【python爬虫专项(27)】拉勾网数据采集(关键词网址不发生变化)
拉勾网登陆后,选择某城市,搜索任意关键字,采集岗位信息数据
起始参考网址:全国数据分析岗位招聘
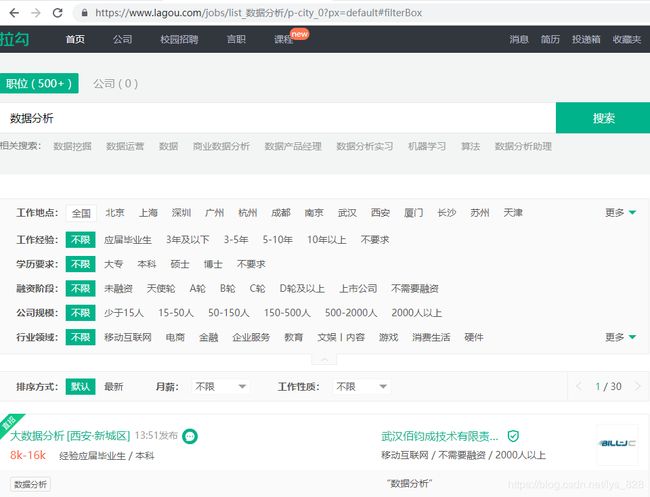
前一篇是搜索关键词网址发生变化的情况,接下来就处理搜索关键词不发生变化情况下的数据爬取,就以上一篇提及的‘数据分析’作为关键词,进行相同字段数据的爬取
爬虫逻辑:【登陆】-【访问页面 + 采集岗位信息 - 翻页】
1)函数式编程
函数1:login(u,username,password) → 【登陆】
u:起始网址
username:用户名
password:密码
函数2:get_data(ui,table,page_n) → 【访问页面 + 采集岗位信息 - 翻页】
ui:数据页面网址
table:mongo集合对象
page_n:翻页次数
2)上一篇文章是以第一种方式获取字段的内容,那么这一篇就使用第二种方式
区别在于方法一是找到了字段内容所在的【li】标签,然后再【li】标签内部查找对应标签的信息,方法二是直接在全局的范围里面,直接通过xpath定位,然后进行遍历输出
前期准备和封装第一个函数都是和之前的一样
import re
import time
import random
import pymongo
from selenium import webdriver
def login(u,username,password):
browser.get(u)
browser.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click()
#选择全国站
browser.find_element_by_xpath('//*[@id="lg_tbar"]/div/div[2]/ul/li[3]/a').click()
#点击登录按钮
user_name = browser.find_element_by_xpath('/html/body/div[2]/div[1]/div/div/div[2]/div[3]/div[1]/div/div[1]/form/div[1]/div/input')
#用户名
pass_word = browser.find_element_by_xpath('/html/body/div[2]/div[1]/div/div/div[2]/div[3]/div[1]/div/div[1]/form/div[2]/div/input')
user_name.clear()
pass_word.clear()
#清空里面的内容
user_name.send_keys(username)
pass_word.send_keys(password)
#输入个人信息
browser.find_element_by_xpath('/html/body/div[2]/div[1]/div/div/div[2]/div[3]/div[2]/div[2]/div[2]').click()
print(browser.current_url)
#点击登录按钮并返回当前页面的网址
if __name__ == '__main__':
browser = webdriver.Chrome()
login('https://www.lagou.com/', 'xxx','xxx')
这里完成拉勾网账号的登录,和封装第一个函数
相应字段内容的获取和时间问题
前一个函数的功能,只是会进入到登录之后的拉勾网界面,这时候,可以将页面跳转到“数据分析”为关键的页面上,可以执行如下代码,为了防止浏览器未反应过来,这一部分要给系统一个反应时间(包含了之前的手动输入验证码的时间,建议是15s)
time.sleep(15)
browser.get('https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/p-city_0?px=default#filterBox')
#跳转到‘数据分析’搜索的界面
browser.find_element_by_xpath('/html/body/div[6]/div/div[2]').click()
#这一步是因为会弹出来一个广告,因此需要过滤掉
然后就是进入了以"数据分析"为关键字的招聘信息的界面,这时候先选择第一页的内容进行爬虫试错,如下:
dic = {}
dic['岗位名称'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/a/h3').text
dic['发布时间'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/span').text
dic['公司名称'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[1]/div[1]/div[2]/div[1]/a').text
info1 = re.split(r'[ /]+', browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[2]/div').text)
dic['薪酬'] = info1[0]
dic['经验水平'] = info1[1]
dic['学历要求'] = info1[2]
info2 = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[1]/div[1]/div[2]/div[2]').text.split(' / ')
dic['企业类型'] = info2[0]
dic['融资情况'] = info2[1]
dic['公司规模'] = info2[2]
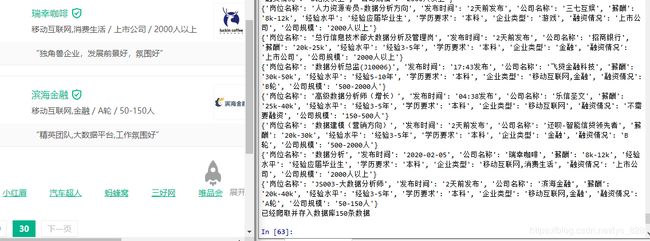
print(dic)
输出的结果是:

进行数据验证,可以确定是需要爬取的数据:
接下来就可以配置数据库和进行第二个函数的封装了,首先是进行数据库的设置(数据库的创建与命名以及保存数据的集合)
myclient = pymongo.MongoClient('https://localhost:27017/')
db = myclient['拉勾网数据(2)']
datatable = db['data']
三行代码配置好数据库的问题,接着就是封装第三个函数,就是遍历输出加上翻页的功能(模仿人的操作)
def get_data(page_num,table):
count = 0
for j in range(page_num):
for i in range(1,16):
dic = {}
dic['岗位名称'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[{i}]/div[1]/div[1]/div[1]/a/h3').text
dic['发布时间'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[{i}]/div[1]/div[1]/div[1]/span').text
dic['公司名称'] = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[{i}]/div[1]/div[2]/div[1]/a').text
info1 = re.split(r'[ /]+', browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[{i}]/div[1]/div[1]/div[2]/div').text)
dic['薪酬'] = info1[0]
dic['经验水平'] = info1[1]
dic['学历要求'] = info1[2]
info2 = browser.find_element_by_xpath(f'//*[@id="s_position_list"]/ul/li[{i}]/div[1]/div[2]/div[2]').text.split(' / ')
dic['企业类型'] = info2[0]
dic['融资情况'] = info2[1]
dic['公司规模'] = info2[2]
table.insert_one(dic)
print(dic)
count += 1
browser.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[6]'.click()
print(n)
get_data(3,datatable)
运行结果是,程序可以正常运行,也会把数据存放到数据库,经过检查核对发现,并不是我们所要爬取的前三页数据,只是爬取了第一页后,浏览器翻页翻到了最后一页(第30页),因此尝试着将3改成10 ,最后输出的数据全是第30页的招聘信息
究其原因,发现,原来“下一页”这个按钮的出现的位置有一定的差异,自然就导致其对应的标签位置有所改变,由上面直接输出30页,可以推测第一页的位置和最后一页的位置是相同的,下面就开始查找
//*[@id="s_position_list"]/div[2]/div/span[6] #第一页
//*[@id="s_position_list"]/div[2]/div/span[7] #第二页
//*[@id="s_position_list"]/div[2]/div/span[8] #第三页
//*[@id="s_position_list"]/div[2]/div/span[9] #第四页
//*[@id="s_position_list"]/div[2]/div/span[9] #第五页
//*[@id="s_position_list"]/div[2]/div/span[9] #第二十七页
//*[@id="s_position_list"]/div[2]/div/span[8] #第二十八页
//*[@id="s_position_list"]/div[2]/div/span[7] #第二十九页 这一页翻完就是最后一页了
//*[@id="s_position_list"]/div[2]/div/span[6] #第三十页
看一下,“下一页”按钮的布置情况:
1)第一页中,“下一页”按钮的位置

2)第三十页中,“下一页”按钮的位置(可以看出是与第一页相同的)

3)第二页中,“下一页”按钮的位置(多一个按钮)

4)第三页中,“下一页”按钮的位置(又多一个按钮)
![]()
5)第四页中,“下一页”按钮的位置(又多一个按钮)

6)第五页中,“下一页”按钮的位置(和第4块的一致了,之后的都是一致的)

7)第二十八页中,“下一页”按钮的位置(开始少了一块)

8)第二十九页中,“下一页”按钮的位置(又少一个按钮)
![]()
9)就是第三十页,和第一页的位置一样,因此就可以看出规律,从第一页至第四页逐渐加一,最后四页逐渐减一
最终的修改代码为:
if j < 3:
browser.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[{}]'.format(6+j)).click()
sleeptime = 5
print('程序正在休息......',sleeptime)
time.sleep(sleeptime)
else:
browser.find_element_by_xpath(f'//*[@id="s_position_list"]/div[2]/div/span[{9}]').click()
sleeptime = 5
print('程序正在休息......',sleeptime)
time.sleep(sleeptime)
这里的停止时间一定需要给够,不然页面没有及时刷新成功,就会导致系统报错,因为每一页的“下一页”翻页按钮都和程序的下一步执行有关系,注意爬取的页数这里设置,如果要设置爬取的页数多少的话不可以超过27,这也是“下一页”按钮设置的规律决定的
最终的输出结果
进行登录界面和跳转到以“数据分析”为关键字的招聘页面
最后的数据爬取过程如下:(这里选取前十页进行数据爬取)