Java文本处理11-根据句长进行排序
1、任务简介
本节任务是在上面任务的基础之上进行的,在分句完成后,我们可以根据句子的长短(这里指句子的汉字数)对句子进行排序输出,本节的第一个程序是根据TreeMap的Key值进行升序排序,第二个程序是根据TreeMap的Value值进行降序排序(关于TreeMap的排序方法在《Java文本处理6-统计文本中汉字的出现次数(降序排序)》中已经有所涉及)。
2、基本任务和代码
(1)任务1
1)任务内容
对句子进行分句,然后根据句子包含的汉字数使用TreeMap的Key值进行升序排序,并将句子的总数及句子的平均长度也打印出来。
2)具体思路
(1)首先需要使用InputStreamReader类和BufferedReader类实现文本的读取,由于我使用的文本文档均为utf-8编码,所以还需要指定编码格式为utf-8;
(2)然后需要定义一个空的字符串变量,在对文本逐行读出后将读出的内容追加到该空字符串后;
(3)定义一个TreeMap集合用于后续的排序,由于TreeMap中的Key默认为升序排序,所以将其定义为TreeMap
(4)逐行读出文档,然后使用for循环对该行中的每一个字符进行遍历,使用toString()方法得到每一个字符,再使用if语句和matches()方法检测字符是否为汉字,若匹配则对指定的变量进行自增,求出每一句的汉字数和总的汉字数;
(5)再使用if语句和equals()方法字符是否为“。” “!”和“?”三种符号之一,若为其中之一则句子数+1,并且需要将该句的汉字数和内容添加到TreeMap集合中,再将统计变量重置从而满足下一句的循环统计;
(6)最后使用keySet()方法获取TreeMap集合的键值对,然后使用get(key)方法获取Key对应的Value值,将句子的内容和汉字数打印出来。
3)任务代码
程序保存为juzi3.java,代码如下:
import java.io.*;//导入java.io包中的所有类
import java.util.*;//导入java.util包中的所有类
public class juzi3 {//类名
public static void main(String[] args) {//程序主函数
try {//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
Scanner s = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
System.out.println("请输入想要打开的文本文档:");//输入提示信息
String a = s.nextLine();//定义字符串变量,并赋值为用户输入的信息
//创建类进行文件的读取,并指定编码格式为utf-8
InputStreamReader read = new InputStreamReader(new FileInputStream(a),"utf-8");
BufferedReader in = new BufferedReader(read);//可用于读取指定文件
StringBuffer b = new StringBuffer();//定义一个字符串变量,便于后续进行内容追加的操作
String str = null;//定义一个字符串类型变量
String d = null;//定义一个字符串类型变量
String g = "";//定义一个字符串类型变量
double e = 0;//定义一个double型变量,用于统计总句子数
double c1 = 0;//定义一个double型变量,用于统计总汉字数
int c2 = 0;//定义一个int型变量,用于统计每一句包含的汉字数
TreeMap<Integer,String> tm=new TreeMap<Integer,String>();//定义一个TreeMap集合
while((str = in.readLine()) != null) {//readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
b.append(str);//将该行内容追加到字符串b的后面
for (int j = 0; j < str.length(); j++) {//for循环的条件,当j小于该行长度时就一直循环并自增
d = Character.toString(str.charAt(j));//返回一个字符串对象
g += d;//连接两个字符串
if (d.matches("[\\u4e00-\\u9fa5]")) {//if语句的条件,判断是否为汉字
c1++;//若为汉字则c1自增
c2++;//若为汉字则c2自增
}
if (d.equals("。")||d.equals("?")||d.equals("!")) {//if语句的条件,判断是否为句子
e++;//若为一句则e自增一次
tm.put(c2,g);//在TreeMap中添加值
g = "";//重置统计变量
c2 = 0;//重置统计变量
}
}
}
in.close();//关闭流
System.out.println("对句子进行升序排序:"+"\n");
Iterator<Integer>it = tm.keySet().iterator();//获取tm的key值并迭代
while (it.hasNext()) {//检查序列中是否含有元素,若有则为true
int key = it.next();//定义变量获取元素
System.out.println(tm.get(key)+" 本句包含"+key+"个汉字");//输出排序结果
}
double f = c1/e;//计算文本平均句长
System.out.println("该文本共有"+(int)e+"个句子");//输出总的句子数
System.out.println("该文本共有"+(int)c1+"个汉字");//输出总的汉字数
System.out.println("该文本平均句长为"+f);//输出平均句长
} catch (IOException e) {//当try代码块有异常时转到catch代码块
e.printStackTrace();//printStackTrace()方法是打印异常信息在程序中出错的位置及原因
}
}
}
4)运行结果
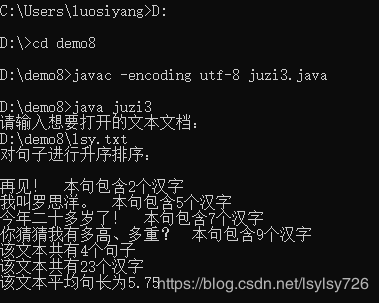
所有文件均保存在路径D:\demo8下,对一个格式为utf-8的简单文本进行操作,该文本文档命名为 lsy.txt,内容如下:

从中可以看出该文本文档中共有4句话,然后在命令行中对程序进行编译,并运行程序读取该txt文档,排序及计算结果如下:
(2)任务2
1)任务内容
对句子进行分句,然后根据句子包含的汉字数使用TreeMap的Value值进行降序排序,并将句子的总数及句子的平均长度也打印出来。
2)具体思路
(1)首先需要使用InputStreamReader类和BufferedReader类实现文本的读取,由于我使用的文本文档均为utf-8编码,所以还需要指定编码格式为utf-8;
(2)然后需要定义一个空的字符串变量,在对文本逐行读出后将读出的内容追加到该空字符串后;
(3)定义一个TreeMap集合用于后续的排序,由于需要使用TreeMap中的Value值进行降序排序,所以将其定义为TreeMap
(4)逐行读出文档,然后使用for循环对该行中的每一个字符进行遍历,使用toString()方法得到每一个字符,再使用if语句和matches()方法检测字符是否为汉字,若匹配则对指定的变量进行自增,求出每一句的汉字数和总的汉字数;
(5)再使用if语句和equals()方法字符是否为“。” “!”和“?”三种符号之一,若为其中之一则句子数+1,并且需要将该句的汉字数和内容添加到TreeMap集合中,再将统计变量重置从而满足下一句的循环统计;
(6)由于需要使用TreeMap中的Value值进行降序排序,所以需要使用Collections.sort()构造一个排序比较器,构造排序比较器思路大体如下:
首先,由于Map和Collections是同级别的,不能像List排序那样直接用Collections.sort()进行排序,故需要将map转换为list;
然后,使用Collections.sort()方法对这个list进行降序排序,其基本格式可以参考链接:点此查看;
最后,遍历该list然后输出降序排序的结果;
3)任务代码
程序保存为juzi4.java,代码如下:
import java.io.*;//导入java.io包中的所有类
import java.util.*;//导入java.util包中的所有类
import java.util.Map.Entry;//导入java.util.Map包中的Entry类
public class juzi4 {//类名
public static void main(String[] args) {//程序主函数
try {//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
Scanner s = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
System.out.println("请输入想要打开的文本文档:");//输入提示信息
String a = s.nextLine();//定义字符串变量,并赋值为用户输入的信息
//创建类进行文件的读取,并指定编码格式为utf-8
InputStreamReader read = new InputStreamReader(new FileInputStream(a),"utf-8");
BufferedReader in = new BufferedReader(read);//可用于读取指定文件
StringBuffer b = new StringBuffer();//定义一个字符串变量b,便于后续进行内容追加的操作
String str = null;//定义一个字符串类型变量
String d = null;//定义一个字符串类型变量
String g = "";//定义一个字符串类型变量
double e = 0;//定义一个double型变量,用于统计句子数
double c1 = 0;//定义一个double型变量,用于统计总汉字数
int c2 = 0;//定义一个int型变量,用于统计每一句包含的汉字数
TreeMap<String,Integer> tm=new TreeMap<String,Integer>();//定义一个TreeMap集合
while((str = in.readLine()) != null) {//readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
b.append(str);//将该行内容追加到字符串b的后面
for (int j = 0; j < str.length(); j++) {//for循环的条件,当j小于该行长度时就一直循环并自增
d = Character.toString(str.charAt(j));//返回一个字符串对象
g += d;//连接两个字符串
if (d.matches("[\\u4e00-\\u9fa5]")) {//if语句的条件,判断是否为汉字
c1++;//若为汉字则c1自增
c2++;//若为汉字则c1自增
}
if (d.equals("。")||d.equals("?")||d.equals("!")) {//if语句的条件,判断是否为句子
e++;//若为一句则e自增一次
tm.put(g,c2);//在TreeMap中添加值
g = "";//重置统计变量
c2 = 0;//重置统计变量
}
}
}
in.close();//关闭流
System.out.println("对句子进行降序排序:"+"\n");
List<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(tm.entrySet());//将map转换为list便于进行排序
//构造一个排序比较器
Collections.sort (list,new Comparator<Map.Entry<String,Integer>>() {//使用Collections.sort()方法对这个list进行排序
public int compare(Entry<String,Integer> o1,Entry<String,Integer> o2) {
//实现降序排序
int z = o2.getValue()-o1.getValue();
return z;
}
});
for(Map.Entry<String,Integer> mapping:list) {//遍历list
System.out.println(mapping.getKey()+" 本句包含"+mapping.getValue()+"个汉字"); //输出降序排序的结果
}
double f = c1/e;//计算文本平均句长
System.out.println("该文本共有"+(int)e+"个句子");//输出总的句子数
System.out.println("该文本共有"+(int)c1+"个汉字");//输出总的汉字数
System.out.println("该文本平均句长为"+f);//输出平均句长
} catch (IOException e) {//当try代码块有异常时转到catch代码块
e.printStackTrace();//printStackTrace()方法是打印异常信息在程序中出错的位置及原因
}
}
}
4)运行结果
所有文件均保存在路径D:\demo8下,对任务1中使用到的文本文档lsy.txt进行操作,结果如下:

3、总结
通过这两个程序可以对文本的句长进行排序,并将结果输出。但是在使用TreeMap的Key值进行升序排序时只可以对一些简单文本进行排序,对于一些复杂文本来说,如果句子包含的汉字数相同则只会输出其中的一个句子,这个弊端目前我还没有找到解决的办法,如果以后我找到了解决办法会再来更新该博客,文中的不足之处还请大家指正。