Linux 磁盘与文件系统
认识 Linux 文件系统
磁盘组成与分区基本知识
- 扇区(Sector)为最小的物理储存单位,且依据磁盘的设计,目前有 512bytes 和 4k 两种格式
- 将扇区组成一个圆,就是磁柱(道)(Sectors/Track),鸟哥所说的 磁盘盘 是扇面
- 早期分区主要以磁柱为最小分区单位,现在分区通常使用扇区为最小单位
- 磁盘分区表主要有两种格式,一种是 MBR 分区表,一种是 GPT 分区表
- MBR 分区表中,第一个扇区最重要,里面有 主要开机区(Master boot record,MBR) 和 分区表(partition table),其中 MBR 占有 446bytes,partition table占有 64bytes
- GPT 分区表分区数量扩充较多,支持的磁盘容量超过 2 TB
可以使用 fdisk -l 命令查看自己磁盘分区表格式,如果 Disklabel type: dos 则是MBR磁盘分区表,如果是Disklabel type: gpt 则是GPT分区表
磁盘在文件系统中的命名方式:
- /dev/sd[a-p][1-128]:为实体磁盘的磁盘文件名
- /dev/vd[a-p][1-128]:为虚拟磁盘的磁盘文件名
文件系统的特性
磁盘分区后,还需要格式化(format)后,操作系统才能使用,因为每种操作系统所设定的文件属性/权限并不相同,格式化后,分区槽(partiton)就成为了操作系统能够使用的 文件系统格式(filesystem)。
传统的磁盘与文件系统中,一个分区槽是只能够被格式化一个文件系统,所以说一个 filesystem 就是一个 partition,现在可以将一个分区槽格式化成多个文件系统(LVM),也可以将多个分区槽合成一个文件系统(LVM,RAID),通常我们称一个可被挂载的数据为一个文件系统而不是一个分区槽。
文件系统通常将文件数据和文件属性(权限(rwx)、文件属性(拥有者,群组,时间参数)等)这两部分数据放置到不同的区块,权限与属性放置到 inode 中,实际数据放置到 data block 区块中。有一块超级区块(superblock)会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
inode、block、superblock的意义:
| 名称 | 意义 |
|---|---|
| superblock | 记录次filesystem 的整体信息,包括 inode/block总量、使用量、剩余量、以及文件系统的格式与相关信息 |
| inode | 记录文件的属性,一个文件占用一个 inode,同时记录此文件的数据所在的 block 号码 |
| block | 实际记录文件内容,若文件太大,会占用用多个 block |
Linux 的 EXT2 的文件系统(inode)
Linux 的 EXT2 文件系统使用的是以 inode 为基础的文件系统,文件系统一开始就将inode 和 block 规划好了,除非重新格式化或者利用resize2fs 等指令改变文件系统大小,否则 inode 和block 固定后不变。
为了方便管理inode 和 block,Extr2 文件系统在格式化的时候基本上是区分为多个区块群组(block group),每个区块群组都有独立的 inode/block/superblock 系统。如图:
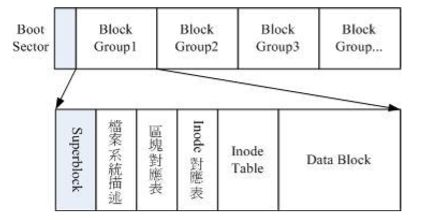
Ext2文件系统示意图
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序。
data block(资料区块)
data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种。在格式化时 block 的大小就固定了,且每个 block 都有编号,以方便 inode 的记录。由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大 单一文件容量并不相同。 因为 block 大小而产生的 Ext2 文件系统限制如下:
| Block大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件限制 | 16GB | 256GB | 2TB |
| 最大文件系统总容量 | 2TB | 8TB | 16TB |
block 的其他限制:
- block 的大小与数量在格式化完就不能够再改变了(除非重新格式化)
- 每个 block 内最多只能够放置一个文件的数据,如果文件大于 block 的大小,则一个文件会占用多个 block 数量,若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)
inode table(inode 表格)
inode 的内容在记录文件的属性以及该文件实际数据 是放置在哪几号 block 内,包括:
- 该文件的存取模式(read/write/excute)
- 该文件的拥有者与群组(owner/group)
- 文件的容量
- 文件建立或状态改变的时间(ctime)
- 最近一次的读取时间(atime)
- 最近修改的时间(mtime)
- 定义文件特性的旗标(flag),如 SetUID
- 文件真正内容的指向 (pointer)
inode 的数量和大小也是在格式化时就已经固定,其他特点:
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes)
- 每个文件都仅会占用一个 inode,因此文件系统能够建立的文件数量与 inode 的数量有关
- 系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与用户是否符合,若符合才能够开始实际 读取 block 的内容
inode 示意图如下:
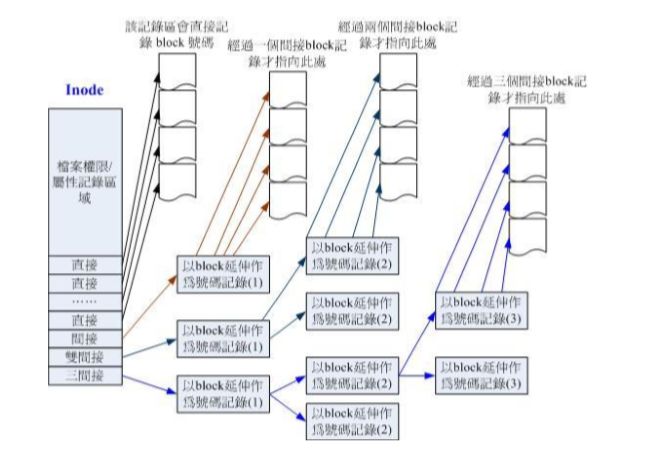
inode 示意图
记录一个block块需要4byte。可以使用直接、间接、双间接、三间接记录。间接记录使用的是block记录的。
Superblock(超级区块)
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock ,就没有这个 filesystem,他记录的信息有(可以通过dumpe2fs 命令查看):
- block 与 inode 的总量
- 未使用与已使用的 inode / block 数量
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128bytes 或 256bytes)
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信 息
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1
Superblock的大小一般为 1024bytes,每个 block group 都可能含有 superblock,一个文件系统应该仅有一个 superblock,事实上除了第一个 block group 内会含有 superblock 之外,后 续的 block group 不一定含有 superblock , 而若含有 superblock 则该 superblock 主要是做为第一 个 block group 内 superblock 的备份
Filesystem Description (文件系统描述说明)
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段 (superblock, bitmap, inodemap, data block) 分别介于哪一个 block 号码之间,可以通过dumpe2fs 命令查看。
block bitmap(区块对照表)
block bitmap 中记录 block 是否使用,新建文件时可以快速找到未使用的block,删除文件时,释放block,标记block未使用。
inode bitmap(inode对照表)
与block bitmap 作用类似。
dumpe2fs:查询 Ext家族superblock 信息的指令
使用命令sudo blkid 列出当前系统中所有已挂载文件系统的类型,然后进行 sudo dumpe2fs 装置名 | more,建议使用 more 因为输出的信息太多了,不易查看。这样就可以观察superblock 内的信息了。
与目录树的关系
每一个文件(不管是一般文件还是目录文件)都会占用一个inode,目录的内容记录文件名,一般文件记录实际数据内容。目录与文件在文件系统中如何记录数据呢?
- 目录:
Linux 下的文件系统建立一个目录时,文件系统会分配一个 inode 与至少一块 block 给该 目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码; 而 block 则 是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。
使用ls -li命令查看文件的inode 号码 - 文件:
在 Linux 下的 ext2 建立一个一般文件时, ext2 会分配一个 inode 与相对于该文件大小的 block 数量给该文件。 - 目录树读取:
inode 本身并不记录文件名,文件名的记录是在目 录的 block 当中,所以 新增/删除/更名文件名 与目录的 w 权限有关。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的 inode 号码,此时就 能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层 的往下读到正确的档名
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
新建一个文件时,文件系统的行为是:
- 先确定用户对于欲增文件的目录是否具有 w 和 x 权限,若有才能新增
- 根据 inode bitmap 找到没有使用的idode 号码,并将新文件的权限、属性写入
- 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据
- 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容
inode table 与 data block 称为数据存放区域,superblock、 block bitmap 与 inode bitmap 等区段就被称为 metadata (中介资料) ,因为 superblock, inode bitmap 及 block bitmap 的数据是经常变动的,每次新增、移除、编辑时都可能会影响到这三个部分的数据,因此才被称为中介数据。
数据的不一致 (Inconsistent) 状态
文件在写入文件系统时,因为不知名原因导致系统中断(例如突然的停电、 系统核心发生错误发生时),所以写入的数据仅有 inode table 及 data block,最后一个同步更新中介 数据的步骤并没有做完,此时就会发生 metadata 的内容与实际数据存放区产生不一致 (Inconsistent) 的情况。
在早期的 Ext2 文件系统中,如果发生这个问题, 那么系统在重新启动的时候,就会由 Superblock 当中记录的 valid bit (是否有挂载) 与 filesystem state (clean 与否) 等状态来判断是否强制进行数据一致性的检查,检查整个磁盘,耗时长,于是出现了日志式文件系统。
日志式文件系统 (Journaling filesystem)
在filesystem 当中规划出一个区块,该区块专门在记录写入或修订文件时的步骤:
- 预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息
- 实际写入:开始写入文件的权限与数据;开始更新 metadata 的数据
- 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的纪录
如果数据的记录过程中出现问题,那么只要检查日至记录区块即可。使用 dumpe2fs,可以在 superblock中发现(ubuntu16):
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 24cbf2f0-10b9-4f68-9cdd-33073e41c59a
Journal backup: inode blocks
Journal features: journal_incompat_revoke
Journal size: 128M
Journal length: 32768
Journal sequence: 0x000442ca
Journal start: 36可以知道在 inode 8 号记录 journal 区块的 block 指向,而且具有 128MB 的容量在处理日志。
Linux 文件系统的运作
由于磁盘写入的速度要比内存慢很多,在编辑保存文件时效率较低,为了解决这个问题Linux使用异步处理 (asynchronously) :当系统加载一个文件到内存后,如果该文件没有被更动过,则在内存区段的文件数据会被设定为干净 (clean)的。 但如果内存中的文件数据被更改过了(例如你用 nano 去编辑过这个文件),此时该内存中 的数据会被设定为脏的 (Dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中! 系统会不定时的将内存中设定为『Dirty』的数据写回磁盘,以保持磁盘与内存数据的一致性。 也可以使用sync 指令来手动写入磁盘。
- 系统会将常用的文件数据放置到主存储器的缓冲区,以加速文件系统的读/写,因此 Linux 的物理内存最后都会被用光!这是正常的情况!可加速系统效能
- 可以手动使用 sync 来强迫内存中设定为 Dirty 的文件回写到磁盘中
- 若正常关机时,关机指令会主动呼叫 sync 来将内存的数据回写入磁盘,若不正常关机(如跳电、当机或其他不明原因),由于数据尚未回写到磁盘内, 因此重新启动后可能会花 很多时间在进行磁盘检验,甚至可能导致文件系统的损毁(非磁盘损毁)
挂载点的意义 (mount point)
每个 filesystem 都有独立的 inode / block / superblock 等信息,这个文件系统要能够链接到目录树才 能被我们使用。 将文件系统与目录树结合的动作我们称为 挂载。挂载点一定是目录,该目录为进入该文件系统的入口。
XFS 文件系统简介
由于 EXT 文件系统格式化慢(预先分配 inode 与 block 耗时),所以从CentOS 7 开始预设的文件系统为 XFS 文件系统了。
XFS 文件系统的配置
xfs 文件系统在资料的分布上,主要规划为三个部份,一个数据区 (data section)、一个文件系统活动登录区 (log section)以及一个实时运作区 (realtime section)。 这三个区域的数据内容如下:
- 数据区 (data section)
数据区跟 ext 家族一样,包括 inode/data block/superblock 等数据,都放置在这个区块。 这个数据区与 ext 家族的 block group 类似,也是分为多个储存区群组 (allocation groups) 来分别放置文件系统所需要的数据。 每个储存区群组都包含了 (1)整个文件系 统的 superblock、 (2)剩余空间的管理机制、 (3)inode 的分配与追踪。此外,inode 与 block 都是 系统需要用到时, 这才动态配置产生,所以格式化动作超级快!
另外,与 ext 家族不同的是, xfs 的 block 与 inode 有多种不同的容量可供设定,block 容量可由 512bytes ~ 64K 调配,不过,Linux 的环境下, 由于内存控制的关系 (页面文件 pagesize 的 容量之故),因此最高可以使用的 block 大小为 4K 而已!至于 inode 容量可 由 256bytes 到 2M 这么大!不过,保留 256bytes 的默认值就够用了 - 文件系统活动登录区(log section)
这个区域主要被用来纪录文件系统的变化,有点像是日志区,文件的变化会在这 里纪录下来,直到该变化完整的写入到数据区后, 该笔纪录才会被终结。如果文件系统因为某些缘故 (例如最常见的停电) 而损毁时,系统会拿这个登录区块来进行检验,看看系统挂掉之前, 文 件系统正在运作些啥动作,以快速的修复文件系统。
因为系统所有动作的时候都会在这个区块做个纪录,因此这个区块的磁盘活动是相当频繁的!在这个区域中, 可以指定外部的磁盘来作为 xfs 文件系统的日志区块,例如,可以将 SSD 磁盘作为 xfs 的登录区,这样当系统需要进行任何活动时, 就可以更快速的进行工作 - 实时运作区 (realtime section)
当有文件要被建立时,xfs 会在这个区段里面找一个到数个的 extent 区块,将文件放置在这个区 块内,等到分配完毕后,再写入到 data section 的 inode 与 block 去, 这个 extent 区块的大小 得要在格式化的时候就先指定,最小值是 4K 最大可到 1G。一般非磁盘阵列的磁盘默认为 64K 容量,而具有类似磁盘阵列的 stripe 情况下,则建议 extent 设定为与 stripe 一样大较佳。这个 extent 最好不要乱动,因为可能会影响到实体磁盘的效能。
XFS 文件系统的描述数据观察
类似在 XFS 中 dumpe2fs devicename,在XFS中有 xfs_info devicename
范例:
[root@study ~]# xfs_info /dev/vda2
1 meta-data=/dev/vda2 isize=256 agcount=4, agsize=65536 blks
2 = sectsz=512 attr=2, projid32bit=1
3 = crc=0 finobt=0
4 data = bsize=4096 blocks=262144, imaxpct=25
5 = sunit=0 swidth=0 blks
6 naming =version 2 bsize=4096 ascii-ci=0 ftype=0
7 log =internal bsize=4096 blocks=2560, version=2
8 = sectsz=512 sunit=0 blks, lazy-count=1
9 realtime =none extsz=4096 blocks=0, rtextents=0 相关解释:
- 第 1 行里面的 isize 指的是 inode 的容量,每个有 256bytes 这么大。至于 agcount 则是前面谈到的储存 区群组 (allocation group) 的个数,共有 4 个, agsize 则是指每个储存区群组具有 65536 个 block 。配 合第 4 行的 block 设定为 4K,因此整个文件系统的容量应该就是 4*65536*4K 这么大!
- 第 2 行里面 sectsz 指的是逻辑扇区 (sector) 的容量设定为 512bytes 这么大的意思。
- 第 4 行里面的 bsize 指的是 block 的容量,每个 block 为 4K 的意思,共有 262144 个 block 在这个文 件系统内。
- 第 5 行里面的 sunit 与 swidth 与磁盘阵列的 stripe 相关性较高。
- 第 7 行里面的 internal 指的是这个登录区(log section)的位置在文件系统内,而不是外部设备的意思。且占用了 4K * 2560 个 block,总共约 10M 的容量
- 第 9 行里面的 realtime 区域,里面的 extent 容量为 4K。不过目前没有使用。
文件系统的简单操作
磁盘与目录的容量
磁盘的整体数据记录在 superblock 区块中,但是每个文件的容量则在 inode 当中记载的,可以使用df 和 du 命令查询。
+ df :列出文件系统的整体磁盘使用量
+ du :评估文件系统的磁盘使用量(常用在推估目录所占容量)
df 命令格式:
[root@study ~]# df [-ahikHTm] [目录或文件名]
选项与参数:
-a :列出所有的文件系统,包括系统特有的 /proc 等文件系统;
-k :以 KBytes 的容量显示各文件系统;
-m :以 MBytes 的容量显示各文件系统;
-h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示;
-H :以 M=1000K 取代 M=1024K 的进位方式;
-T :连同该 partition 的 filesystem 名称 (例如 xfs) 也列出;
-i :不用磁盘容量,而以 inode 的数量来显示 范例:
zzz@Ubuntu:~$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
udev devtmpfs 983M 0 983M 0% /dev
tmpfs tmpfs 201M 7.7M 193M 4% /run
/dev/vda1 ext4 40G 3.0G 35G 8% /
tmpfs tmpfs 1001M 0 1001M 0% /dev/shm
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs tmpfs 1001M 0 1001M 0% /sys/fs/cgroup
tmpfs tmpfs 201M 0 201M 0% /run/user/1001相关解释:
- Filesystem:代表该文件系统是在哪个 partition ,所以列出装置名称
- Used:顾名思义,就是使用掉的磁盘空间
- Available:也就是剩下的磁盘空间大小
- Use%:就是磁盘的使用率,如果使用率高达 90% 以上时, 最好需要注意
- Mounted on:就是磁盘挂载的目录(挂载点)
- 那个 /dev/shm/ 目录,其实是利用内存虚拟出来的磁盘空间,通常是总物理内存的一半
du 命令格式:
[root@study ~]# du [-ahskm] 文件或目录名称
选项与参数:
-a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。
-h :以人们较易读的容量格式 (G/M) 显示;
-s :列出总量而已,而不列出每个各别的目录占用容量;
-S :不包括子目录下的总计,与 -s 有点差别。
-k :以 KBytes 列出容量显示;
-m :以 MBytes 列出容量显示相关解释:
- 直接输入 du 没有加任何选项时,则 du 会分析 目前所在目录 的文件与目录所占用的磁盘空间。
- 在默认的情况下,容量的输出是以 KB 来设计的,使用 -m 这个参数可得到 MB为单位
实体链接与符号链接: ln
Hard Link (实体链接, 硬式连结或实际连结)
我们知道:
- 每个文件都会占用一个 inode ,文件内容由 inode 的记录来指向
- 想要读取该文件,必须要经过目录记录的文件名来指向到正确的 inode 号码才能读取
文件名只与目录有关,文件内容则与 inode 有关,如果多个文件名对应到同一个 inode 号码就是 Hard link。hard link 只是在某个目录下新增一笔档名链接到某 inode 号码的关连记录而已。
范例:
zzz@Ubuntu:/tmp$ ll -i /etc/crontab
1048713 -rw-r--r-- 1 root root 722 Apr 6 2016 /etc/crontab
zzz@Ubuntu:/tmp$ sudo ln /etc/crontab .
zzz@Ubuntu:/tmp$ ll -i /etc/crontab crontab
1048713 -rw-r--r-- 2 root root 722 Apr 6 2016 crontab
1048713 -rw-r--r-- 2 root root 722 Apr 6 2016 /etc/crontab相关解释:
- 可以看到两个文件的inode号码都为 1048713,且两个文件的权限相同
- 第二个 连结 字段由 1 变成了 2,其意义是有多少个档名链接到这个 inode 号码
- 将任何一个 档名 删除,其实 inode 与 block 都还是存在的
- hard link 只是在某个目录下的 block 多写入一个关连数据而已, 既不会增加 inode 也不会耗用 block 数量
Symbolic Link (符号链接,亦即是快捷方式)
Symbolic link 就是在建立一个独立的文件,而这个文件会让数据的读取指向他 link 的那个文件的档名.所以,当来源档被删除之后,symbolic link 的文件会打不开了, 会提示No such file or directory 。实际上就是找不到原始文件。
经测试,符号连结记录的内容仅仅是文件的文件名,如果将源文件删除,在新建一个同名文件符号连结文件指向新的文件。
Symbolic Link 与 Windows 的快捷方式可以给他划上等号,由 Symbolic link 所建立的文件为一个独立的新的文件,所以会占用掉 inode 与 block 。
ln 命令格式:
[root@study ~]# ln [-sf] 来源文件 目标文件
选项与参数:
-s :如果不加任何参数就进行连结,那就是 hard link,至于 -s 就是 symbolic link
-f :如果 目标文件 存在时,就主动的将目标文件直接移除后再建立符号连结并不能增加 连结 字段数量,目录的 连结 字段数量是由新增目录( . 和 .. ,新的目录的 link 数为 2 ,而上层目录的 link 数则会增加 1 )而的增加而改变的。
磁盘的分区、格式化、检验与挂载
在 Linux 中新增一颗硬盘需要的操作:
- 对磁盘进行分区,以建立可用的 partition(分区之前要确定磁盘的分区格式GPT or MBR)
- 该 partition 进行格式化 (format),以建立系统可用的 filesystem(xfs or ext4)
- 可对刚刚建立好的 filesystem 进行检验
- 建立挂载点 (亦即是目录),并将他挂载上来
观察磁盘分区状态
常见命令有lsblk 、 blkid、 parted
lsblk列出系统上所有的磁盘列表(未挂载的也会显示出来)
lsblk 可以看成 list block device 的缩写,列出所有储存装备
命令格式:
[root@study ~]# lsblk [-dfimpt] [device]
选项与参数:
-d :仅列出磁盘本身,并不会列出该磁盘的分区数据
-f :同时列出该磁盘内的文件系统名称
-i :使用 ASCII 的线段输出,不要使用复杂的编码 (再某些环境下很有用)
-m :同时输出该装置在 /dev 底下的权限数据 (rwx 的数据)
-p :列出该装置的完整文件名!而不是仅列出最后的名字而已。
-t :列出该磁盘装置的详细数据,包括磁盘队列机制、预读写的数据量大小等 - blkid 列出装置的 UUID 等参数(列出格式化后的区块)
UUID 是全局单一标识符(universally unique identifier),Linux会给系统内所有装置给予一个独一无二的标识符。 - parted 列出磁盘的分区表类型与分区信息,修改磁盘的分区格式(MBR or GPT)
如果仅查看相关信息的话使用parted devicename print命令
磁盘分区
分区前需要确定磁盘的分区格式(MBR or GPT),使用parted devicename 然后在内部使用 mklabel gpt 可以将磁盘设置为 gpt 分区格式, 使用mklabel msdos 设置为 mbr 分区格式。
设置完分区格式后就可以分区了,MBR 分区表 使用 fdisk 进行分区,GPT分区表使用gdisk 分区。fdisk 与 gdisk 命令很相似。
命令格式: gdisk devicename fdisk devicename,比如:gdisk /dev/sdb
使用命令后进入内部命令区,命令区的常用命令含义:
d delete a partition # 删除一个分区
n add a new partition # 增加一个分区
p print the partition table # 印出分区表 (常用)
q quit without saving changes # 不储存分区就直接离开 gdisk
w write table to disk and exit # 储存分区操作后离开 gdisk 分区信息在 /proc/partitions 中有记录,刚新增的分区不会立即同步到文件内,可以通过 partprobe -s 命令更新。
磁盘格式化(建置文件系统)
磁盘格式化就是讲一个分区设置为需要的文件系统(xfs or ext4),使用命令 mkfs (make filesystem 的缩写)。格式化后,可以通过命令 blkid devicename 查看UUID,比如:blkid /dev/sdb1。
- XFS 文件系统 mkfs.xfs
一般使用默认指令mkfs.xfs devicename即可,通过参数可以设置 inode size,block size - EXT4 文件系统 mkfs.ext4
一般使用默认指令mkfs.ext4 devicename即可。 - 其他文件系统,使用命令
mkfs[tab][tab]即可查看支持的文件系统
文件系统的检验
当出现断电等导致宕机情况发生时,文件系统会有磁盘与内存数据异步情况,可能导致文件系统错误。
- xfs_repair 处理 XFS 文件系统
命令格式:
[root@study ~]# xfs_repair [-fnd] 装置名称
选项与参数: -f :后面的装置其实是个文件而不是实体装置
-n :单纯检查并不修改文件系统的任何数据 (检查而已)
-d :通常用在单人维护模式底下,针对根目录 (/) 进行检查与修复的动作!很危险!不要随便使用 - fsck.ext4 处理 EXT4 文件系统
fsck是个综合指令,如果针对 ext4 使用fsck.ext4较好
命令格式:
[root@study ~]# fsck.ext4 [-pf] [-b superblock] 装置名称
选项与参数:
-p :当文件系统在修复时,若有需要回复 y 的动作时,自动回复 y 来继续进行修复动作。
-f :强制检查!一般来说,如果 fsck 没有发现任何 unclean 的旗标,不会主动进入细部检查的,如果您想要强制 fsck 进入细部检查,就得加上 -f 旗标啰!
-D :针对文件系统下的目录进行优化配置。
-b :后面接 superblock 的位置!一般来说这个选项用不到。但是如果你的 superblock 因故损毁时,透过这个参数即可利用文件系统内备份的 superblock 来尝试救援。一般来说,superblock 备份在:1K block 放在 8193, 2K block 放在 16384, 4K block 放在 32768通常只有 root 用户且文件系统有问题的时候才使用这个指令,否则在正常状况下使用此一指令可能会造成 对系统的危害,执行 xfs_repair / fsck.ext4 时,被检查的 partition 不能挂载在系统上。
文件系统挂载与卸除
挂载前需要的准备:
- 单一文件系统不应该被重复挂载在不同的挂载点(目录)中
- 单一目录不应该重复挂载多个文件系统
- 要作为挂载点的目录,理论上应该都是空目录
如果原目录不为空那么挂载后,原目录内的文件会暂时消失,卸除后恢复显示
挂载命令为 mount ,命令格式:
[root@study ~]# mount -a
[root@study ~]# mount [-l]
[root@study ~]# mount [-t 文件系统] LABEL='' 挂载点
[root@study ~]# mount [-t 文件系统] UUID='' 挂载点 # 鸟哥近期建议用这种方式喔!
[root@study ~]# mount [-t 文件系统] 装置文件名 挂载点
选项与参数: -a :依照配置文件 /etc/fstab 的数据将所有未挂载的磁盘都挂载上来
-l :单纯的输入 mount 会显示目前挂载的信息。加上 -l 可增列 Label 名称!
-t :可以加上文件系统种类来指定欲挂载的类型。常见的 Linux 支持类型有:xfs, ext3, ext4, reiserfs, vfat, iso9660(光盘格式), nfs, cifs, smbfs (后三种为网络文件系统类型)
-n :在默认的情况下,系统会将实际挂载的情况实时写入 /etc/mtab 中,以利其他程序的运作。 但在某些情况下(例如单人维护模式)为了避免问题会刻意不写入。此时就得要使用 -n 选项。
-o :后面可以接一些挂载时额外加上的参数!比方说账号、密码、读写权限等: 现在不需要加上 -t 这个选项,系统会自动的分析最恰当的文件 系统来尝试挂载你需要的装置文件。系统几乎都有 superblock , Linux 可以透过分析 superblock 搭配 Linux 自己的驱动程序去测试挂载, 如果成功的套和了,就立刻自动的使用该类型 的文件系统挂载起来。其参考文件:
- /etc/filesystems:系统指定的测试挂载文件类型的优先级
- /proc/filesystems:Linux系统已经加载的文件系统类型
Linux 支持的文件系统之驱动程序都写在如下的目录中:/lib/modules/$(uname -r)/kernel/fs/
范例:
[root@centos764 ~]# cd learn/test/
[root@centos764 test]# blkid /dev/sdb2
/dev/sdb2: UUID="de0f4e15-4905-4d76-9026-7f835a20d3f4" TYPE="ext4" PARTLABEL="Linux filesystem" PARTUUID="5997bc72-0f8b-4ad2-bcd2-2dd4fb366a8c"
[root@centos764 test]# mount UUID='de0f4e15-4905-4d76-9026-7f835a20d3f4' .
[root@centos764 test]# df ~/learn/test/
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sdb2 999320 2564 927944 1% /root/learn/testlinux 中不支持 NTFS 的文件系统的U盘的挂载,要想将U盘挂载到 Linux 中,必须将U盘格式化。
卸载命令为 umount :命令格式: umount [-fn] 装置文件名或挂载点,例如 umount /dev/sdv1
设定开机挂载
开机挂载/etc/fstab 及 /etc/mtab
系统挂载的限制
- 根目录 / 是必须挂载的﹐而且一定要先于其它 mount point 被挂载进来
- 其它 mount point 必须为已建立的目录﹐可任意指定﹐但一定要遵守必须的系统目录架构原则 (FHS)
- 所有 mount point 在同一时间之内﹐只能挂载一次
- 所有 partition 在同一时间之内﹐只能挂载一次
- 若进行卸除﹐必须先将工作目录移到 mount point(及其子目录) 之外
/etc/fstab(filesystem table) 是挂载时的选项与参数的文件,共有六个字段:
[root@study ~]# cat /etc/fstab
# Device Mount point filesystem parameters dump fsck
/dev/mapper/centos-root / xfs defaults 0 0
UUID=94ac5f77-cb8a-495e-a65b-2ef7442b837c /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0 相关解释:
- 第一栏:磁盘装置文件名/UUID/LABEL name,使用 UUID 较为准确
- 第二栏:挂载点(mount point)
- 第三栏:磁盘分区槽的文件系统
- 第四栏:文件系统参数
- 第五栏:能否被 dump 备份指令作用
- 第六栏:是否已fsck 检验扇区
若想让一个文件系统开机挂载,那么按照这六栏填写并保存到 /etc/fstab 中即可。
特殊装置 loop 挂载
阿里云的服务器就是用的 loop 挂载~
loop 挂载的步骤:
- 建立大型文件
dd if=/dev/zero of=/srv/loopdev bs=1M count=512 - 大型文件格式化
mkfs.xfs -f /srv/loopdev跳过了分区表设置,默认为 loop 分区格式也可修改为GPT or MBR 分区表格式 - 挂载
mount /srv/loopdev /mnt
内存置换空间(swap)之建置
CPU 所读取的数据都来自于内存, 当内存不足的时候,为了让后续的程序可以顺利的运作,因此在内存中 暂不使用的程序与数据就会被挪到 swap 中。
建立 swap 有两种方法:
- 设定一个swap partition
- 建立一个虚拟内存文件
使用实体分区槽建置 swap
步骤如下:
- 分区,先使用 gdisk 在你的磁盘中分区出一个分区槽给系统作为 swap 。由于 Linux 的 gdisk 预设会将分 区槽的 ID 设定为 Linux 的文件系统,所以你可能还得要设定一下 system ID。
- 格式化:使用命令
mkswap 装置文件名格式化该分区槽成为 swap 格式。 - 使用:将该 swap 装置启动,方法为:
swapon 装置文件名。
范例:
[root@centos764 ~]# gdisk /dev/sdb
GPT fdisk (gdisk) version 0.8.6
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): p
Disk /dev/sdb: 20971520 sectors, 10.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 9952BB36-8485-48E1-99EC-FCC5A9488A7E
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 20971486
Partitions will be aligned on 2048-sector boundaries
Total free space is 16777149 sectors (8.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 2099199 1024.0 MiB 8300 Linux filesystem
2 2099200 4196351 1024.0 MiB 8300 Linux filesystem
Command (? for help): n
Partition number (3-128, default 3):
First sector (34-20971486, default = 4196352) or {+-}size{KMGTP}:
Last sector (4196352-20971486, default = 20971486) or {+-}size{KMGTP}: +512M
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300): 8200 # 选择 swap 格式
Changed type of partition to 'Linux swap'
Command (? for help): p
Disk /dev/sdb: 20971520 sectors, 10.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 9952BB36-8485-48E1-99EC-FCC5A9488A7E
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 20971486
Partitions will be aligned on 2048-sector boundaries
Total free space is 15728573 sectors (7.5 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 2099199 1024.0 MiB 8300 Linux filesystem
2 2099200 4196351 1024.0 MiB 8300 Linux filesystem
3 4196352 5244927 512.0 MiB 8200 Linux swap
Command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/sdb.
The operation has completed successfully.
[root@centos764 ~]# mkswap /dev/sdb3
正在设置交换空间版本 1,大小 = 524284 KiB
无标签,UUID=efb2b703-88ae-4db5-97f8-47ca1480be0c
[root@centos764 ~]# blkid /dev/sdb3
/dev/sdb3: UUID="efb2b703-88ae-4db5-97f8-47ca1480be0c" TYPE="swap" PARTLABEL="Linux swap" PARTUUID="a5995a6b-e0d8-4dae-b3f2-999dbc8c6e43"
[root@centos764 ~]# free
total used free shared buff/cache available
Mem: 1865252 1034280 376356 22288 454616 570804
Swap: 2097148 264 2096884 # 会增大
[root@centos764 ~]# swapon /dev/sdb3 # 使用
[root@centos764 ~]# free
total used free shared buff/cache available
Mem: 1865252 1034576 376032 22288 454644 570540
Swap: 2621432 264 2621168 # 变大了
[root@centos764 ~]# swapon -s # 查看有哪些 swap 装置
文件名 类型 大小 已用 权限
/dev/dm-1 partition 2097148 264 -1
/dev/sdb3 partition 524284 0 -2使用文件建置 swap
步骤如下:
- 使用 dd 这个指令来新增一个 128MB 的文件在 /tmp 底下:
dd if=/dev/zero of=/tmp/swap bs=1M count=128 - 使用 mkswap 将 /tmp/swap 这个文件格式化为 swap 的文件格式:
mkswap /tmp/swap - 使用 swapon 来将 /tmp/swap 启动
swapon /tmp/swap
使用 swapoff devicename 将 swap 停用,例如 swapoff /tmp/swap。
总的来说swap 来是需要建立的,只是不需要太大。
个人博客原文地址 : Linux 磁盘与文件系统