python如何实现将数据批量划分至数据集(训练集、验证集、测试集)中-----自动划分数据集
在进行机器学习或深度学习的过程中,有时候可能会涉及到大量的数据,在前期处理的时候,可能会涉及到数据集的划分问题。这时候可以用python来实现。
- 导入必需的库
import re
import hashlib
import six as _six
import os
import shutil
一共导入五个库,其中os和shutil是用来将数据放入划分好的数据集的,前三个则用来做划分工作。
- 定义一个函数
def as_bytes(bytes_or_text, encoding='utf-8'):
"""Converts `bytearray`, `bytes`, or unicode python input types to `bytes`.
Uses utf-8 encoding for text by default.
Args:
bytes_or_text: A `bytearray`, `bytes`, `str`, or `unicode` object.
encoding: A string indicating the charset for encoding unicode.
Returns:
A `bytes` object.
Raises:
TypeError: If `bytes_or_text` is not a binary or unicode string.
"""
if isinstance(bytes_or_text, bytearray):
return bytes(bytes_or_text)
elif isinstance(bytes_or_text, _six.text_type):
return bytes_or_text.encode(encoding)
elif isinstance(bytes_or_text, bytes):
return bytes_or_text
else:
raise TypeError('Expected binary or unicode string, got %r' %
(bytes_or_text,))
这个函数来源于tensorflow的一个实例,功能非常简单,就是统一编码格式,可以将bytearay、unicode字符串等对象转换成utf-8编码的格式。
- 设置默认参数
file=os.listdir('此处为文件夹路径')
MAX_NUM_WAVS_PER_CLASS=2*27-1
train_percentage=60
validation_percentage=80
testing_percentage=90
以上共五个参数,
file为根据文件夹路径生成的路径下全部文件列表;
MAX_NUM_WAVS_PER_CLASS为一个任意值,是决定后续哈希值生成占比的一个度量值;
train_percentage、validation_percentage、testing_percentage分别是训练集、验证集、和测试集的占比度量值(可理解为上限值)。
- 运行代码进行集合划分
for filename in file:
print(filename)
base_name = os.path.basename(filename)
hash_name = re.sub(r'_2_.*$', '', base_name)
hash_name_hashed = hashlib.sha1(as_bytes(hash_name)).hexdigest()
percentage_hash = ((int(hash_name_hashed, 16) % (MAX_NUM_WAVS_PER_CLASS + 1)) *(100.0 / MAX_NUM_WAVS_PER_CLASS))
print(percentage_hash)
if train_percentage运行上述代码之前,需要现在目标文件夹根目录下创建三个文件夹train、validation、test,代码也很简单,如下:
mkdir train
mkdir validation
mkdir test
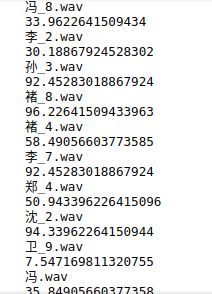
以自己的一个小数据库作为材料中运行上述代码后,结果如下,文件名后的分数即决定其对应的数据集。
- 补充1
如果感觉结果还不够清晰,也可以在运行代码前在代码块最后再加一行代码
print(file_dst)
- 补充2
对于代码块本身的运行机制,因为非常简单,所以不再详细阐述。如果有人不太清楚以上三个函数的使用,可以参考以下链接:
os.path
hashlib
int()
re.sub
- 结束