机器学习算法笔记(一)
(1)容斥原理
a. 容斥原理是组合数学方法,可以求解集合、复合事件的概率等。
b. 计算几个集合并集的大小,先计算出所有单个集合的大小,减去所有两个集合相交的部分,加上三个集合相交的部分,再减去四个集合相交的部分,以此类推,一直计算到所有集合相交的部分。
c. 概率论:
事件Ai(i=1,...,n),P(Ai)为对应事件发生的概率。至少一个事件发生的概率: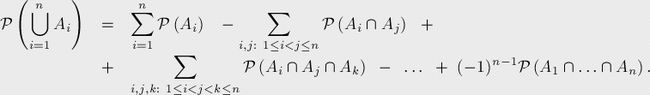
转自:https://blog.csdn.net/m0_37286282/article/details/78869512
(2)基于物品的协同过滤算法
基于物品的协同过滤算法主要分为两步:
a. 计算物品之间的相似度
 其中Ni是喜欢物品i的用户数 Nj是喜欢物品j的用户数,分子式同时喜欢物品i和物品j的用户数。
其中Ni是喜欢物品i的用户数 Nj是喜欢物品j的用户数,分子式同时喜欢物品i和物品j的用户数。
此时可以建立物品相似度矩阵C,在得到物品之间的相似度后,进入第二步。
b. 根据物品的相似度和用户的历史行为给用户生成推荐列表
ItemCF通过如下公式计算用户u对一个物品j的兴趣
 其中,Puj表示用户u对物品j的兴趣,N(u)表示用户喜欢的物品集合(i是用户喜欢的某一个物品),S(I, K)表示和物品i最相似的K个物品集合(j是这个集合中的一个物品),Wji表示物品j和物品i的相似度,Rui表示用户u对物品i的兴趣(这里简化Rui都等于1)
其中,Puj表示用户u对物品j的兴趣,N(u)表示用户喜欢的物品集合(i是用户喜欢的某一个物品),S(I, K)表示和物品i最相似的K个物品集合(j是这个集合中的一个物品),Wji表示物品j和物品i的相似度,Rui表示用户u对物品i的兴趣(这里简化Rui都等于1)
参考:https://blog.csdn.net/u011630575/article/details/78649331
(3)梯度下降法的另一个理解
a. 在机器学习任务中,需要最小化损失函数L(θ),其中θ是要求解的模型参数。梯度下降法常用来求解这种无约束最优化问题,是一种迭代方法:选取初值θ',不断迭代,更新θ的值,进行损失函数的极小化 。
b. 迭代公式:![]()
c. 将![]() 在
在![]() 处进行一阶泰勒展开:
处进行一阶泰勒展开:
要使得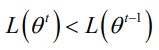 ,可取
,可取 ,则:
,则: ,α为步长。
,α为步长。
(4)XGBOOST针对传统GBDT改进的地方
a. 误差函数引入二阶泰勒展开
b. 正则化项加入数的个数和节点权值的计算
c. 使用优化后的结构分数作为新的目标函数,求解最优化的节点的参数
d. 利用贪心法计算分裂前后的增益(即新的目标函数),选取增益大的进行分割。

e. 近似算法进行树的节点分裂,对于每个特征,只考察分位点,减少计算量。(实际上是二阶导数值作为权重?)
f. 缺失值自动学习出分裂的方向
g. 借鉴随机森林列抽样,支持行抽样、缩减、支持自定义损失函数h. 特征预排序,以column block的结构存在内存中 加速了splid finding的过程,只需要在建树前排序一次,后面的节点分裂时直接根据索引得到梯度信息
i. 支持并行。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行
j. 可并行的近似直方图算法:把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累计统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点
(5)LightGBM传统XGBOOST改进的地方
1. 直方图差加速。一个叶子的直方图可以由它的父亲节点直方图做差得到,提升一倍速度
2. 建树过程的两种方法。XGBoost同一层所有节点分裂,最后剪枝。lgb选取具有最大增益的节点分裂,容易过拟合,通过max_depth限制
3. 特征并行优化。传统的特征并行,每个worker只有部分特征 全局切分需要网络通信;lgb每个worker保存所有数据集
4. 数据并行优化
5. 迭代加速。在每一次迭代前,利用了GBDT中样本误差和梯度的关系,对训练样本进行采样,误差大的保留,小的采样一个子集,但给一个权重,保证数据分布不变。
6. 特征加速。在特征维度很大的数据上,特征空间一般都很稀疏。降低构造特征直方图需要便利的特征数量。
(6)深度学习防止过拟合的方法
1. 参数正则化:
2. 数据增强:增加训练样本数量是防止过拟合最直接有效的一种方法
3. 提前终止:
4. dropout:在深度神经网络训练过程中,按照一定的概率随机丢弃(dropout)一些神经元的激活,提高模型的泛化能力,使模型更为鲁棒
(7)机器学习中的防过拟合
1. 增大数据量:最有效的方法
2. 选择较为简单的模型
3. 继承方法:bagging等
4. 正则化项的添加
5. early stopping