BosonNLP API 中文语义分析(笔记)【boson已经停止提供服务了,可使用 百度AI 的 NLP 功能】
文章目录
- BosonNLP API 中文语义分析
- 查询 API 频率限制
- 情感分析
- 分词与词性标注
- 关键词提取
- 语义联想
- 新闻分类
- 新闻摘要
- 时间转换
- 其他单文本分析
- 多文本分析功能
BosonNLP API 中文语义分析
参见 python版 BosonNLP HTTP API 封装库(SDK):http://bosonnlp-py.readthedocs.io/#bosonnlp
- BosonNLP 官网:http://bosonnlp.com/
- BosonNLP HTTP API 文档: http://docs.bosonnlp.com/index.html
from __future__ import print_function, unicode_literals
from bosonnlp import BosonNLP
import requests, json
token = 'your Token' # 个人token!!!
nlp = BosonNLP(token) # nlp = BosonNLP('YOUR_API_TOKEN')
查询 API 频率限制
免费用户的 API 每天有次数限制的,具体如下图:
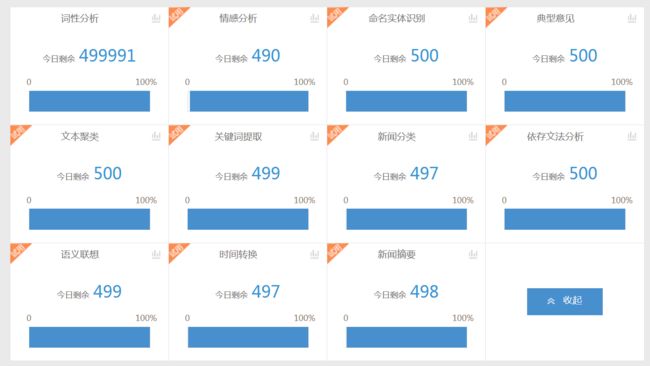
当然,通过购买,可以增加次数,费用情况如下:
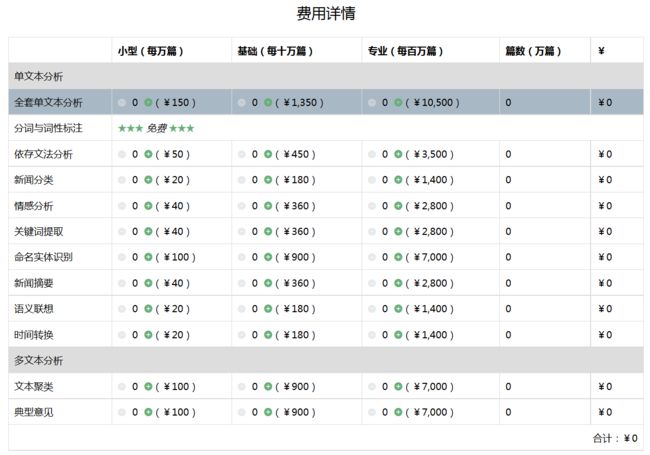
我觉得,面对这么完善的中文文本分析功能,免费用户却拥有全部的功能,即便每天有次数限制,已然值得称赞~~~
# 本接口用来查询用户使用 BosonNLP API 频率限制的详细信息。
HEADERS = {'X-Token': token} # 注意:在测试时请更换为您的 API token
RATE_LIMIT_URL = 'http://api.bosonnlp.com/application/rate_limit_status.json'
result = requests.get(RATE_LIMIT_URL, headers=HEADERS).json()
result['limits'].keys()
# (['review', 'keywords', 'tag', 'classify', 'depparser', 'time', 'summary', 'ner', 'cluster', 'comments', 'suggest', 'sentiment'])
dict_keys([‘review’, ‘keywords’, ‘tag’, ‘classify’, ‘depparser’, ‘time’, ‘summary’, ‘ner’, ‘cluster’, ‘comments’, ‘suggest’, ‘sentiment’])
例:查询情感分析剩余次数
result['limits']['sentiment'].keys()
# (['rate-limit-limit', 'rate-limit-remaining', 'rate-limit-reset', 'quota-limit', 'count-limit-reset', 'count-limit-limit', 'quota-remaining', 'count-limit-remaining'])
result['limits']['sentiment']['count-limit-remaining'] # 查询情感分析次数
写成函数的形式:
def sentiment_limit_remaining():
result = requests.get(RATE_LIMIT_URL, headers=HEADERS).json()
return result['limits']['sentiment']['count-limit-remaining']
情感分析
核心函数:nlp.sentiment(data, model = 'general')
参见:http://docs.bosonnlp.com/sentiment.html
model 参数用来传递模型名选择用特定行业语料进行训练的模型;可选值,默认为 general 。
| 模型名 | 行业 | URL |
|---|---|---|
| general | 通用 | http://api.bosonnlp.com/sentiment/analysis |
| auto | 汽车 | http://api.bosonnlp.com/sentiment/analysis?auto |
| kitchen | 厨具 | http://api.bosonnlp.com/sentiment/analysis?kitchen |
| food | 餐饮 | http://api.bosonnlp.com/sentiment/analysis?food |
| news | 新闻 | http://api.bosonnlp.com/sentiment/analysis?news |
| 微博 | http://api.bosonnlp.com/sentiment/analysis?weibo |
返回结果说明:
第一个值为非负面概率,第二个值为负面概率,两个值相加和为 1。
nlp.sentiment(['这家味道还不错', '菜品太少了而且还不新鲜'], model='weibo')
[[0.9694666780709835, 0.03053332192901642],
[0.07346999807197441, 0.9265300019280256]]
nlp.sentiment(['这家味道还不错', '菜品太少了而且还不新鲜'], model='food')
[[0.9991737012037423, 0.0008262987962577828],
[9.940036427291687e-08, 0.9999999005996357]]
或者使用 HTTP Header 返回
SENTIMENT_URL = 'http://api.bosonnlp.com/sentiment/analysis?weibo' # 微博分析api
headers = {'X-Token': token} # 注意:在测试时请更换为您的 API token 。
s = [' 他是个傻逼 ', ' 美好的世界 ']
data = json.dumps(s) # 包装成 json
HTTP 返回 Body JSON 格式的 [double, double] 类型组成的列表。
resp = requests.post(SENTIMENT_URL, headers=headers, data=data.encode('utf-8')) # 上传 data 进行分析
resp.text # 显示情感分数
‘[[0.4434637245024887, 0.5565362754975113], [0.9340287284701145, 0.06597127152988551]]’
分词与词性标注
核心函数:nlp.tag(contents, space_mode=0, oov_level=3, t2s=0, special_char_conv=0)
函数参数参见:http://docs.bosonnlp.com/tag.html
词性标注说明参见:http://docs.bosonnlp.com/tag_rule.html
BosonNLP 的词性标注非常详细,共有 22个大类,70个标签!!
而且 BosonNLP 分词和词性标注系统还提供了多种分词选项,以满足不同开发者的需求:
- 空格保留选项 (space_mode)
- 新词枚举强度选项 (oov_level)
- 繁简转换选项 (t2s)
- 特殊字符转换选项 (special_char_conv)
result = nlp.tag(['成都商报记者 姚永忠', '调用参数及返回值详细说明见'])
print(result)
[{‘tag’: [‘ns’, ‘n’, ‘n’, ‘nr’], ‘word’: [‘成都’, ‘商报’, ‘记者’, ‘姚永忠’]}, {‘tag’: [‘v’, ‘n’, ‘c’, ‘v’, ‘n’, ‘ad’, ‘v’, ‘v’], ‘word’: [‘调用’, ‘参数’, ‘及’, ‘返回’, ‘值’, ‘详细’, ‘说明’, ‘见’]}]
关键词提取
核心函数:nlp.extract_keywords(text, top_k=None, segmented=False)
参见:http://docs.bosonnlp.com/keywords.html
keywords = nlp.extract_keywords('病毒式媒体网站:让新闻迅速蔓延', top_k=2)
print(keywords) # 返回权重和关键词,所有关键词的权重的平方和为 1
[[0.5686631749811326, ‘蔓延’], [0.5671956747680966, ‘病毒’]]
语义联想
核心函数:nlp.suggest(data)
参见:http://docs.bosonnlp.com/suggest.html
term = '粉丝'
result = nlp.suggest(term, top_k=10)
for score, word in result:
print(score, word)
0.9999999999999996 粉丝/n
0.48602467961311013 脑残粉/n
0.47638025976400944 听众/n
0.4574711603743689 球迷/n
0.4427939662212161 观众/n
0.43996388413040877 喷子/n
0.43706751168681585 乐迷/n
0.43651710096540336 鳗鱼/n
0.4357353461210975 水军/n
0.4332090811336725 好友/n
新闻分类
核心函数:nlp.classify(data)
参见:http://docs.bosonnlp.com/classify.html
| 编号 | 分类 | 编号 | 分类 |
|---|---|---|---|
| 0 | 体育 | 7 | 科技 |
| 1 | 教育 | 8 | 互联网 |
| 2 | 财经 | 9 | 房产 |
| 3 | 社会 | 10 | 国际 |
| 4 | 娱乐 | 11 | 女人 |
| 5 | 军事 | 12 | 汽车 |
| 6 | 国内 | 13 | 游戏 |
s = ['俄否决安理会谴责叙军战机空袭阿勒颇平民',
'邓紫棋谈男友林宥嘉:我觉得我比他唱得好',
'Facebook收购印度初创公司']
result = nlp.classify(s)
result
[5, 4, 8]
新闻摘要
核心函数:summary(title, content, word_limit=0.3, not_exceed=False)
参见:http://docs.bosonnlp.com/summary.html
content = (
'腾讯科技讯(刘亚澜)10月22日消息,前优酷土豆技术副总裁'
'黄冬已于日前正式加盟芒果TV,出任CTO一职。'
'资料显示,黄冬历任土豆网技术副总裁、优酷土豆集团产品'
'技术副总裁等职务,曾主持设计、运营过优酷土豆多个'
'大型高容量产品和系统。'
'此番加入芒果TV或与芒果TV计划自主研发智能硬件OS有关。')
title = '前优酷土豆技术副总裁黄冬加盟芒果TV任CTO'
nlp.summary(title, content, 0.1)
‘腾讯科技讯(刘亚澜)10月22日消息,前优酷土豆技术副总裁黄冬已于日前正式加盟芒果TV,出任CTO一职。’
时间转换
核心函数:nlp.convert_time(data, basetime=None)
参见:http://docs.bosonnlp.com/time.html
感觉这是一个独(ling)特(lei)的文本分析功能,用在时间文本上面,应该是个不错的选择。
import datetime # 使用 basetime 时导入该模块
nlp.convert_time(
"2013年二月二十八日下午四点三十分二十九秒",
datetime.datetime.today()) # datetime.datetime(2017, 10, 19, 22, 21, 18, 434128)
{‘timestamp’: ‘2013-02-28 16:30:29’, ‘type’: ‘timestamp’}
nlp.convert_time("今天晚上8点到明天下午3点", datetime.datetime(2015, 9, 1))
{‘timespan’: [‘2015-09-01 20:00:00’, ‘2015-09-02 15:00:00’],
‘type’: ‘timespan_0’}
nlp.convert_time("今天晚上8点到明天下午3点", datetime.datetime.today()) #
{‘timespan’: [‘2017-10-21 20:00:00’, ‘2017-10-22 15:00:00’],
‘type’: ‘timespan_0’}
其他单文本分析
依存文法分析:http://docs.bosonnlp.com/depparser.html
命名实体识别:http://docs.bosonnlp.com/ner.html
多文本分析功能
文本聚类:http://docs.bosonnlp.com/cluster.html
典型意见:http://docs.bosonnlp.com/comments.html