Welcome to My ITPUB blog
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。计算机要准确的处理各种字符集文字,需要进行编码,以便计算机能够识别和存储各种字符。
0x01 字符集
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
字符集从表示字符使用字节的数目来区分,可以分为单字节字符集和多字节字符集。
单字节字符集
顾名思义,单字节字符集是使用一个字节表示字符的字符集。常见的包括Latin(又称ISO8859)系列字符集(如Latin1、ISO8859P1等)、ASCII等。
由于只有一个字节,单字节字符集最多只能表示256个字符。
多字节字符集
多字节字符集使用一个或多个字节表示一个字符。
支持中文的字符集
支持中文的字符集包括国标系列字符集(GB2312、GBK、GB18030)和Unicode。
Latin系列字符集的编码范围是00-FF,因此无论是单字节表示的字符还是多字节表示的字符,均可以存储任意字符包括中文。
0x02 字符编码
相同的字符,在不同的字符集下可能有不同的编码。比如“中文”这两个字符,在GBK字符集的编码为d6,d0,ce,c4,在Unicode字符集中使用UTF8编码为e4,b8,ad,e6,96,87。相同的字符可能有不同的编码,在字符集不同的操作环境中交换数据可能会发生编码转换,如果转换失败就会出现乱码。
编码转换
编码转换在操作环境字符集不同的情况下发生。操作环境为操作系统为中文版Windows,默认的字符集为GBK,而在操作系统为Linux,则使用的字符集为UTF8,在这两者之间进行数据交换时,就可能发生字符编码转换。
比如我们在Windows平台(使用默认的环境变量)下启动SQL*PLUS从远程字符集为UTF8的Oracle数据库中查询含有中文的数据时,会发生UTF8字符编码向GBK字符集的编码转换。这个转换过程在下一章节会详细讨论。
乱码
字符编码如果转换不成功,就会产生乱码。在编码转换中我们提到,字符从UTF8转换为GBK,由于UTF8和GBK均存在相应的中文字符编码,这时候转换是成功的,不会产生乱码,如“中文”两个字符,从“e4,b8,ad,e6,96,87”转换为“d6,d0,ce,c4”编码。但如果从GBK往Latin1转换或者Latin1往GBK进行转换时,由于两种字符集不兼容,转换就会出现乱码。
通常来说,无法转换的字符会变为目标字符集中的疑问字符,在ASCII下是3f,GBK下是a3,bf,在ISO8859P1下是bf。
另外,值得一提的是,如果是通过JDBC驱动获取数据,如果字符无法转换为UTF16(Java内部使用的字符编码),字符可能会变成null值。
0x03 Oracle中的字符编码转换
本章节以Oracle数据库为例详细解释在使用SQL*PLUS时,Oracle如何处理字符编码的转换。
操作模型

操作模型如上图所示,客户端环境包括操作系统OS、应用环境AppEnv、客户端工具SQL*PLUS和数据库驱动(OCI Driver)以及环境变量NLS_LANG。服务端环境包括操作系统OS,Oracle数据库。
举个例子,我们在中文版Windows中,通过CMD打开SQL*PLUS,连接到操作系统为CentOS 6.5,字符集为GBK的数据库。这时候操作模型的各种要素,客户端为:OS=Windows(字符集为GBK),AppEnv=CMD(默认CodePage=936,可通过chcp修改),NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK(默认值);服务端为:OS=Linux(字符集为Unicode,字符编码为UTF8),DB Character Set=GBK。
在客户端和服务端之间,是否需要字符转换,由客户端环境变量NLS_LANG进行控制,如NLS_LANG中定义的字符集与数据库字符集一致,则不发生转换,否则发生转换。设置该环境变量的最佳实践为:数据库字符集为单字节字符集,环境变量字符集与数据库字符集一致;数据库字符集为多字节字符集,环境变量字符集与客户端操作环境字符集一致。
下面我们按照各种不同的设置看看在写入数据时发生的字符编码转换。
#1:客户端为Win7/CodePage=936;服务端为UTF8数据库;NLS_LANG=.ZHS16GBK
如下图所示:
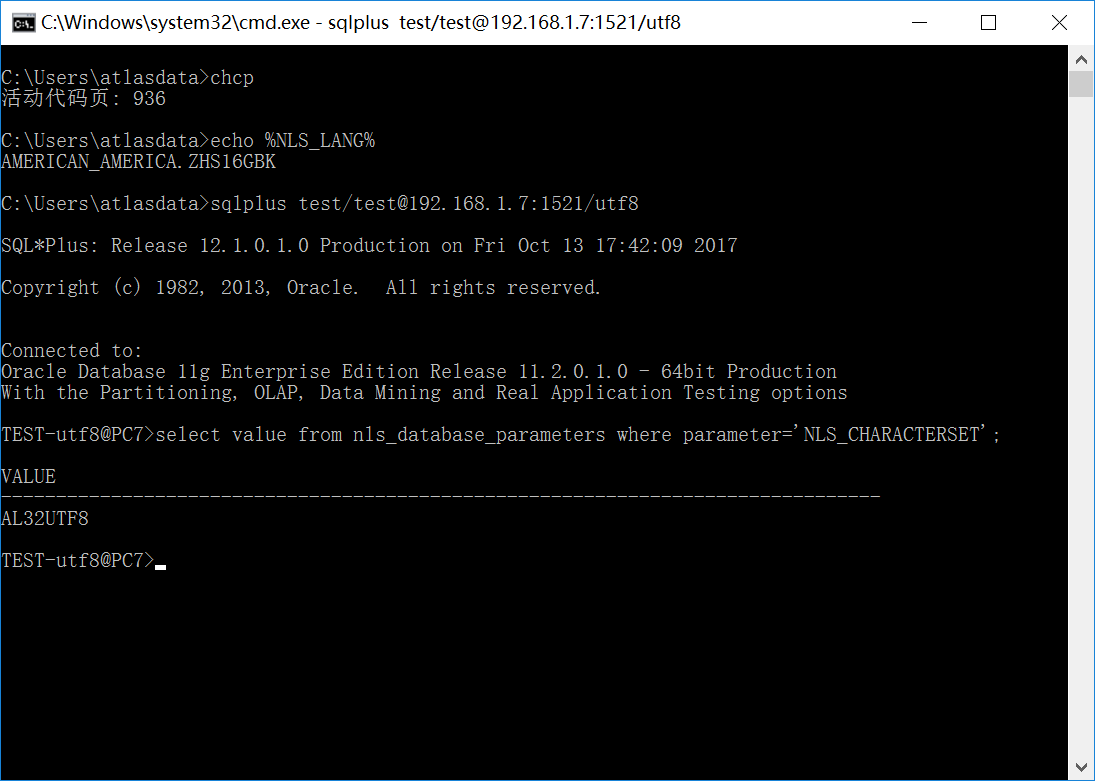
由于环境变量字符集与数据库服务器字符集不一致,这时候会发生编码转换,从GBK转换为UTF8,由于字符的实际编码为GBK而且GBK和UTF8两者兼容,因此转换成功,保存在数据库中的字符编码为正确的UTF8编码。
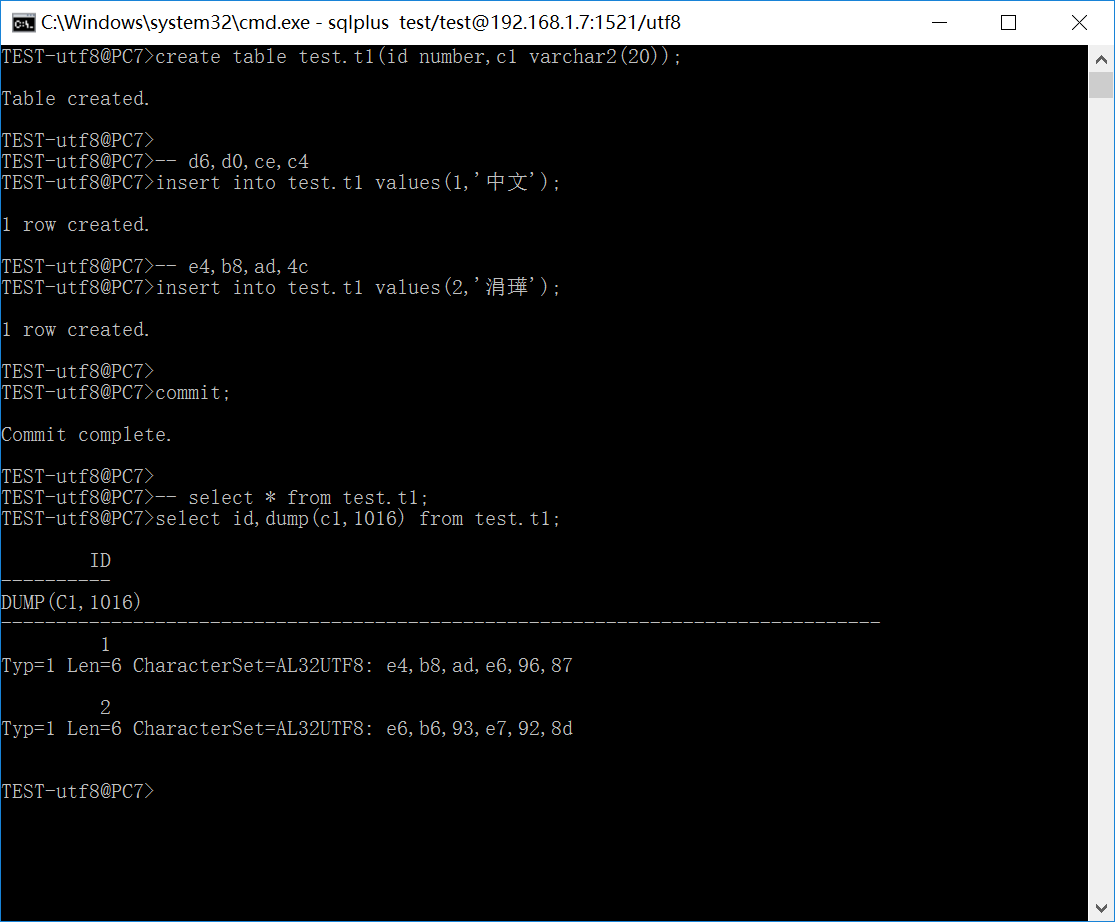
#2:客户端为Win7/CP=936;服务端为GBK数据库;NLS_LANG=.AL32UTF8
如下图所示:
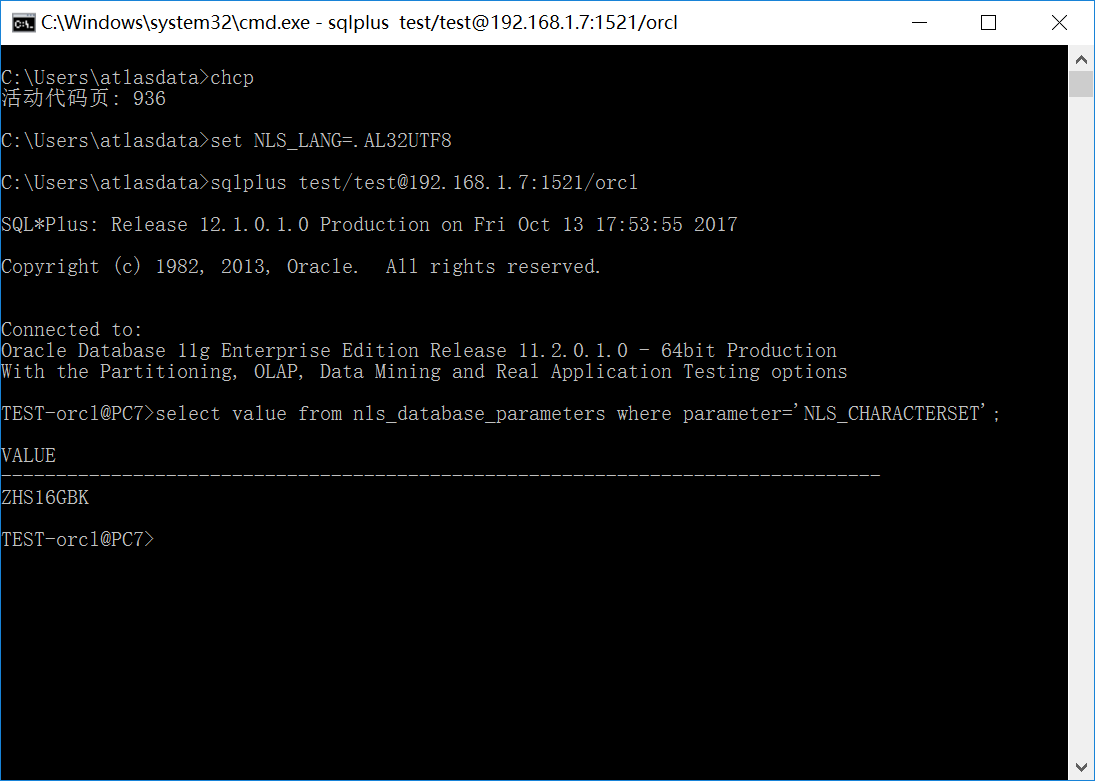
由于环境变量字符集与数据库服务器字符集不一致,这时候会发生编码转换,从UTF8转换为GBK,由于字符的实际编码为GBK,将会把这些字符编码视为UTF8编码往GBK转换,这时候会出现转换不成功的情况。
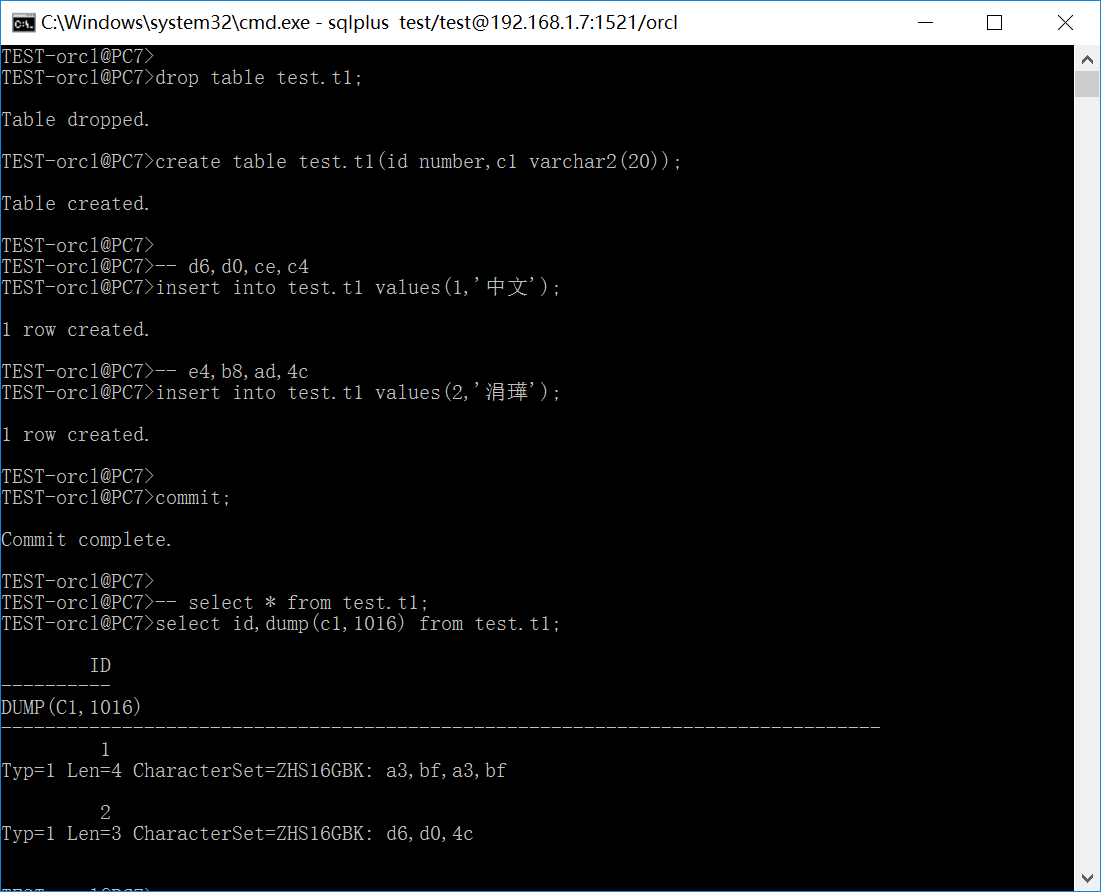
如上图所示,字符“中文”的GBK编码为d6,d0,ce,c4,均为不合法的UTF8编码,从UTF8转换为GBK时会转换为a3,bf;字符“涓璍”的GBK为“e4,b8,ad,4c”,前面3个字节为合法的UTF8编码(字符“中”的UTF8编码),因此从UTF8转换为GBK时,转换为字符“中L”(ASCII 4c为字符L)。
#3:客户端为Win7/CP=936;服务端为WE8ISO885P1数据库;NLS_LANG=.ZHS16GBK
如下图所示:
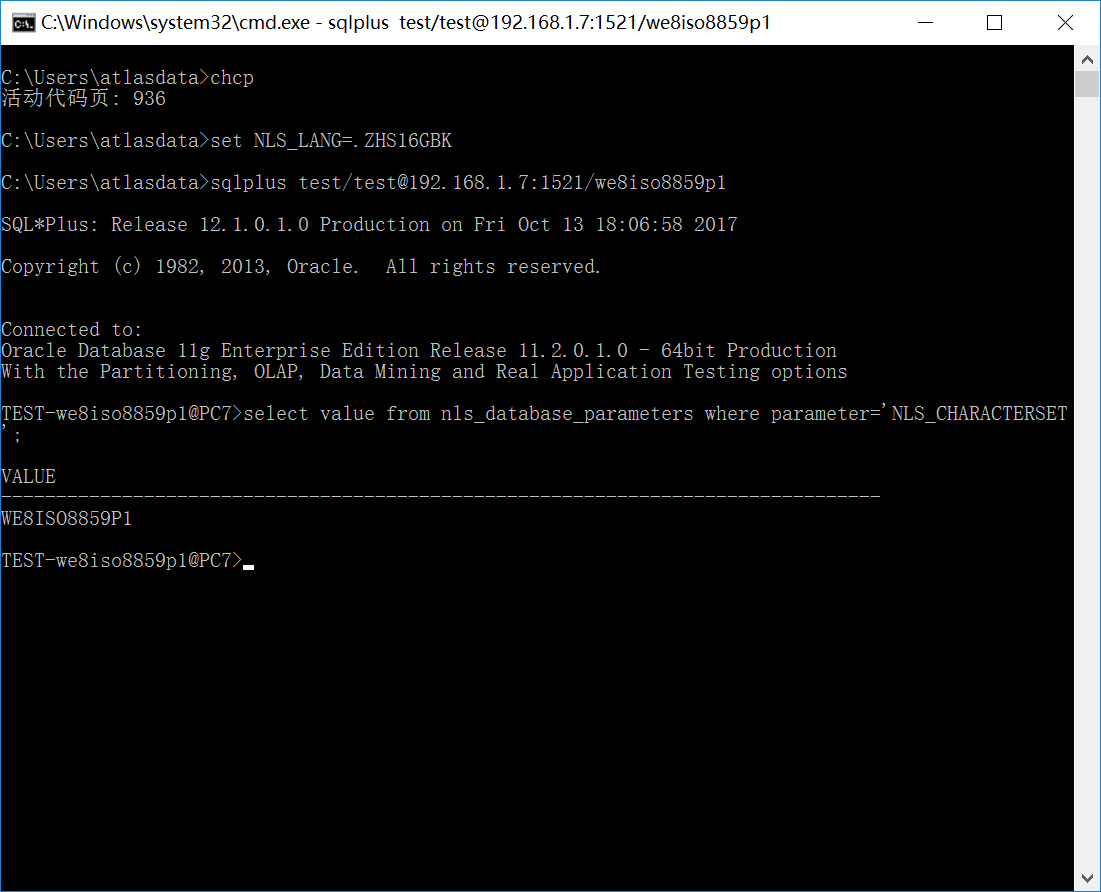
由于环境变量字符集与数据库服务器字符集不一致,这时候会发生编码转换,从GBK转换为ISO8859P1,由于字符集不兼容,字符转换失败,中文字符会变为bf。

在GBK字符集中,"bf,bf"为合法的字符编码,也就是中文字符“靠”的编码,这就是有时候我们看到一堆的“靠”字的原因所在。
0x04 结语
字符或其他信息的编码是计算机最基本的知识,因为只有经过编码之后的信息才能存储在计算机中,掌握好这些基础知识才能更好的理解其他更高级的内容。