监督学习、无监督学习、半监督学习概述
前言
机器学习分为:监督学习,无监督学习,半监督学习(也可以用hinton所说的强化学习)等。
在这里,主要理解一下监督学习和无监督学习。
监督学习(supervised learning)
从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
监督学习是训练神经网络和决策树的常见技术。这两种技术高度依赖事先确定的分类系统给出的信息,对于神经网络,分类系统利用信息判断网络的错误,然后不断调整网络参数。对于决策树,分类系统用它来判断哪些属性提供了最多的信息。
常见的有监督学习算法:回归分析和统计分类。最典型的算法是KNN和SVM。
有监督学习最常见的就是:regression&classification
Regression:Y是实数vector。回归问题,就是拟合(x,y)的一条曲线,使得价值函数(costfunction) L最小

Classification:Y是一个有穷数(finitenumber),可以看做类标号,分类问题首先要给定有lable的数据训练分类器,故属于有监督学习过程。分类过程中cost function l(X,Y)是X属于类Y的概率的负对数。

其中fi(X)=P(Y=i/X)。
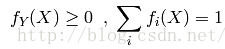
无监督学习(unsupervised learning)
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。非监督学习有两种思路。第一种思路是在指导Agent时不为其指定明确分类,而是在成功时,采用某种形式的激励制度。需要注意的是,这类训练通常会置于决策问题的框架里,因为它的目标不是为了产生一个分类系统,而是做出最大回报的决定,这种思路很好的概括了现实世界,agent可以对正确的行为做出激励,而对错误行为做出惩罚。
无监督学习的方法分为两大类:
(1) 一类为基于概率密度函数估计的直接方法:指设法找到各类别在特征空间的分布参数,再进行分类。
(2) 另一类是称为基于样本间相似性度量的简洁聚类方法:其原理是设法定出不同类别的核心或初始内核,然后依据样本与核心之间的相似性度量将样本聚集成不同的类别。
利用聚类结果,可以提取数据集中隐藏信息,对未来数据进行分类和预测。应用于数据挖掘,模式识别,图像处理等。
PCA和很多deep learning算法都属于无监督学习。
两者的不同点
1. 有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
2. 有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
3. 非监督学习方法在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。
这一点是比有监督学习方法的用途要广。 譬如分析一堆数据的主分量,或分析数据集有什么特点都可以归于非监督学习方法的范畴。
4. 用非监督学习方法分析数据集的主分量与用K-L变换计算数据集的主分量又有区别。后者从方法上讲不是学习方法。因此用K-L变换找主分量不属于无监督学习方法,即方法上不是。而通过学习逐渐找到规律性这体现了学习方法这一点。在人工神经元网络中寻找主分量的方法属于无监督学习方法。
何时采用哪种方法
简单的方法就是从定义入手,有训练样本则考虑采用监督学习方法;无训练样本,则一定不能用监督学习方法。但是,现实问题中,即使没有训练样本,我们也能够凭借自己的双眼,从待分类的数据中,人工标注一些样本,并把它们作为训练样本,这样的话,可以把条件改善,用监督学习方法来做。对于不同的场景,正负样本的分布如果会存在偏移(可能大的偏移,可能比较小),这样的话,监督学习的效果可能就不如用非监督学习了。
---------------------------------------------------------------
1. 介绍
1.1 什么是半监督学习
所给的数据有的是有标签的,而有的是没有标签的。常见的两种半监督的学习方式是直推学习(Transductive learning)和归纳学习(Inductive learning)。
直推学习(Transductive learning):没有标记的数据是测试数据,这个时候可以用test的数据进行训练。这里需要注意,这里只是用了test数据中的feature而没有用label,所以并不是一种欺骗的方法。
归纳学习(Inductive learning):没有标签的数据不是测试集。
在实际中,是使用直推学习还是归纳学习主要取决于你在训练自己的模型时,你的测试数据是否已经给出了。如果已经给出了,那么是可以使用的。
1.2 为什么使用半监督学习
(1) 实际中缺乏的不是数据,而是带标签的数据。给收集的数据进行标记是昂贵的。
(2) 在我们的一生中都在进行半监督学习。
1.3 为半监督学习是有帮助的
虽然没有标签的数据并不会提供标签,但是它提供了关于数据分布的一种信息。即没有标签的数据的分布会给我们提供一些信息,但是所给出的信息通常实在一些假定的条件下实现的。也就是说假设决定了半监督学习是否可以使用!
1.4 本文的主要内容
本文的主要内容是四个部分:生成模型中的半监督学习、低密度分离假设、平滑性假设、更好的表示。本文将介绍前三节内容,最后一部分内容将在之后的博客中介绍。
2. 生成模型中的半监督学习(Semi-supervised Learning for Generative Model)
在监督学习中,生成模型的数据有 C1C1 和 C2C2 两类数据组成,我们统计数据的先验概率 P(C1)P(C1) 和 P(x|C1)P(x|C1) 。假设每一类的数据都是服从高斯分布的话,我们可以通过分布得到参数均值μ1,μ2μ1,μ2和方差ΣΣ。
利用得到参数可以知道P(C1),P(x|C1),μ1,μ2,ΣP(C1),P(x|C1),μ1,μ2,Σ,并利用这些参数计算某一个例子的类别
在非监督学习中,如下图所示,在已知类别的数据周围还有很多类别未知的数据,如图中绿色的数据。
这个时候如果仍在使用之前的数据分布明显是不合理的们需要重新估计数据分布的参数,这个时候可能分布式一个类似于圆形的形状。这里就需要用为标签数据来帮助估计新的”P(C1),P(x|C1),μ1,μ2,ΣP(C1),P(x|C1),μ1,μ2,Σ”。具体可以采用如下的EM算法进行估计
首先对参数进行初始化,之后利用参数计算无标签数据的后验概率;然后利用得到的后验概率更新模型参数,再返回step1,循环执行直至模型收敛。这个算法最终会达到收敛,但是初始化对于结果的影响也很大。
3. 低密度分离(Low-density Separation)
低密度分离假设就是假设数据非黑即白,在两个类别的数据之间存在着较为明显的鸿沟,即在两个类别之间的边界处数据的密度很低(即数据量很好)。
3.1 自训练(Self-training)
自训练的方法十分直觉,它首先根据有标签的数据训练出一个模型,将没有标签的数据作为测试数据输进去,得到没有标签的数据的一个为标签,之后将一部分的带有伪标签的数据转移到有标签的数据中,在进行训练,循环往复。其中选取哪一部分的伪标签数据转移至有标签数据需要自己定义,甚至可以自己提供一个权重。具体的过程如下图所示
在这里还有两个问题需要注意,首先自训练的方法是否可以用到回归问题中?答案是否定的。因为即使加入新的数据对于模型也没有什么改进。
之前讲的生成模型与后来讲的自训练模型之间是很相似的,区别在于生成模型采用的是软标签,而自训练采用的是硬标签,那么问题来了,自训练模型是都可以使用软标签呢?答案是否定的,如下图所示
因为不对标签进行改变的话,将这些放入带标签的数据中对于数据的输出一点改进都没有,输出的还是原来的数据。
3.2 基于熵的正则化
这种方法是自训练的进阶版,因为之前如果直接根据用有标签数据训练出来的模型直接对无标签数据进行分类会有一些武断,这里采用一种更严密的方法。
因为在低密度假设中认为这个世界是非黑即白的,所以无标签数据的概率分布应该是区别度很大的,这里使用熵来表示。将其加入损失函数中个可以看到,这个实际上可以认为是一项正则化项,所以也叫基于熵的正则化。训练的话,因为两个部分都是可微分的,所以直接使用梯度下降就可以进行训练。
4. 平滑性假设
白话性假设:如果输入 xx 是相似的,那么它们的标签值 ŷ y^ 同样应该是相似的。但是这样的假设不够精确,所以有下面的严格的假设:
(1) xx 的分布是不均匀的,在有的地方是稀疏的,在有的地方是密集的
(2) 如果在高密度区域比较相近,那么这两个数据具有相同的标签。
可以如下图进行进一步解释
在距离上虽然 x2x2 与 x3x3 的距离更接近,但是 x2x2 与 x1x1 位于同一个高密度的区域中。可以认为同一个高密度区域之间的数据可以很好的接触连接,具有相同的标签值,而不同的高密度区域无法相互接触,所以标签值不相同。
4.1 先聚类再标注
一种直观的方法是首先对数据进行聚类,看没有标签的数据落在哪一个部分,然后对其及进行标注,如下图所示
但是如果是对图像进行操作的话,无法单纯用像素对图像进行聚类,这样的聚类方法往往是不好的,这个时候可以采用 deep autoencoder 的方法提取图像的特征,利用特征对图像进行聚类,会得到较好的结果。
4.2 基于图的方法
将所有的数据点建成一个图,如果在图上两个点之间可以连通,那么他们之间标签就是相同的。那么如何形成图呢,有些图是天然的,比如说网页之间的连接,或者论文之间的相互引用,但有的时候需要自己建图。