【python爬虫专项(11)】正则表达式(1)—— 快速上手
什么是正则表达式?
概念
正则表达式,又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串
python正则表达式工具包:re
系统自带,不需要安装,可以直接导入

爬虫中正则表达式的作用是什么?
“模糊匹配”
requests+BeautifulSoup爬虫逻辑中,在标签识别基础上,匹配里面的信息 → 处理文本内容、提取字段数据采集后,在pandas中对字段进行处理
示例

显然里面前三个格式上是有统一的样式的,而最后一个明显是来捣乱的,因此要提取里面的数据,可以使用下面的方式
m = r'(\D*)的银行存款为(\d*万)'
for i in lst:
print(re.match(m,i))
输出的结果为:(其中r后面的字符代表原生字符,\D代表非数字字符,\d代表数字字符,*代表有0或n个字符)

如果直接使用re.match()方法,会返回一个Match对象,上面加上括号的目的就是为了获取满足括号内要求的值,如下
for i in lst:
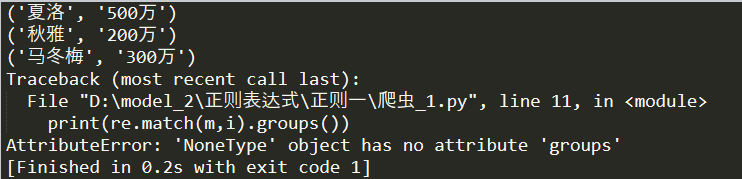
print(re.match(m,i).groups())
输出的结果为:(满足条件的话,会以元祖的形式将数据返回,不满足的数据会报错)
为了防止系统报错,一般是要进行匹配成功判断,然后再进行匹配成功的结果输出,如下
for i in lst:
# print(re.match(m,i).groups())
match_result = re.match(m,i)
dic = {}
if match_result:
dic['姓名'] = match_result.group(1)
dic['存款'] = match_result.group(2)
else:
continue
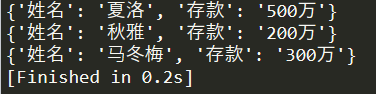
print(dic)
输出的结果为:
通过上面的示例,大致可以把正则表达式的使用步骤归纳为:【目标数据】–> 【模式设置】–> 【进行匹配】–> 【数据提取】–> 【数据输出】

re.match()方法讲解
1)re.match(pattern, string, flags=0) → 尝试从字符串的 起始位置 匹配一个模式,如果不是 起始位置 匹配成功的话,match()就返回none
pattern:匹配的正则表达式
string:要匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
2)返回结果
匹配成功re.match方法返回一个匹配的对象,否则返回None
3)可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
group()/group(0) → 返回成功匹配的内容
group(num) → 返回成功匹配的内容中第num个小组的字符
groups() → 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号
示例
以上面列表里的第一个数据为例,对上面的内容进行一一输出(前两个内容已经在前面讲解过了,下面主要是对第三个内容进行输出)

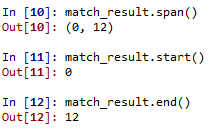
4)通过span()方法用于以元祖形式返回匹配的起始位置和结束位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
start() 返回匹配开始的位置
end() 返回匹配结束的位置
示例
修饰符 - 可选标志
1)概念
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志;多个标志可以通过按位 OR(|) 它们来指定
2)修饰符
| 名称 | 作用 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.U | 使 . 匹配包括换行在内的所有字符 |
| re.S | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
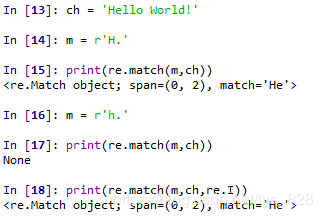
示例
至此,正则表达式的快速上手的内容就介绍完毕了,下面介绍具体的匹配模式