redis cluster介绍
redis从3.0开始支持集群功能。redis集群采用无中心节点方式实现,无需proxy代理,客户端直接与redis集群的每个节点连接,根据同样的hash算法计算出key对应的slot,然后直接在slot对应的redisj节点上执行命令。在redis看来,响应时间是最苛刻的条件,增加一层带来的开销是redis不能接受的。因此,redis实现了客户端对节点的直接访问,为了去中心化,节点之间通过gossip协议交换互相的状态,以及探测新加入的节点信息。redis集群支持动态加入节点,动态迁移slot,以及自动故障转移。
数据sharding
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个节点, 其中:
- 节点 A 负责处理 0 号至 5500 号哈希槽。
- 节点 B 负责处理 5501 号至 11000 号哈希槽。
- 节点 C 负责处理 11001 号至 16384 号哈希槽。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
- 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
集群架构

redis cluster是一个去中心化的集群,每个节点都会跟其他节点保持连接,用来交换彼此的信息。节点组成集群的方式使用cluster meet命令,meet命令可以让两个节点相互握手,然后通过gossip协议交换信息。如果一个节点r1在集群中,新节点r4加入的时候与r1节点握手,r1节点会把集群内的其他节点信息通过gossip协议发送给r4,r4会一一与这些节点完成握手,从而加入到集群中。
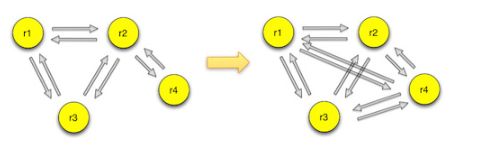
节点在启动的时候会生成一个全局的标识符,并持久化到配置文件,在节点与其他节点握手后,这些信息也都持久化下来。节点与其他节点通信,标识符是它唯一的标识,而不是IP、PORT地址。如果一个节点移动位置导致IP、PORT地址发生变更,集群内的其他节点能把该节点的IP、PORT地址纠正过来。
集群数据以数据分布表的方式保存在各个slot上。集群只有在16384个slot都有对应的节点才能正常工作。

slot可以动态的分配、删除和迁移。每个节点会保存一份数据分布表,节点会将自己的slot信息发送给其他节点,发送的方式使用一个unsigned char的数组,数组长度为16384/8。每个bit标识为0或者1来标识某个slot是否是它负责的。
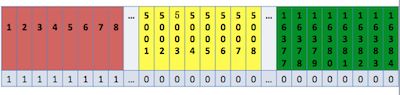
由于节点间不停的在传递数据分布表,所以为了节省带宽,redis选择了只传递自己的分布数据。但这样的方式也会带来管理方面的麻烦,如果一个节点删除了自己负责的某个slot,这样该节点传递给其他节点数据分布表的slot标识为0,而redis采用了bitmapTestBit方法,只处理slot为1的节点,而并未把每个slot与收到的数据分布表对比,从而产生了节点间数据分布表视图的不一致。这种问题目前只能通过使用者来避免。
数据访问
客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如“get key”,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端。客户端可以去该节点执行命令。目前客户端有两种做法获取数据分布表:
- 一种就是客户端每次根据返回的MOVED信息缓存一个slot对应的节点,但是这种做法在初期会经常造成访问两次集群。
- 还有一种做法是在节点返回MOVED信息后,通过cluster nodes命令获取整个数据分布表,这样就能每次请求到正确的节点,一旦数据分布表发生变化,请求到错误的节点,返回MOVED信息后,重新执行cluster nodes命令更新数据分布表。
在访问集群的时候,节点可能会返回ASK错误。这种错误是在key对应的slot正在进行数据迁移时产生的,这时候向slot的原节点访问,如果key在迁移源节点上,则该次命令能直接执行。如果key不在迁移源节点上,则会返回ASK错误,描述信息会附上迁移目的节点的地址。客户端这时候要先向迁移目的节点发送ASKING命令,然后执行之前的命令。
这些细节一般都会被客户端sdk封装起来,使用者完全感受不到访问的是集群还是单节点。
集群支持hash tags功能,即可以把一类key定位到同一个slot,tag的标识目前不支持配置,只能使用{},redis处理hash tag的逻辑也很简单,redis只计算从第一次出现{,到第一次出现}的substring的hash值,substring为空,则仍然计算整个key的值,这样对于foo{}{bar}、{foo}{bar}、foo这些冲突的{},也能取出tag值。使用者需遵循redis的hash tag规范。
127.0.0.1:6379> CLUSTER KEYSLOT foo{hash_tag}
(integer) 2515
127.0.0.1:6379> CLUSTER KEYSLOT fooadfasdf{hash_tag}
(integer) 2515
127.0.0.1:6379> CLUSTER KEYSLOT fooadfasdfasdfadfasdf{hash_tag}
(integer) 2515我们都知道,redis单机支持mutl-key操作(mget、mset)。redis cluster对mutl-key命令的支持,只能支持多key都在同一个slot上,即使多个slot在同一个节点上也不行。通过hash tag可以很好的做到这一点。
public static void main(String...strings) {
String[] kvs = {"{k_}1","values1","{k_}2","values2"};
RedisUtils.mset(kvs);
List mget = RedisUtils.mget("{k_}1","{k_}2");
System.out.println(mget);
} 同理,对于事务的支持只能在也一个slot上完成;其次,redis cluster只使用db0。
故障转移
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
集群间节点支持主从关系,复制的逻辑基本复用了单机版的实现。不过还是有些地方需要注意。
- 首先集群间节点建立主从关系不再使用原有的SLAVEOF命令和SLAVEOF配置,而是通过cluster replicate命令,这保证了主从节点需要先完成握手,才能建立主从关系。
- 集群是不能组成链式主从关系的,也就是说从节点不能有自己的从节点。不过对于集群外的没开启集群功能的节点,redis并不干预这些节点去复制集群内的节点,但是在集群故障转移时,这些集群外的节点,集群不会处理。
- 集群内节点想要复制另一个节点,需要保证本节点不再负责任何slot,不然redis也是不允许的。
- 集群内的从节点在与其他节点通信的时候,传递的消息中数据分布表和epoch是master的值。
集群主节点出现故障,发生故障转移,其他主节点会把故障主节点的从节点自动提为主节点,原来的主节点恢复后,自动成为新主节点的从节点。
这里先说明,把一个master和它的全部slave描述为一个group,故障转移是以group为单位的,集群故障转移的方式跟sentinel的实现很类似。某个master节点一段时间没收到心跳响应,则集群内的master会把该节点标记为pfail,类似sentinel的sdown。集群间的节点会交换相互的认识,超过一半master认为该异常master宕机,则这些master把异常master标记为fail,类似sentinel的odown。fail消息会被master广播出来。group的slave收到fail消息后开始竞选成为master。竞选的方式跟sentinel选主的方式类似,都是使用了raft协议,slave会从其他的master拉取选票,票数最多的slave被选为新的master,新master会马上给集群内的其他节点发送pong消息,告知自己角色的提升。其他slave接着开始复制新master。等旧master上线后,发现新master的epoch高于自己,通过gossip消息交互,把自己变成了slave。大致就是这么个流程。自动故障转移的方式跟sentinel很像,具体步骤可以参考本人写的《redis sentinel 设计与实现》。
redis还支持手动的故障转移,即通过在slave上执行cluster failover命令,可以让slave提升为master。failover命令支持传入FORCE和TAKEOVER参数。
- 不传入额外参数:如果主节点异常,则不能进行failover,主节点正常的情况下需要先比较从节点和主节点的偏移量,此时会让主节点停止客户端请求,直到超时或者故障转移完成。主从偏移量相同后开始手动故障转移流程。
- FORCE:使用FORCE参数与sentinel的手动故障转移流程基本类似,强制开始一次故障转移。
- TAKEOVER:这种手动故障转移的方式比较暴力,slave直接提升自己的epoch为最大的epoch。并把自己变成master。这样在消息交互过程中,旧master能发现自己的epoch小于该slave,同时两者负责的slot一致,它会把自己降级为slave。
均衡集群的slave(Replica migration)
在集群运行过程中,有的master的slave宕机,导致了该master成为孤儿master(orphaned masters),而有的master有很多slave。此处孤儿master的定义是那些本来有slave,但是全部离线的master,对于那些原来就没有slave的master不能认为是孤儿master。redis集群支持均衡slave功能,官方称为Replica migration,而我觉得均衡集群的slave更好理解该概念。集群能把某个slave较多的group上的slave迁移到那些孤儿master上,该功能通过cluster-migration-barrier参数配置,默认为1。slave在每次定时任务都会检查是否需要迁移slave,即把自己变成孤儿master的slave。 满足以下条件,slave就会成为孤儿master的slave:
- 自己所在的group是slave最多的group。
- 目前存在孤儿master。
- 自己所在的group的slave数目至少超过2个,只有自己一个的话迁移到其他group,自己原来的group的master又成了孤儿master。
- 自己所在的group的slave数量大于
cluster-migration-barrier配置。 - 与group内的其他slave基于memcmp比较node id,自己的node id最小。这个可以防止多个slave并发复制孤儿master,从而原来的group失去过多的slave。
网络分区说明
redis的集群模式下,客户端需要和全部的节点保持连接,这样可能出现网络分区问题,客户端和一些节点在一个网络分区,另一部分节点在另一个网络分区。在分区期间,客户端仍然能执行命令,直到集群经过cluster-node-timeout发现分区情况,节点探测到有slot无法提供服务,才开始禁止客户端执行命令。
这时候会出现一种现象,假设客户端和一个master在小分区,其他节点在大分区。超时后,其他节点共同投票把group内的一个slave提为master,等分区恢复。旧的master会成为新master的slave。这样在cluster-node-timeout期间对旧master的写入数据都会丢失。
这个问题可以通过设置cluster-node-timeout来减少不一致。如果对一致性要求高的应用还可以通过min-slaves-to-write配置来提高写入的要求。
参考:
https://www.cnblogs.com/qiumingcheng/p/6849125.html