【''I'm Feeling Lucky'' baidu 查找】 详细解析
目录
1,确保所需的模块全部安装
2,找到所用浏览器的User-Agent 信息
3,完整代码块
4,存在的问题
1,确保所需的模块全部安装
该程序用了sys, webbrowser, requests, pyperclip, bs4 模块,除了前两个是python自带的,后三个都需要自己安装,若不会,可参考:通过命令行安装Python 的第三方模块。(注意bs4 模块名字实际叫 beautifulsoup4)
2,找到所用浏览器的User-Agent 信息
打开自己用的浏览器,我用的360极速浏览器,然后按F12,调出开发者模式,随便进行一点操作,找到如下的User-Agent
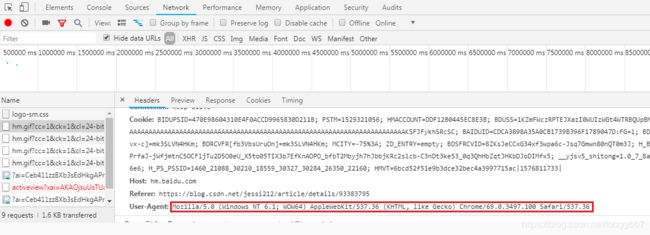
将找到的信息传入headers
head ={'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
res = requests.get(r'https://www.baidu.com/s?wd=' + content, headers=head) #content为要查找的内容若没有这个headers,虽然可以通过 webbrowser.open(r'https://www.baidu.com/s?wd=' + content) 正确打开网页,但是通过requests.get(r'https://www.baidu.com/s?wd=' + content)不能获得正确的 html 信息,获取的信息打印出来显示如下:

3,完整代码块
#!python3
import requests, pyperclip, sys, webbrowser, bs4
if len(sys.argv)>1:
content = ' '.join(sys.argv[1:])
else:
content = pyperclip.paste()
print('baiduing...')
# webbrowser.open(r'https://www.baidu.com/s?wd=' + content)
head ={'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
res = requests.get(r'https://www.baidu.com/s?wd=' + content, headers=head)
res.raise_for_status() #check if requests.get() success
res.encoding='utf-8'
#res.text is html format
soup = bs4.BeautifulSoup(res.text, features = 'html.parser')
linkElems = soup.select('div.result h3.t > a')
numOpen = min(5, len(linkElems))
for i in range(numOpen):
webbrowser.open(linkElems[i].get('href'))复制 python 在剪贴板,然后运行程序,浏览器成功打开了百度搜索 python 后的五个链接。
4,存在的问题
成功了后再试一次发现又不能正确的得到结果,出现上面的百度安全验证,然后修改代码中的一行为:
res = requests.get(r'https://www.baidu.com/s?wd=' + content, headers=head, verify=False)发现又成功实现了一次,但再试一次就又出现百度安全验证,估计是百度的反爬虫机制,还未解决,有懂的大佬希望指教。