之前页表结构的不足
之前的页表结构看起来挺好的呀,有什么问题呢?
如果每个页的大小是4k,也就是2的12次方。如果是32位的地址话,也就是说,有2的20次方个页。
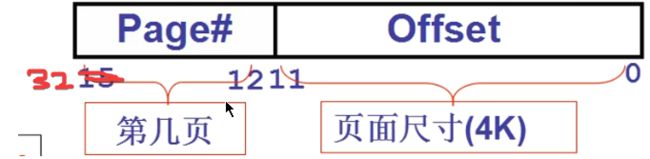
那么对应到页表,也就说页表应该有2的20次方个项。因为每个项表示的是一个内存地址,也就说一个项的大小是32位,也就是4个字节。
这样算下来,对应于一个32位的内存地址,一个页表应该4M大小。看起来还可以接受啊。
但注意,每个进程都有一个页表。看下,我的电脑现在有280个进程,也就说如果采用之前的结构,光页表结构就得占用280*4M=1120M,大约1个G的大小。如果是64位系统,会更加可怕。
引入多级页表
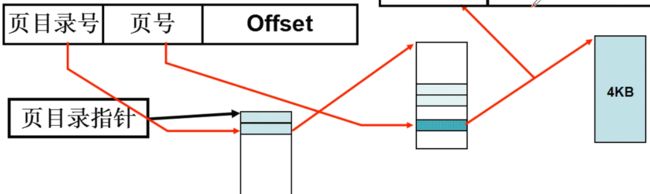
之前的一级页表,我们对于32位系统,4k为一页的时候,我们如果要去访问2的20次方的页表,去查找空闲空间,或者访问某一个页内数据。
现在,我们采用多级页表,如上图所示的是二级页表。
我们如果想访问某一个地址,我们首先通过一个页目录号,在第一个页表(页目录表)中获得一个地址。这个地址指向第二个页表的开始位置,然后用页号作为偏移,在第二个页表中获得地址,进而访问内存中的块。
想象这样一个场景:如果,你现在有一本书,你想跳转到某一页。这本书每一页都没有页码,只有目录有相关页码。
我们想要翻到的页码,提供这些信息:
- 它是属于内存相关内容的
- 它在所在章节开始位置处的第60页
于是,你打开了目录,但是这个目录也跟平时不一样,它只有显示每一章的页码,比如:第一章,进程,100页;第二章,内存,200页。没有节的页码。
现在,我们想访问的内容知道是属于第二章的,于是我们直接来到第200页。
(我们从页目录表来到了第二级页表)。
最后我们从这个位置,往后找到第60页的位置。
(从二级页表偏移页号找到对应的页)
多级页表的内存占用
多级页表的内存占用和 页目录号、页号的位数分配有关系。假定我们假设页目录号、页号各占10位。
在 Linux 0.11 中,页目录号是所有进程共享的,有的系统每个进程都有一个页目录号,当然也都有一个页表。
所以,一个进程中有2的10次方(1K)的页目录表 和 2的10次方(1K)的页号。因为每个表项大小为4字节,总共,一个进程才占 8K 而已。比之前的 4M,大大节省了内存。
快表
至此,看起来,已经优化的差不多了。
但是,人们不止于此,想进一步提高性能。那么如何提高性能呢?
缓存。
对于很多大量需要访问的问题,都使用缓存,利用了程序的局部性原理。像我们的CPU的多级缓存都是使用这种原理。但是,一般缓存使用的寄存器价格都比较昂贵,所以一般存储都有限。
快表,实质上也是缓存。
快表,TLB(translation lookasider buffer),翻译后备缓冲器。
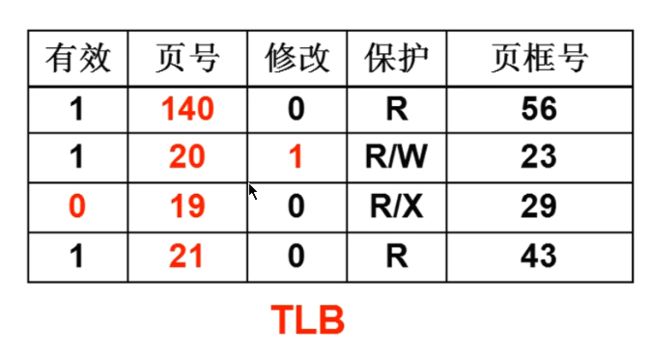
他就是保存最近的访问的一些查表信息,如果有一个新的地址需要去访问,先到 TLB 中看能不能找到,如果找不到,再按照之前的方式老老实实查询,如果可以找到,直接返回结果。
更多细节,我们在后面讲解。