论文阅读——Pushing the Limits of Translation Quality Estimation
https://www.aclweb.org/anthology/Q17-1015.pdf
挑战翻译质量评估的极限
Github:https://github.com/Unbabel/OpenKiwi
翻译质量评估可以极大减少后编辑工作,本文使用单词级质量评估和自动后编辑之间的协同,将一个新模型堆叠到具有丰富特征的单词级质量评估系统中,使用自动后编辑系统的输出作为一个额外的功能,取得了非常好的效果,在 WMT16 单词级 F1^MULT 为57.47%(比 sota 增加了7.95%),句子级 HTER 的皮尔逊相关性分数为65.56%(增加13.36%)。
1 Introduction
质量评估 QE 在没有参考译文的情况下评估翻译系统的质量,有很多用途:确定翻译的可靠性、是否可以直接使用或者需要人工后编辑、高亮需要更改的单词。
单词级 QE 是为翻译的每个单词分配 OK/BAD 标签(图1),以前的方法包括带有手工特性的线性分类器,经常结合特征选择、RNN,以及结合线性和神经模型的系统。

作者提出一个“pure”QE 系统,将 NeuralQE 堆叠到一个线性 feature-rich 分类器 LinearQE 中;并引入自动后编辑的相关任务(APE 自动纠正机器翻译 MT 的输出; Simard et al. 2007),证明了经过大量人工“roundtrip translation”训练对预测单词级质量标签非常有效,还证明了 pure QE 和 APE-based QE 系统是高度互补的:LinearQE、NeuralQE 和 APEQE 的堆叠组合可以得到 sota 分数。作者还提供了一个简单的 word-to-sentence 转换,可将系统用于句子级 QE 任务,并取得了 sota HTER 分数。
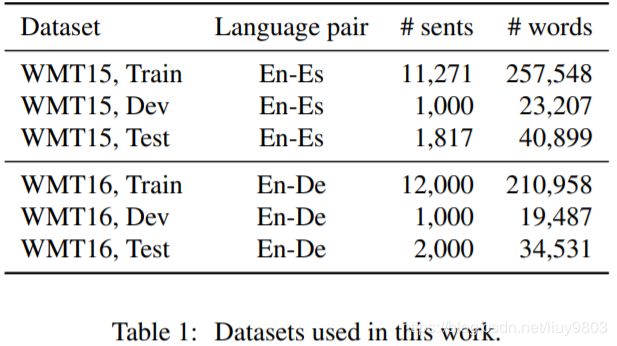
2 Datasets and System Architecture
Datasets.
Evaluation.
单词级 QE 任务的官方度量是 WMT15:F1^BAD、WMT16:F1^MULT。
句子级 QE 任务是 HTER 的皮尔逊相关性分数 r、句子排名的斯皮尔曼相关性分数 ρ。
From post-edited sentences to quality labels.
使用 TERCOM(Snover et al., 2006)对齐 MT 和 PE 获得 HTER,还可以识别单词替换错误、单词缺失(即被翻译系统省略的单词)和插入(翻译中的冗余单词),MT 输出中需要修改的单词的标签为 BAD。单词级 QE 的两种方式:
(1)Pure QE:使用 TERCOM 生成质量标签以训练 QE 系统;
(2)APE-based QE:使用原始 PE 训练 APE 系统,运行时使用 TERCOM 将自动 PE 转换为质量标签。
从机器学习的角度来看,QE 是一个序列标记问题,APE 是一个序列到序列问题,因此可以将 APE-based QE 看作是更复杂、更细粒度的 APE 输出到简单的 QE 输出空间的“投影”。APE-based QE 使用更细粒度的信息进行训练,如果训练数据足够多还能够进行很好地泛化。作者将最先进的 pure QE 和 APE-based QE 组合,生成一个新的、更强大的 QE 系统。
3 Pure Quality Estimation
3.1 Linear Sequential Model
LinearQE, a discriminative feature-based sequential model,输入为元组
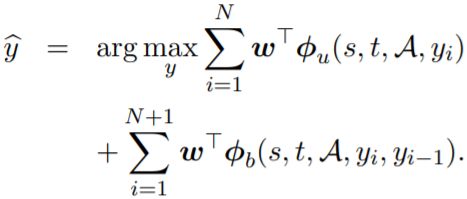
其中 φ_u(s, t, A, yi) 是 unigram 特征,φ_b(s, t, A, yi, yi−1) 是 bigram 特征,y0 和 yN+1 是特殊的 start/stop 符号。
Features. 表2为 LinearQE 中使用的一元和二元特征。不但像 WMT15/16 中的基准一样使用了目标词、对齐的源词以及它们的上下文特征,还使用了语法特征以发现语法错误的结构,包括依存关系、head word、second-order sibling 和 grandparent structures。使用 TurboTagger 和 TurboParser (Martins et al., 2013) 获得词性 POS 标签和句法信息特征。

Training. 运行 max-loss MIRA 算法 (Crammer et al., 2006) 50个 epoch,正则化常数 C ∈ {10^−k}_k=1^4,Hamming 损失函数对假正例的惩罚比假负例要高(c_FP ∈ {0.5, 0.55, ..., 0.95}, c_FN = 1 − c_FP),因为 BAD 标签比 OK 标签少。
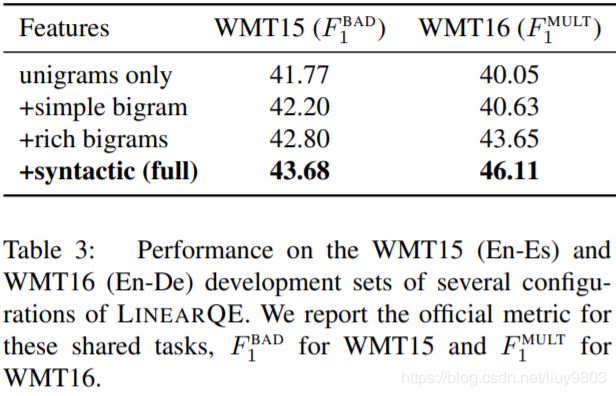
Results and feature contribution. 表3为 LinearQE 不同变体的性能,使用 bigram、句法特征可以提高 unigram 模型性能。
3.2 Neural System
QUETCH 及其与其他神经模型的集成是 WMT15/16 获胜系统,然而当单独考虑时,这些神经模型中没有一个能够超越线性模型:例如在 WMT15 测试集中 QUETCH 的 F1^BAD 为35.27%,远低于同一团队构建的线性系统的40.84%。
Architecture. NeuralQE 的架构如图2所示,输入是源句 s、目标句 t、它们的单词对齐A、以及 TurboTagger 获得的它们相应的 POS 标签。输入层类似 QUETCH的体系结,并添加了POS功能,每个目标单词的表征是该单词与源对齐单词的嵌入连接,源和目标单词的直接左右上下文也被连接起来。对英语、德语和西班牙语使用预训练的64维 Polyglot 词嵌入 (Al-Rfou et al., 2013),训练时不断对其进行调整。每个源和目标单词的 POS 标签也被嵌入和连接起来,POS 嵌入大小为50,按照Glorot and Bengio (2010) 的描述进行初始化。对产生的向量表征使用0.5的 dropout。
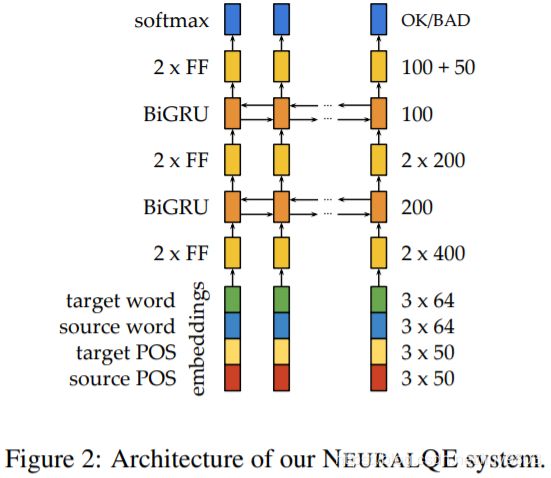
(1)两个前馈 ReLU 层,大小为400;
(2)一个双向 BiGRU 层,大小为200,正向和反向向量连接,层归一化;
(3)两个前馈 ReLU 层,大小为200;
(4)一个双向 BiGRU 层,大小为100,配置同(2);
(5)两个前馈 ReLU 层,大小分别为100和50。
输出层使用 softmax 得到OK/BAD标签。
Training. 使用 RMSProp 最小化 BAD 词预测的交叉熵,BAD 的权值设为3.0,目标句按长度分桶(不需要填充或截断)。
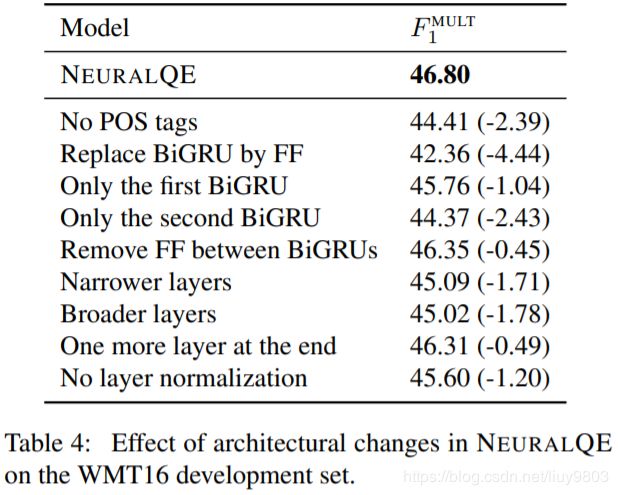
Results and architectural choices. 结果如表4所示。Neural QE 的 F1^mult 为46.80%,相比表3中的 LinearQE 为 46.11%。一些变体,如使用 FF 代替 RNN 层,会使分数大幅下降超过4分(即变成了更深的 QUETCH);如果删除第一个 BiGRU 会使分数下降超过2点;RNN 中使用层归一化会提高1.2分;去掉 POS 标签输入会使分数几乎下降了2.5;改变隐藏层的大小和网络的深度会轻微影响模型的性能。
3.3 Stacking Neural and Linear Models
Stacked QE:将 NeuralQE 集成到 LinearQE 中。Stacking 的基本思想是将第一个系统的预测作为第二个系统的输入从而组合两个系统。使用 K 折分割训练集(本文 K = 10)训练第一个系统 K 次,每次使用 K-1 折进行训练,使用剩下的一折进行预测,将所有预测串接,就得到了第二个系统的无偏训练集。
Neural intra-ensembles. 表5-6为 WMT15/16 中一种模型的5或15(有点退化)个集成的结果,即 NEURALQE-5、NEURALQE-15,取每个词是 BAD 的平均概率综合。
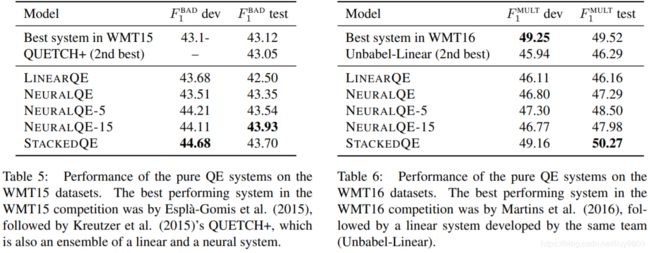
Stacking architecture. 不同模型作为不同的特征被合并到堆叠结构中,称为 StackedQE。在训练、验证和测试数据集中每个 NeuralQE 对每个单词给出15个预测概率值,这些预测被作为 LinearQE 的附加特性。Unigram 特征是每个模型对每个位置预测得到1个实值特征,并与标签相结合;Bigram 特征,对两个位置使用两个实值特征,并与标签对结合。这种堆叠架构在 WMT15/16 的结果见表5-6。
4 APE-Based Quality Estimation
Junczys-Dowmunt and Grundkiewicz, 2016 将不同的模型作为对数线性模型的组件,将多个输入(源句 s 和翻译句子 t)解码到同一目标语言(后编辑 p)。两个系统,一个使用 s 作为输入(s→p),另一个使用 t 作为输入(t→p),在对数线性模型中集成一个简单的字符串匹配惩罚项,以控制原始 MT 输出更高的可靠性,如果 APE 在输出中建议了一个 t 中没有出现的单词,就会触发惩罚。
为了克服训练数据太少的问题,使用 round-trip translations 生成大量的人工数据:in-domain 目标语言的大量单语句子(每个句子可认为是一个后编辑 p),使用一个 MT 系统将这些句子翻译为源语言(作为源句 s),然后使用一个 MT 系统反向翻译源句为目标语言(作为翻译 t)。过滤人工数据以与训练和验证数据的 HTER 相匹配 https://github.com/marian-nmt/marian。
4.1 Training the APE System
作者使用 Nematus (Sennrich et al., 2016) https://github.com/EdinburghNLP/nematus 进行训练,使用 AmuNMT (Junczys-Dowmunt et al., 2016) 进行解码,重现了Junczys-Dowmunt and Grundkiewicz (2016) 的实验。在训练堆叠分类器时,为了避免过拟合,需要使用 jackknife 方法,步骤如下:
• 将原始 WMT16 训练集划分为四个大小相同的部分,将三个部分合并,可以创建四个新的训练集。
• 训练四个 APE 模型,分别使用四个新训练集20折上采样、与人工数据(即“round-trip. n1”,531,839个句子三元组)的组合作为训练数据。
• 为了避免过度拟合,在 GRU 步骤和输入嵌入上使用概率为0.2的 scaling dropout,在源和目标单词上的概率为0.1。
• 使用 Adam 而不是 Adadelta。
• 对两个模型(s→p 和 t→p)训练20个 epoch 直到收敛,每10,000批保存一个 checkpoint。
• 将最后四个 checkpoints 按元素平均,产生新的单个模型。
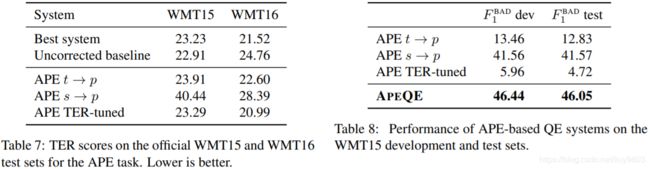
为了验证 APE 系统的质量,集成8个模型(4个 s→p 和4个 t→p),并添加了 APE 惩罚项。由于是集成不同类型的模型,使用 MERT (Och, 2003) 对权重进行 TER 向调优,得到 APE TER-tuned 模型,结果见表7。对于只有 s→p 或 t→p 的集成,模型权值相等。在使用更少的数据的情况下,在 TER 方面取得了比原始系统稍好的结果。将此过程用于 WMT15,使用 roundtrip 翻译生成500K人工 en-es-es 后编辑三元组数据。WMT15 的结果不如 WMT16 有说服力,没能超过基准,然而是第二好的大小写敏感 TER 系统和最好的大小写不敏感 TER 系统。
4.2 Adaptation to QE and Task-Specific Tuning
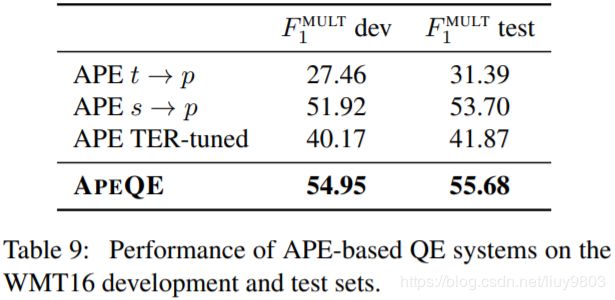
APE 的输出可以使用基于 TER 的词对齐转换成词质量标签。表9中 s→p 系统是迄今最强大的单个 QE 系统,该系统本质上是一个再训练的 neural MT 组件,没有任何额外的特征;t→p 系统和 TER-tuned APE 集成的分数要低很多,因为它们专门针对 TER 任务。专门针对 F1^MULT 训练 full APE 以获得更好的结果,得到新的最佳单个 QE 系统 APEQE。
5 Full Stacked System
最后,考虑一个更大的堆叠系统,将 NeuralQE 和 APEQE 堆叠到 LinearQE 中,混合了 pure QE 和 APE-based QE,称为 FullStackedQE。
5.1 Word-Level QE
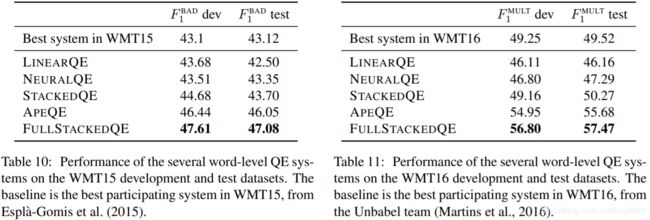
FullStackedQE 系统在 WMT15/16 的性能如表10-11所示,可以看到,APE-based 和 pure QE 系统是互补的:linear、neural 和 APE-based 系统的结合在 WMT15/16 中分别提高了1到2分,这是一个显著的改进,可以为工业环境中更广泛地采用单词级 QE 系统铺平道路。
5.2 Sentence-Level QE
将 FullStackedQE 系统应用于句子级 QE。之前的工作将单词级作为特征纳入句子级 QE 中,训练基于特征的线性分类器。对于 APE 系统,很容易得到 HTER ——可以简单地衡量翻译句子 t 和预测修正后的句子 p~ 之间的 HTER;对于 pureQE 系统,使用 word-to-sentence 转换:(i) 运行 QE 系统获得一系列 OK/BAD 标签,(ii) 使用 BAD 标签的比例作为 HTER 。这个过程虽然不需要任何训练,但远非完美。在翻译句子中不存在、但在参考后编辑句子中存在的词不会产生 BAD 标签,因此不会对 HTER 估计有帮助,但是这种方法应用于 StackedQE 系统(即不包含 APEQE)就已足以获得最先进的结果。最后,为了将 APE 和 pure QE 结合到句子级 QE 中,只需取两个预测的平均值。表12为 pure QE 系统(StackedQE)、APE-based 系统(APEQE)以及两者组合(FullStackedQE)的结果,即使是最弱的 StackedQE 也远超基准。

6 Error Analysis
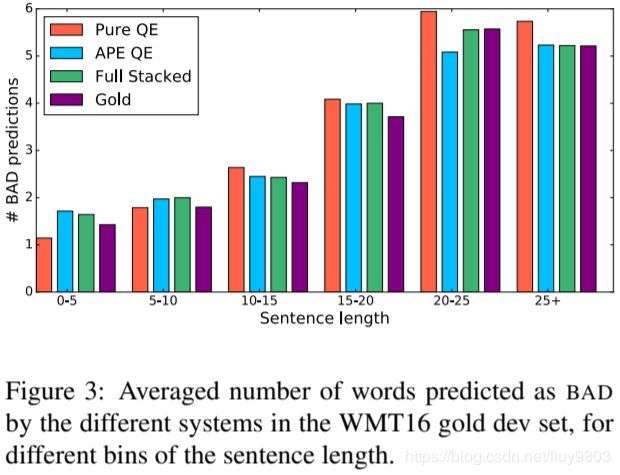
Performance over sentence length. 为了更好地理解纯 StackedQE 和 APEQE 之间的性能差异,分析这两个系统以及它们的组合 FullStackedQE。图3为三个系统预测不同长度句子的 BAD 词的平均数,和真实 BAD 词的平均数。对于短句子(少于5个单词),pure QE 系统往往过于乐观(低估了 BAD 词数),同时 APE-based 系统过于悲观;在5-10个词的范围内,pure QE 比 APE-based 系统更准确;对于中/长句,表现则相反(20-25尤其明显),APE-based 系统通常更好。另一方面,两种系统的结合 FullStackedQE 设法在这两种偏差之间找到一个很好的平衡,比任何单独的系统都更接近短句子和长句子 BAD 标签的真实比例,由此可知,这两种系统在结合时具有很好的互补性。
Illustrative examples. 表13为 WMT16 验证数据质量预测的具体例子。在第一个例子中,APE 正确地用 Mischfarbe 替换了 Angleichungsfarbe,但是其他部分没有得到纠正,因此 APEQE 漏掉了一些 BAD 词,但设法为 den 获得了正确的标签 OK;相比之下,pure QE 错误标记了这个词,但是它对 Farbton 和 zu erstellen 做出了正确的标记,比 APEQE 更准确;这两种系统的结合可得正确的预测。在第二个例子中,pure QE 将正确的标签分配给 Zusatzmodul,而 APE 误将这个单词翻译成 Dialogfeld,导致 APEQE 做出了错误的预测;pure QE 将 unterstutzt RGB- 误分类为 BAD,而 APEQE 分类正确;同样地,这两个系统可以很好地相互补充。

7 Conclusions
作者介绍了最新的单词级和句子级 QE 系统,比 WMT15/16 上的旧系统更加精确。提出了一种新的 pure QE系统,将线性系统和神经系统结合,比目前最好的单词级系统更简单、更精确;通过关联 APE 和单词级 QE 的任务,得到 APE-based QE 系统,利用额外的人工 roundtrip 翻译数据,实现了更大的提升;使用一个完整的叠加架构将两个系统结合,可以进一步提高分数。错误分析表明,纯系统和基于 APE 的系统具有很强的互补性,简单的单词到句子的转换可以将整个系统扩展到句子级 QE,不需要进一步的训练或调整。