【python数据分析(14)】Pandas实现csv和excel文件数据读取和保存,制作透视表(pivot_table)和交叉表(crosstab)
1. csv和excel文件的读取与保存
1.1 读取和保存csv文件
1) 读取csv文件,加载数据。 pd.read_csv()括号内加上文件的路径即可,里面如果文件未能正常加载,可以通过调整括号内的参数
import os
os.chdir(r'C:\Users\86177\Desktop')
import pandas as pd
df = pd.read_csv('demo.csv')
print(df)
–> 输出的结果为:
date key values
0 2017/5/1 a 5.886424
1 2017/5/2 b 9.906472
2 2017/5/3 c 8.617297
3 2017/5/1 d 8.972318
4 2017/5/2 a 7.990905
5 2017/5/3 b 8.131856
6 2017/5/1 c 2.823731
7 2017/5/2 d 2.394605
8 2017/5/3 a 0.667917
2) 保存csv文件,存储数据。 df.to_csv()括号内加上文件的路径即可,括号内部也有很多参数可供选择
df.to_csv('demo_1.csv')
–> 输出的结果为:(注意有时候直接存为csv文件可能导致乱码,建议一般存为excel文件,然后再转存为csv文件)
1.2 读取和保存Excel文件
1) 读取Excel文件,可以读取.xls和.xlsx文件
data = pd.read_excel('demo.xlsx')
print(data)
–> 输出的结果为:(原列表的NaN,会认定为空值)
A B C
0 1 3 1.0
1 2 3 1.0
2 2 4 NaN
3 2 4 1.0
4 2 4 1.0
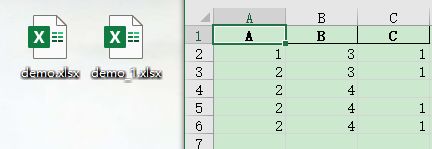
2) 保存Excel文件
data.to_excel('demo_1.xlsx', index=False)
–> 输出的结果为:(index=False,去掉前面的索引标签,输出会把NaN数据当空白数据处理)
2. 制作透视表和交叉表
2.1 制作透视表pivot_table
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True, margins_name=‘All’)
data:DataFrame对象
values:要聚合的列或列的列表
index:数据透视表的index,从原数据的列中筛选
columns:数据透视表的columns,从原数据的列中筛选
aggfunc:用于聚合的函数,默认为numpy.mean,支持numpy计算方法(下面的’sum’可以换成np.sum)
数据以上面的demo.csv中的数据为例
import os
os.chdir(r'C:\Users\86177\Desktop')
import pandas as pd
df = pd.read_csv('demo.csv')
print(pd.pivot_table(df, values = 'values', index = 'date', columns = 'key', aggfunc='sum'))
–> 输出的结果为:
key a b c d
date
2017/5/1 5.886424 NaN 2.823731 8.972318
2017/5/2 7.990905 9.906472 NaN 2.394605
2017/5/3 0.667917 8.131856 8.617297 NaN
如果分别以date、key共同做数据透视,值为values:统计不同(date,key)情况下values的平均值
print(pd.pivot_table(df, values = 'values', index = ['date','key'], aggfunc=len))
–> 输出的结果为:(aggfunc=len(或者'count'):计数,前者是浮点型,后者是整型)
values
date key
2017/5/1 a 1.0
c 1.0
d 1.0
2017/5/2 a 1.0
b 1.0
d 1.0
2017/5/3 a 1.0
b 1.0
c 1.0
2.2 制作交叉表crosstab
pd.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, dropna=True, normalize=False)
默认情况下,crosstab计算因子的频率表,比如用于str的数据透视分析,这里以demo.xlsx文件中的数据做示例
data = pd.read_excel('demo.xlsx')
print(pd.crosstab(data['A'],data['B']))
–> 输出的结果为:(如果crosstab只接收两个Series,它将提供一个频率表。用A的唯一值,统计B唯一值的出现次数)
B 3 4
A
1 1 0
2 1 3
normalize:默认False,将所有值除以值的总和进行归一化 → 为True时候显示百分比(不是百分数)
print(pd.crosstab(data['A'],data['B'],normalize=True))
–> 输出的结果为:
B 3 4
A
1 0.2 0.0
2 0.2 0.6
values:可选,根据因子聚合的值数组
aggfunc:可选,如果未传递values数组,则计算频率表,如果传递数组,则按照指定计算
print(pd.crosstab(data['A'],data['B'],values=data['C'],aggfunc='sum'))
–> 输出的结果为:(这里相当于以A和B界定分组,计算出每组中第三个系列C的值)
B 3 4
A
1 1.0 NaN
2 1.0 2.0
margins:布尔值,默认值False,添加行/列边距(小计汇总)
print(pd.crosstab(data['A'],data['B'],values=data['C'],aggfunc='sum', margins=True))
–> 输出的结果为:
B 3 4 All
A
1 1.0 NaN 1.0
2 1.0 2.0 3.0
All 2.0 2.0 4.0