Yarn-NodeManager堆内存不足导致Container被杀
一、问题再现
由于项目需要,采购电信天翼云,由于是新搭建的集群,在yarn上跑Spark任务时,每个几个小时或者半天出现节点丢失(Lost Nodes),访问http://cloudera01:8088,如下图,可以看到2个节点和集群失去了联系
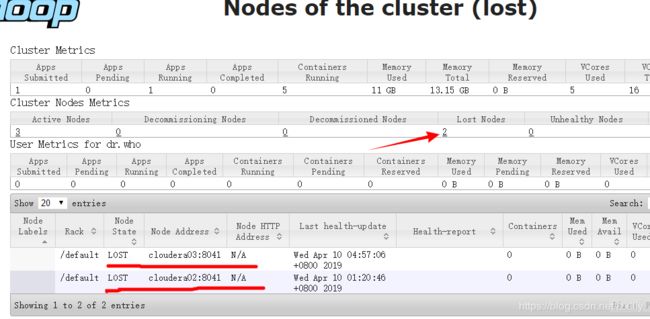
二、问题排查
1、登录cm管理界面
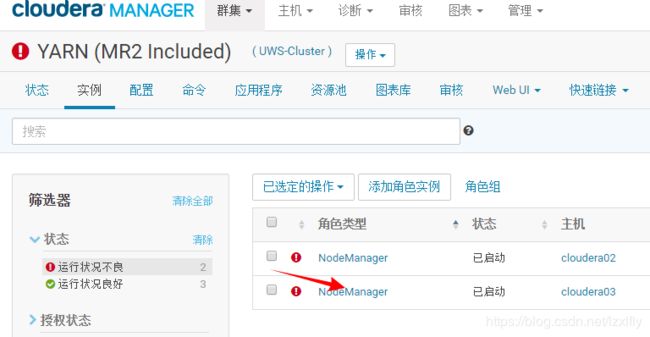
首先登录cm管理界面,去查看yarn的运行状况,看到2个NodeManager运行不良,点击不良链接

2、点击NodeManager查看
3、NodeManager与ResourceManager失联
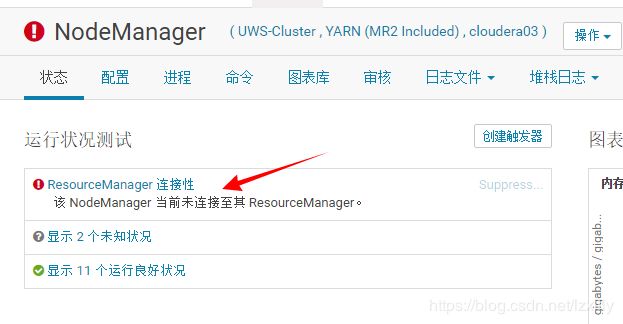
这就去查看NodeManager的日志进一步查找问题,去查看cloudera03这台机日志
4、查看NodeManager日志
其日志默认路径在/var/log/hadoop-yarn下,less hadoop-cmf-yarn-NODEMANAGER-cloudera03.log.out
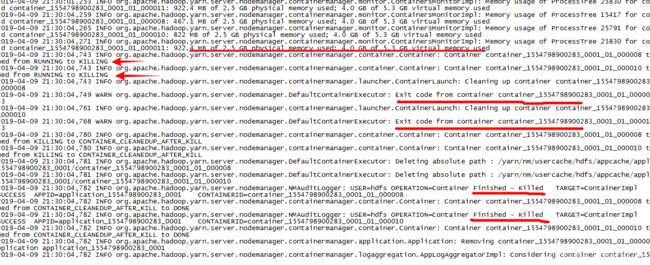
先看到container_1554798900283_0001_01_000008 与内存使用情况的日志
Memory usage of ProcessTree 11630 for container-id container_1554798900283_0001_01_000025: 695.6 MB of 2.5 GB physical memory used; 4.0 GB of 5.3 GB virtual memory used
之后该container_1554798900283_0001_01_000008 状态从RUNNING到KILLING
Container container_1554798900283_0001_01_000008 transitioned from RUNNING to KILLING
接着这个container_1554798900283_0001_01_000008 退出
Exit code from container container_1554798900283_0001_01_000008 is : 143
最终完成杀死,清理container相关信息,这大概就是一个container被杀死的过程
Container container_1554798900283_0001_01_000008 transitioned from KILLING to CONTAINER_CLEANEDUP_AFTER_KILL
根据以上情况,可以初步断定是由于NodeManager分配给container虚拟内存分配不足引起的自杀,从而缓解内存不足状况,保证其它container运行。
三、尝试解决方案
1、问题分析
相关属性说明
| yarn.scheduler.minimum-allocation-mb | 1024 | 分配给AM单个容器可申请的最小内存,默认1024M | RM属性 |
| yarn.scheduler.maximum-allocation-mb | 8192 | 分配给AM单个容器可申请的最大内存,默认8192M, 不能超过NM节点最大可用内存 |
RM属性 |
| yarn.nodemanager.resource.memory-mb | 8192 | NM节点最大可用内存,默认8192M | NM属性 |
| yarn.nodemanager.vmem-check-enabled | true | 是否检查虚拟内存,默认true检查 | NM属性 |
| yarn.nodemanager.vmem-pmem-ratio | 2.1 | 虚拟内存率,默认值是2.1 | NM属性 |
分析:Memory usage of ProcessTree 11630 for container-id container_1554798900283_0001_01_000025: 695.6 MB of 2.5 GB physical memory used; 4.0 GB of 5.3 GB virtual memory use
默认物理内存是1GB,动态申请到了2.5GB,其中使用了695.6 MB。物理内存╳2.1=虚拟内存,2.5GB╳2.1≈5.3GB ,5.3GB虚拟内存中使用了4.0GB,当虚拟内存不够时候,NM的container就会自杀,这里虽然没耗尽,但也自杀了。所以有两个解决方案,或调整yarn.nodemanager.vmem-pmem-ratio值大点,或yarn.nodemanager.vmem-check-enabled=false,关闭虚拟内存检查
2、在cloudera-manager控制台界面调整
登录cloudera-manager管理系统http://192.xxx.xxx.71:7180,进入YARN (MR2 Included)配置界面,完成后保存
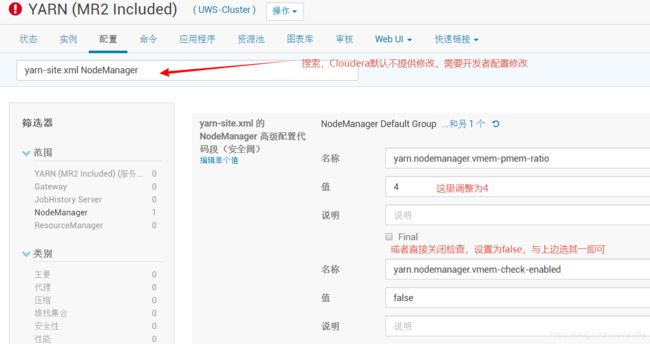
因为调整需要重启服务,这里为了防止以后不够用,顺便把RM的yarn.scheduler.maximum-allocation-mb和NM的yarn.scheduler.maximum-allocation-mb调大点,避免频繁修改参数重启服务影响生产。
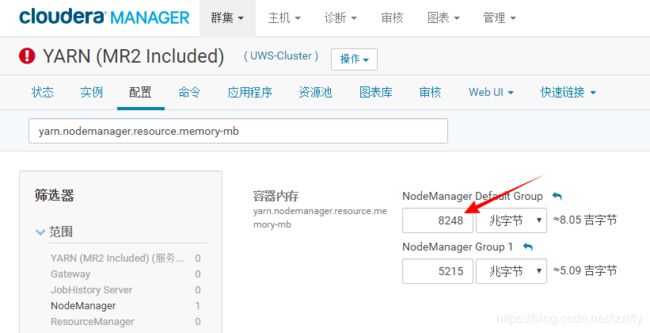
NM的yarn.scheduler.maximum-allocation-mb,默认约8.05G,我改为以G为单位,设为12G,保存修改
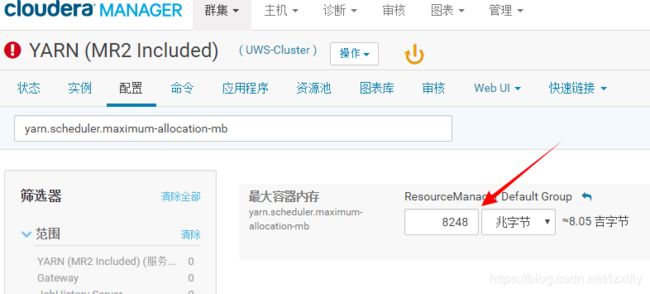
yarn.scheduler.maximum-allocation-mb调大点,也改为以G为单位,这里设置为12G,保存修改。
完成之后重新启动YARN (MR2 Included)服务,再提交我们的spark任务,观察2天,仍然有此问题出现,看来以上方案不能解决问题。
四、最终有效解决方案
这次可以看到GC持续时间未知提示,看到这句话可以猜到可能是GC一直卡在那儿了
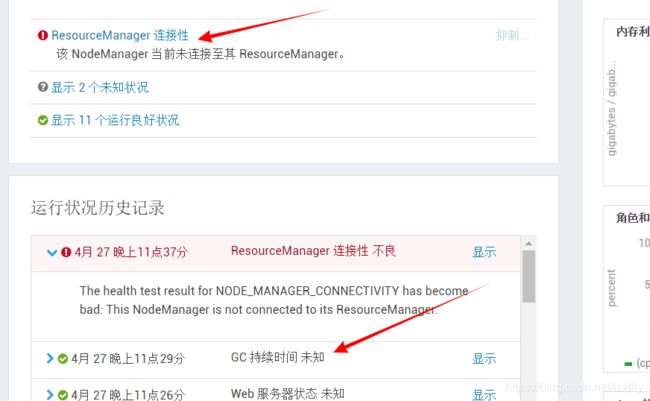
查看Nodemanager日志,仍然报同样的问题,看来并不是虚拟内存不足导致container被杀的问题
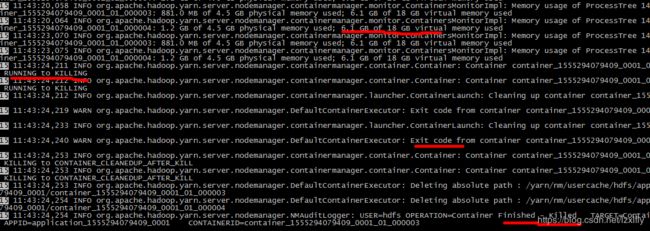
接着往下看,看到Full compaction cycle completed in 11 msec ,触发了Full gc,下边还有这样的日志,Full GC时间太长了,持续11秒,而且也频繁了,这肯定不正常。
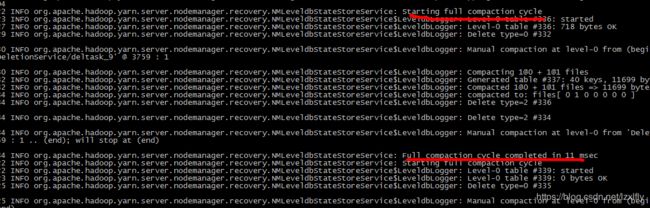
于是去查看NodeManager启动参数 $ jps -v

看到-Xmx1000m,后边还有-Xms52428800 -Xmx5242880。可以看到最大堆内存设置了两个,后边50m覆盖了前边的1000m,最终-Xms、 -Xmx都是50m,$ jmap -heap pid 查看NodeManager最大堆内存也是50m(当时忘记截图了),太小了肯定不行,必然导致频繁的full gc,停顿时间长。
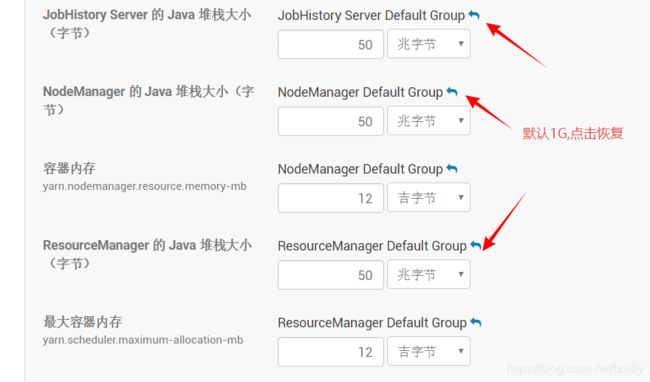
于是乎去平台修改Nodemanager的JVM参数,到ClouderaManager yarn服务, 找到非默认参数,看到NM、RM都被改成了50m,点击恢复过来。
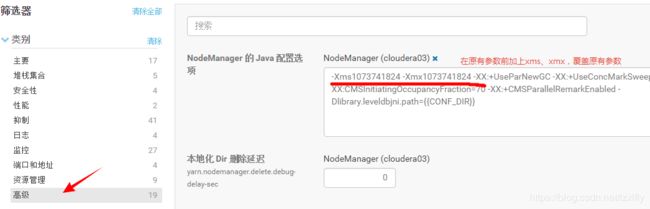
或者直接在高级选项中,新增-Xms1073741824 -Xmx1073741824, 就会覆盖CDH自动设置的50m
保存重启yarn服务,又观察几天,没有出现NodeManager堆内存不足而导致container被杀的情况
回想一下,关于这个Nodemanager的JVM参数-Xms -Xmx,为什么会设置50m呢
抱着追根问底的好奇心,去查看了其他环境下的参数设置。测试环境(内存16G)有的节点分配的是1024m,有的是730m,还有的是668m。而另一个集群生产环境(内存64G),看来几个节点,都是1024m,且几个地方用的cdh 5.12.2版本都一样,而此处(内存32G)被设置了50m。初步判断cdh是根据可用内存自动分配的,可能是启动NodeManager时某些机器内存不足导致堆内存分配了50m,一方面堆内存不足container自杀,另一方面不断full gc来回收空间,停顿时间长,到最终失联。