shape[0], n_iter = 10, test_size = 0.2, random_state = 0)
train_sizes = np.rint(np.linspace(1, data.shape[0]*0.8 - 1, 9)).astype(int)
train_sizes, train_score, test_score = curves.learning_curve(
XGBRegressor(), X, y, cv=cv, train_sizes=train_sizes,scoring =score_fun
)
train_score_mean = np.mean(train_score,axis=1)
strain_score_std = np.std(train_score)
test_score_mean = np.mean(test_score,axis=1)
test_score_stu = np.stu(train_score,axis=1)在学习曲线函数中,通过cv 参数来设置划分的数据集,有几种方式:
(1)如上边代码,cv 是按照某种方式划分好的数据集
(2)cv=10,这种cv 是数字格式,是直接采用n-fold 的交叉检验的方式进行,直接设置n的值即可
(3)自己手动划分
#数据集合中有490条数据 index 是从0-489
train_index = np.arange(0,391)
test_index = np.arange(391,489)
#构建cv 集合
test_cv = [[train_index,test_index]]
#学习曲线 cv参数传入test_cv
sizes,train_scores,test_scores = curves.learning_curve(regressor,features,prices,cv=test_cv,train_sizes=train_sizes)
下面看下学习曲线的画法,代码如下:
sizes,train_scores,test_scores = curves.learning_curve(regressor,features,prices,cv=cv,train_sizes=train_sizes)
train_std = np.std(train_scores, axis = 1)
train_mean = np.mean(train_scores, axis = 1)
test_std = np.std(test_scores, axis = 1)
test_mean = np.mean(test_scores, axis = 1)
depth = 4
ax = fig.add_subplot(2,2,1)
ax.plot(sizes, train_mean, 'o-', color = 'r', label = 'Training Score')
ax.plot(sizes, test_mean, 'o-', color = 'g', label = 'Training Score')
ax.fill_between(sizes, train_mean - train_std,train_mean + train_std, alpha = 0.15, color = 'r')
ax.fill_between(sizes, test_mean - test_std, test_mean + test_std, alpha = 0.15, color = 'g')
ax.set_ylabel('Score')
ax.set_title('max_depth = %s'%(depth))
ax.set_ylim([-0.05, 1.05])
来看下这三种划分方式的学习曲线情况:
(1)shuffleSplit 划分:cv=ShuffleSplit(.......) cv=cv,对于这个数据集 很适合

(2) cv=10 交叉验证 n-fold 划分方式
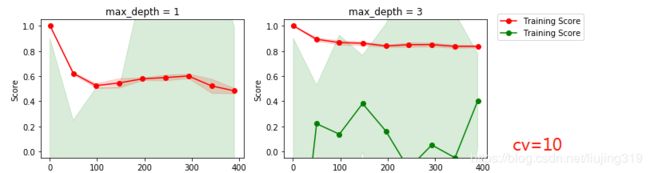
可以看出学习曲线变化很大
(3) 手动划分 test_cv=[[train_index,test_index]] ,cv=test_cv

由此可以看出,对于同一个数据集,划分的方式不同,其验证曲线会有很大差别 。