sequence models
RNN(recurrent neural network)
RNN中的输入和输出的表示符号:
字典:其实就是将你要用到的单词放到一起做一个清单,一般商业应用的字典词汇可能包括3-5万,甚至10万以上的词汇,一些大型的商业应用有可能使用超过100万词汇的字典。如果不在字典中的词汇,标记为unknown单词
tx表示x中第t个序列输入值,使用01 onehot编码,在字典相应位置的单词则为1,否则为0
ty表示y中第t个序列的输出值,使用01 onehot编码,在字典相应位置的单词则为1,否则为0

直接的输入输出朴素神经网络方式有两个问题:
1、输入输出的长度并不一致,如果每个句子都有最大长度,你可能要扩充或零扩充每个输入项, 使其达到最大长度,但是这仍然不是高质量的表示方法
2、不会将那些从不同文本位置学到的特征,进行共享 ,输入和输出的矩阵数据量会非常大

Recurrent Neural Network 基本概念
这个循环神经网络的含义是 在对y3进行预测时,它不仅从x3获取信息 ,同时也考虑到x1和x2。
这个特定的神经网络结构的一个限制是在序列中对某一时间的预测仅使用之前的输入, 而不使用序列中之后的信息进行输入预测

RNN前向传播过程
a
yhat

RNN反向传播(基于时间的反向传播算法):
定义预测值y
整个损失函数L=∑L
根据损失函数,进行迭代a

不同结构的RNN
RNN常见的有五种结构:
1、输入1个x输出1个y
2、输入1个x,输出多个y
3、输入多个x,输出1个y
4、输入多个x,输出多个y,y
5、输入多个x,输出多个y,y

RNN处理自然语言过程。
初始输入x<1>,与初始化的a<0>通过计算得到a<1>,通过a<1>预测yhat<1>.yhat<1>的激活函数是softmax。激活的分类结果是词库以及unk(未势必词)和eos(判定结尾的词)。
x<2>的输入就是y<1>,然后计算出在y<1>的情况下出现y<2>的概率,如此反复进行预测之后的结果。根据预测结果计算出来损失函数的误差的大小

RNN字级别的模型举例如下:
自动生成一句话的模型例子中,训练集中数据是一对一的训练标记结果,在预测结果使用的是开始的词,根据概率计算判断下一个词出现的概率更大来组合成句话。

RNN的层数较多的情况下,在传播过程中有可能会遇到梯度消失和梯度爆炸的问题
梯度消失解决办法:GRU, 称作 greater recurrent units 这是一个非常有效的方案, 用以解决梯度消失问题, 并将允许神经网络来捕获更长范围的依赖性;或者使用LSTM(long short-tearm memory)
梯度爆炸解决办法:使用gradient clipping,就是看看你的梯度向量, 如果它大于某个临界值重新缩放某些梯度向量, 使其不那么大所以这是依据一些最大值的缩减

GRU计算在原来的a

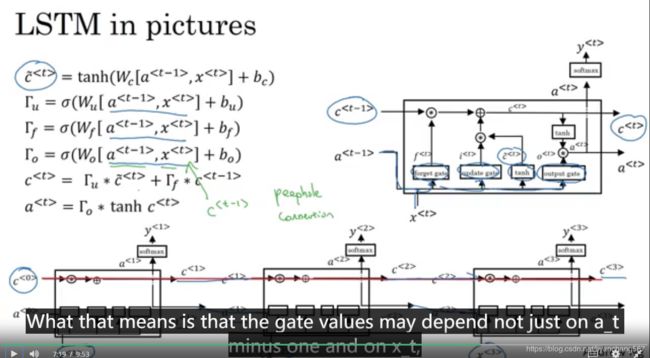
LSTM(Long Short-Term Memory)
GRU和LSTM相比
GRU更像是简版的LSTM,GRU的有点是其模型的简单性,它只有两个门控。因此更适用于构建较大的网络 ,从计算角度看,它的效率更高,它的可扩展性有利于 构筑较大的模型。GRU因为其简单而且效果可以(和LSTM)比拟 可以更容易的将其扩展到更大的问题
LSTM更加的强大和灵活,因为它具有三个门控,如果你要从两中方法中选取一个 ,很多人会选择LSTM,LSTM是经过历史检验的方法
LSTM与GRU比较类似,但是也有不同的地方:
1、LSTM中a
2、LSTM中c
3、LSTM中chat

LSTM整个算法模型的流程如下:
双向循环神经网络(Bidirectional RNN):双向神经网络不仅仅有前向的传播,也一部分后项传播,因此在预测的时候,你会考虑过去和未来的信息
双向 RNN 的缺点是需要整个数据序列, 然后才能在任何地方进行预测,对于实时的预测,如果仅仅使用双向的RNN则需要等待完整的一个序列(句子)才能进行预测。

词法/句法分析(Word embeddings)
单次的的预测的概率进行聚类(下图中的纵行的字段),单词每一列与其他的词的相似程度,学习单词的向量特征。如图中man和woman相似程度就相对较高

使用 t-SNE算法,降维后的数据可视化在二维图中,可以直观展示词的相近的程度。

词法分析(word embeddings)的迁移学习:
第一步是从大量的文本语料库学习单词嵌入, 或者可以从网上下载已经训练好的单词嵌入
第二步在较小标签数据集的命名识别任务上, 你可以选择性的去继续微调参数, 继续用新数据调整单词嵌入
第三步带标签的数据集很小, 那么通常, 我不会继续微调单词嵌入

嵌入词的分析(Properties of word embeddings)
嵌入词的分析可以判断一组词语另一组词之间的相似性,提升模型的系统分析的学习能力。

向量之间的相似性一般使用向量的夹角余弦值(cos)来衡量。

embedding 矩阵的表示方法。
变量表示词库表中的单词,每一行表示一个词的向量,该行使用one-hot编码方式进行编码。

自然语言预测输出模型:
1、单词使用词库向量化表示,堆叠出来E矩阵
2、计算词嵌入e矩阵,输入到全连接层
3、通过softmax激活函数,输出分类结果的概率,进行预测
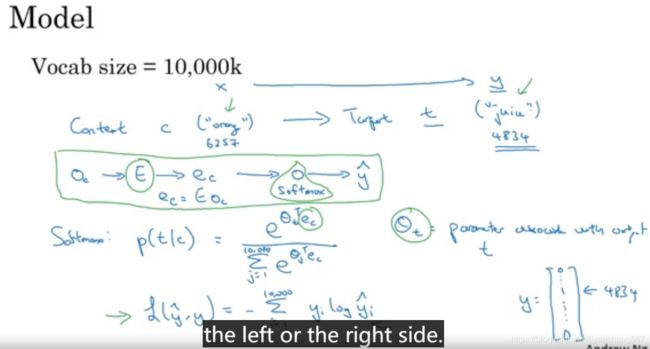
skip-gram算法
给定一个词,这个词前后多少词以内随机的一个词作为预测结果的监督学习。具体实现过程如下:
1、输入值orange,选取预测词juice
2、输入特征向量使用onehot编码,堆叠出e矩阵
3、计算出来词嵌入e的矩阵
4、使用softmax计算分类的结果的概率
softmax概率求和计算过程中是非常消耗计算资源的,
一种解决办法引入了hierarchical softmax classifier 分级softmax 分类器,不是一次性确定属于1W类中的哪一类,而是采用一种 类似二分查找的方法区分词嵌入向量所在类别。
示意图如下:

softmax计算成本高,也可以转化成为多个二元分类的问题,每个词都是二元分类作为一个分类器,大大的降低了计算的成本。但是全部的词库中的词都进行分类器预算是没有必要的。可以选择k个负样本的二元分类器,总共k+1个二元分类器。该方法称为负采样法,你做的正是 得到一个正样本,然后你会故意地生成一些负样本。

选择k个负样本的时候,词频统计的时候有些无意义词如“这”、“的”等等,Mikolov认为使用词频的3/4次幂与所有词频的3/4次幂加和做比值的方式来选取词汇。

GloVe word vectors算法:GloVe的意思是用于词汇表征的全局矢量,
假设 X_ij表示次数就是i 在 j的上下文中出现的次数
theta_i和 e_j是对称的就是说从数学的角度 ,它们的作用是一样的, 你可以把它们反过来或者对调它们 实际上得到的将是相同的目标优化函数 。因此训练这个算法的一种方式是随机均匀地 ,初始化 theta和 e,运用梯度下降法来最小化目标函数 ,然后当你对每个单词完成这个过程后 ,取平均值因此对给定的单词 w 最终的 e等于通过这个梯度下降法得到的嵌入 e,加上 通过梯度下降法得到的 theta
它看起来太简单了 怎么可能仅仅靠最小化一个 平方损失函数就训练出一个有效的词嵌入呢?但实际上,这是可行的。这个算法的发明者们最终能得到这种算法是基于一系列更加复杂的算法例如神经语言模型后来的Word2Vec Skip-Gram模型,再后来才有了这种算法

情感分类(Sentiment Classification)可以使用RNN进行处理,是多输入对应单个输出的RNN结构

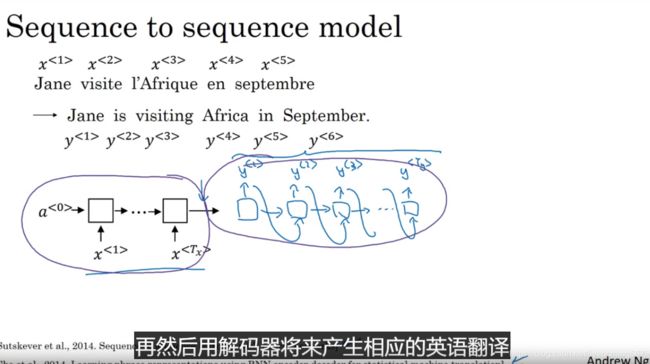
sequence to sequence model
通过对输入x建立编码器(在语言翻译系统中可以是gru或lstm),对输出y建立解码器,可以完成对句子不同语言的翻译。
当然如果是x输入的是图片,编码器就是cnn的算法,y输出的是语言序列,可以实现
束集搜索法(Beam Search)
在选择解码器中y的时,通常选择束集搜索(beam search)方法,b为束集选择的个数,每次选择b个概率最大的词来保留。当b=1时,束集搜索法是贪婪(greedy search),但是并不一定能够选择最优的结果。举例如下

在束集搜索法(beam search)过程句子长的联合概率是很多个小于1的值相乘,会是非常小的值,甚至超出在计算机中存储的浮点型的数据的限制,因此可用把筛选的概率做些调整
1、对联合概率密度的取对数
2、长度的α次幂的倒数降低单个概率的惩罚,α=1,就是完全规范化的长度,α=0,就是完全没有规范化。α在0-1之间

机器翻译系统的误差分析
机器翻译系统有两部分构成,一部分是RNN的编码器,一部分是beam search解码器,如果有一个人工翻译的更好的结果,可以通过对比p(ystar|x)和p(yhat|x)进行对比进行误差分析:
如果p(ystar|x)大于p(yhat|x),说明解码器存在的误差更大,否则是编码器存在的误差更大。
以此来确定调整模型的方向

Bleu Score (optional):BLEU算法能够自动计算出一个指数 来描述机器翻译的好坏,BLEU是“双语评估替补“的。BLEU的提出动机是,在任何需要人类来评估机器翻译系统的地方。BLEU能给出一个 人类评估结果的替补。
一元语法中(针对单独单词),bleu指数的分子是单词最多出现的次数(双语评估替补两个参考结果中最大的数),分母是该单词在机器翻译结果中出现的次数,举例如下:

二元语法模型中:分子是两个单词的词组出现的上线次数,分母为机器翻译中词组出现的次数
n元语法模型中同理类似。
bleu指数是对一元到n元语法准确率的加和的平均值求自然对数的幂次方,然后通过bp进行惩罚,计算方法如下:

注意力模型(attention model):把注意力集中在翻译字段前后的几个字上,这个模型与人类翻译句子过程更加类似。具体计算过程如下:
1、根据正向传播和反向传播计算得到单词对应的a
2、每个单词的注意力权重的单词alph,与单词对应的a
3、s(t-1)与ct计算出来e
4、根据et预测分类结果y

GTC(connectionist temporal classification)模型:
对语音识别模型 的工作方式有一个初步的理解基于注意力的模型和CTC模型 都是可行的方案 ,这展示了两种不同的方法来构建这些系统
GTC:通过折叠 没有被空白隔开的重复字,例如它实际上把序列折叠成 t, h, e, 然后空格, q, 这使你的网络 重复同样字符很多次,有1000个输出序列所以,插入一堆空白字符,最终仍然能输出很多更短的文字串

触发字检测:在对应触发字的音频的输入标记为1,其他输入标记为0的RNN进行训练,但是训练结果中1数量非常少,0数量非常多,会导致分布不均衡,因此触发词之后一定时间段内标记为1.
