背景:MySQL5.6.40,库比较小,row+gtid复制环境,但由于以前种种原因,备份还原在从库后,开启复制存在大量1062,1032错误,gtid卡在靠前位置。做复制的时候没有任何从库,每小时的备份也被运维停了。
以前从来没遇到过这种情况,相对测试环境正式环境比较复杂,而且猜测可能是之前备份还原从来没用过备份一致性参数导致,并且发现错误也没有手工检查(这个问题还在研究中,有遇到并知道原因的小伙伴欢迎指导)。
为了今后避免因为恢复不及时导致的数据丢失,特别总结本次故障过程和大家讨论、分享。
简化时间轴如下图:
开始---->备份主库---->恢复从库---->复制error1032,1062---->删除从库再次恢复---->复制error1032,1062---->reset master从库、主库---->准备删除从库---->误操作删主库----->恢复主库----->跳过大量1062、1032错误---->找drop db位置恢复从库---->对比主从数据---->手工补数据---->结束
下面按照我的记忆描述下当时的场景:
一、首次备份主库、搭建从库
第一次搭建从库,从主库的备份未使用master-data=2 single-transaction(保证事务备份时的一致性)参数迁移后,报大量1062和1032错误(家家有本难念的经,不多说了)
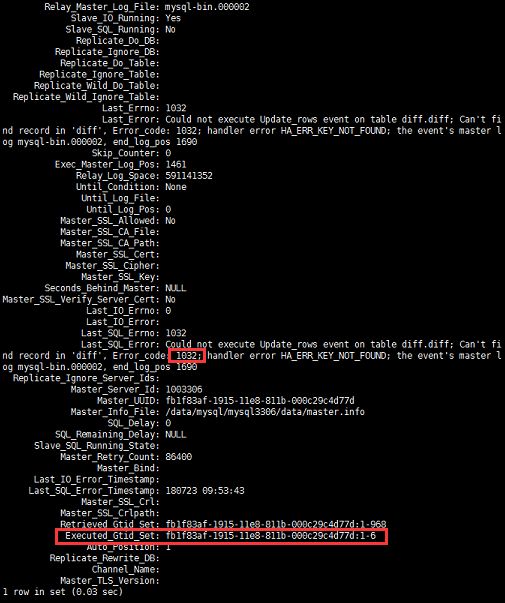
二、第二次还原主库到从库
于是第二次重新导入。
同样报错。在导入从库前使用reset master;将从库binlog清除。
由于操作人员不了解reset master含义及执行结果,又在主库做了reset master;
结果导致主库所有binlog日志被清除并且binlog position置为1;
这里贴以下官方说明,别没事干就在主库上用这条。

再次导入发现依旧大量报1032,1062错误。
由于怀疑是因为备份时没使用--single-transaction参数,准备删除从库,加参数重新备份主库。
三、误删除主库
结果误操作删除主库(这个锅一部分原因要甩给mysql naivcat这个工具,垂直排列库,稍微不注意就容易点错。还是建议大家听吴老师的用官方的workbench),删库还是两人校对,在操作系统上执行,删前没把握最好备份一遍。
删库这种操作谨慎谨慎再谨慎,重要的事情说三遍!
删库这种操作谨慎谨慎再谨慎,重要的事情说三遍!
删库这种操作谨慎谨慎再谨慎,重要的事情说三遍!
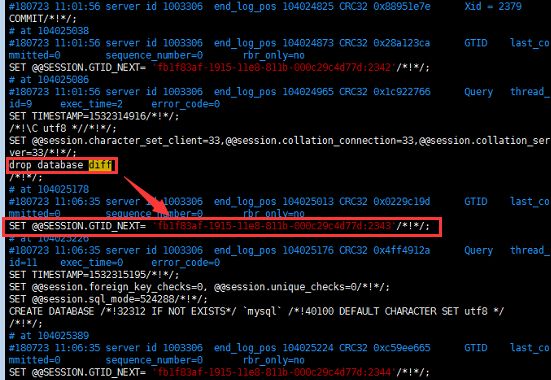
drop database;(在naivcat上右键删除库,但binlog日志中还是会记录DROP DATABASE这条记录)
这时候为了保证业务不中断,立马在主库上通过之前的备份文件恢复了一套库,当然数据肯定丢失了,但可以推算丢失数据的时间段(从备份完毕开始--->DROP DATABASE)。
PS.请不要问我为什么删库,为什么删完又恢复了一套库,因为都不是我干的。。。。。。
万幸的是误删除主库但并未删除从库,而且从库的io_thread仍然处于yes状态(回顾吴老师的课程,也就是说虽然库被删除了但其实删库前的数据=备份数据+io_thread已下载的删除主库前的数据),由于sql_thread仍然停到gtid靠前的位置

四、跳过大量1032,1062错误
这个时候只要看下备份文件的gtid位置,并purge到该位置(之前备份丢了,随便找了一个备份的截图,理解万岁)。
##这里说明一下为什么直接purge到备份的结尾位置,因为书库备份的数据中1032和1062错误太多,且主库已经删除没办法通过脚本对比跳过大量1032,1062错误(吴老师友情提供),在能够保证是从主库逻辑备份过来的情况下(主从数据一致),我们选择快速跳过大量错误(偷懒加情况急),直接purge到备份最后的位置。
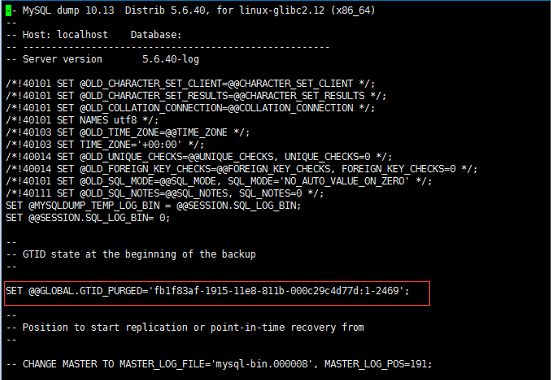
##上图是随便截的一个备份文件最开头的位置,请忽略那个gtid的值,意思明白就行。
set @@gtid_purged='fb1f83af-1915-11e8-811b-000c29c4d77d:1-500';
注:‘500’代表备份文件最后一个执行的事务的gtid。gtid_purged代表数据库已经在从库上重放过1-500这段事务。
五、找到主库DROP DATABASE的GTID位置
purge到该位置然后再确定drop database的位置上(思路:如果不确定dropdatabase的位置就start slave 那么从库会应用主库的binlog也就会执行主库drop database的操作,为了避免从库重放主库drop database的操作,我们要设法让gtid在从库停到drop database前一个gtid的位置)
注:可以通过大致删库时间或者从从库的show slave status\G上看到主库的binlog位置从后往前找DROP DATABASE的位置,如果删库后做了reset master那就只能从从库的relay-bin-log上找了(切记主库没事别reset master);
mysqlbinlog -vvv --base64-output=decode-rows relay-bin.000017
六、启动从库SQL_THREAD
在从库上执行start slave sql_thread until的命令,这里需要说明,因为主库已经还原,业务跑起来了,这时候开启io_thread没有什么意义,所以只用让从库的sql_thread线程重放DROP DATABASE之前的事务就行。
root@localhost[{none}]>start slave sql_thread until sql_before_gtid='fb1f83af-1915-11e8-811b-000c29c4d77d:2343';
启动slave,并且让从库gtid停在主库drop database操作之前一个gtid就可以,再还原到主库就能立马投入使用,还不会导致数据丢失。
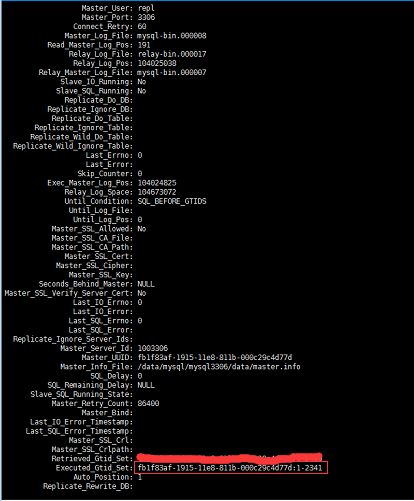
确保从库executed_gtid_set到了我们before的前一个值就可以备份了,然后dump这份数据还原主库,当然如果从库性能不错的话可以考虑应用端更改连接,这样速度更快一些。
但比较麻烦的就是,要保证生产的实时性,删库后立即在主库上还原了之前用来恢复从库的备份文件,这就肯定会导致中间数据丢失。
七、数据对比还原
这时候只能使用用之前用来搭建从库的备份再恢复一个库,再用pt-table-checksum对比主库和恢复库,从库和恢复库不一致的数据,用pt-table-sync生成对应语句。然后手工把数据补进系统中。
对比1:主库:备份数据还原的库---->目标:找到主库在删库之后应用又写入了哪些数据。
对比2:从库:备份数据还原的库---->目标:找到备份数据之后,删库之前应用在主库里写了哪些数据。
因为量不是很大,手工对比一下就行,当然数据还原的坑也有很多,不过基本上都被研发填了。
总结:
头一回碰到删库情况还是有点蒙,还好主库用的是GTID找binlog日志中的位置相对容易一点。这次恢复最幸运的就是还好从库卡在靠前的位置,要不然即使有了从库,数据也会被删了,恢复起来相对更麻烦些。
对于gtid的恢复,课上吴炳锡老师都讲过,但是一上手还是慢了几拍,还是要通过实战多练习加深手感避免在真实情况下懵逼。
最后特别鸣谢:知数堂叶金荣老师和吴炳锡老师在故障发生时给予的帮助和支持。