基于区块链技术的性能测试
作者:大开科技-曹向志
摘要:本次测试是受甲方公司委托,对运用区块链技术的一个应用后台系统进行负载测试,主要是评估系统在系统资源正常利用率下TPS是否能够达到20000,并发用户超过2000,响应时间不超过0.2秒。测试环境搭建全部基于云上,可以根据需要扩展应用服务器和压力机。建立在区块链技术上的应用系统特点是部署在Docker里,且只能通过后台服务接口调用,部署在Tomcat之上,Berkeley DB内存数据库的key-value形式,是一个之前未曾测试过的一种部署。之前听同行说过,云上服务器不好监控,这次又是在Docker里面,是否可以监控呢?等着我们的是否是一次挑战呢?
前言:
当前,各行各业都在研究区块链技术的运用,区块链技术依据其自身所具备特性可部分或全部运用到某些业务领域,推动该业务领域的创新,例如:银行、保险、游戏、电商等以及有实力的软件服务集成商都投入团队研究区块链技术。其中虚拟货币可能是最适合区块链技术运用的方向之一。我们有幸负责该领域一个软件系统的性能测试,接触到该业务领域。实属幸运!
系统背景:
区块链解决的是不可信网络下的分布式共识计算方案。区块链的效率以及规模,取决于核心共识算法。包括合法性、完整性、可终止性三个重要属性。从最早的拜占庭将军问题,引出一种容错理论。随后1985年 Fischer和Lynch发表了FLP不可能性定论和1998年Eric Brewer的CAP的三角理论法,给异步网络下共识模型提供了很好的理论基础。
在共识算法理论基础下,有很多实现的计算机算法,例如Paxos、Raft、PBFT等。PBFT提出了实际的解决方案,系统通过访问控制来限制失效客户端可能造成的破坏,审核客户端并阻止客户端发起无权执行的操作。同时,服务可以提供操作来改变一个客户端的访问权限。因为算法保证了权限撤销操作可以被所有客户端观察到,这种方法可以提供强大的机制从失效的客户端攻击中恢复。
BTC比特币采用挖矿记账方式,即工作量证明(PoW)来解决BFT的问题。由矿工用计算机算力来解密码学题目的方式争夺记账权利,并且给予胜利者一定比特币的奖励。工作量证明机制完全依靠经济激励的方式来大量增加记账参与者,从而稀释作恶节点的比例,或者说大幅增加作恶的成本,做假账者需要控制或者贿赂更多的节点。现在体量最大的两条交易区块链,比特币和以太坊ETH都是用PoW挖矿的方式。
共识的性能决定了给链的节点间视图数据信息一致性效率。而同步的视图的数据,需要提供更大的存储空间,才能为整个链提高区块的批量效率。
系统性能测试需求:
该系统主要运用了区块的形成机制,在多个节点上达成共识。通过基本账户转账交易、智能合约转账、随机合约调用转账三种机制,在多个节点上形成共识。
该系统的性能指标要求:
- 并发用户2000
- TPS 2万/秒
- 平均响应时间0.2s
- 10个节点资源监控正常
- 事务成功率达到100%
测试类型:单交易基准测试、单交易负载测试、混合业务负载测试,如果有时间,进行稳定性测试
客户提供的测试环境:
应用服务器软硬件环境:阿里云 Intel(R) Xeon(R) Gold 6148 CPU 2.4GHz,16CPU、16G;软件:操作系统CentOS 7.0,内存数据库
压力机软硬件环境:阿里云Inter(R) Xeon(R)Gold 614、8 CPU; CPU:Inter(R) Pentium(R) CPU G2030,2.40GHZ,8CPU内存16G;操作系统:Windows server 2012
测试环境拓扑图如下:
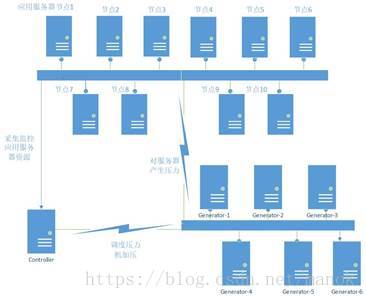
性能测试需求分析:
该系统主要对并发用户数、响应时间、TPS、事务正确率有比较高的要求,各应用节点资源要求使用率不高于80%,对于Linux(CentOS)平台来说,应该控制在65%利用率左右。由于该应用特点是采用节点扩展方式,所以测试的重点是通过执行测试,找到服务器的处理能力,为后续的上线做一个服务器选择的参考。
测试设计:
系统要求测试类型,单交易基准测试、单交易负载测试、混合交易负载测试。主要是确定典型交易,通过沟通,确定典型交易共有6个,基本账户转账、智能合约转账、随机合约调用、交易查验、区块查验和账户查验。每个交易所占比例基本相同。被测试系统使用Tomcat部署,整个应用部署在docker里,每台服务器也可以部署多个Docker,在测试里,没有赞成这样部署。
对于应用服务器的监控,考虑可以通过Loadrunner结合vmstat、top等命令行工作监控,对于JVM考虑是否可以通过jvisulevm监控。实际上无法监控。JDK版本为1.7。还是原来的内存分配和回收策略。还没有升级到1.8,采用元空间的方式。对于JDK,最后方案选择使用jstat在Docker里进行监控。
对于使用多少台应用服务器和压力机能够达到要求的性能指标,无法评估,只能通过在测试几个场景后,才能评估获得。
压力机尽量采用低版本的Windows server版本,因为是云上服务器,只提供服务器版本。对于高版本的Windows sever有可能在测试过程中遇到未曾遇到的新问题。
风险考虑:
由于性能测试团队第一次在基于云上的测试环境进行测试,可能会遇到资源监控、应用服务器和压力机等环境上的各种问题。
监控的服务器节点比较多,一台Controller是否可以做到,需要在测试过程中评估。
对于测试过程中脚本和参数化数据,是否容易构造,且能够高效率的构造,否则会消耗太多的时间构造测试用数据。
典型交易脚本编写:
由于上述6个交易类型全部为后台交易,需要游戏前端调用产生交易,是无法录制脚本再增强脚本的。设计有两种方案,第一种方案是编写调用后台方法,这样需要开发提供交易接口,还需要提供鉴权方法,以及hash产生方法。第二种方案是由开发封装6个交易方法,只是提供测试调用接口即可。最后通过商议,开发决定采用第二种方案。这可能是开发觉得比较安全的方式。:)
 基本账户转账的访问代码如下:
基本账户转账的访问代码如下:
上面代码是运用到每一个节点。代码中主要通过注册函数获得访问基本交易转账返回的hash值,把值保存在文件中。该值用例作为基本交易查验的hash值参数传入。每个节点划分为一个事务。单独统计事务各相关性能指标。
脚本处理上没有技术障碍,主要是请求中支持json报文格式,压力机写本地文件,使用了每个交易写一个文件,减少文件增大时,写入的速度。且在每个压力机上分别创建目录和空间记录返回值。
在场景设置中,由于并发量比较大,在加压过程、减压过程中注意根据前面的试运用过程,掌握每个虚拟用户的初始化时间,减压时间等,使产生的监控曲线更方便度量和处理。
测试执行过程:
单交易基准测试,主要是1个虚拟用户迭代10次获得各种性能指标,主要是查看响应时间,其它指标一般都不会超过指标要求。通过对6个典型交易的基准测试,调试好脚本。测试表名,所有指标都OK。
单交易负载测试,主要是单独对每一个交易做2000并发用户测试。为了节省测试时间,没有采用每次执行并发用户递增方式,而是直接使用2000个并发执行测试。监控JVM、服务器的资源使用情况。单交易负载测试,尤其是基本交易转账交易,先后执行多次,通过该交易评估出每分钟需要的hash数,以便后面测试场景设计的执行时间来估算构造数据量。也通过该交易,评估出达到2000个并发需要的应用服务器数量和压力机数量。解决资源监控和记录返回报文的解析出hash值的左右边界以及写文件方案等。
混合业务负责测试,6个典型交易采用按照等比例的方式,直接使用2000个并发用户进行负载测试,在测试执行过程中,出现并发虚拟用户无法加载,最多加载达到1669个并发用户。监控JVM、服务器的资源使用情况。
整个测试执行过程,有效的测试场景共14个,6个基准,6个单交易,2个混合。
在测试过程中,发现的系统问题主要有:
1、TPS呈现多个波峰现象,处理不稳定。
通过与加载的虚拟用户数量,处理tps以及服务器资源情况判断,主要是通过监控JVM垃圾回收情况判断得出,每隔10秒左右的垃圾回收正好与生成的tps曲线基本一致。初步分析,JVM年老代一直占满,而年轻代每隔20秒左右满,这样导致年轻代触发垃圾回收,在垃圾回收的几秒内,tps降低到几乎为零。为什么在运行初期,年老代会被占满呢?这与在构造测试数据时可能有关系,每次测试执行之前构造上百万的测试数据,这些数据构造过程中,占满了年老代,这可能与开发团队采用的构造数据代码使用堆内存方式有关系。解决方案是每次构造数据后,重新启动服务器,这样构造的测试数据在文件里,而不是直接在内存里,在-Xms和Xmx参数设定中,都是设定的可使用4G内存。这样解决了该问题,由于生产中,不用在开始时,构造上百万的测试数据,不会造成很短时间内进行垃圾内存回收。
2、在混合业务时,后台日志中抛出并发超时错误。
在混合业务2000个并发测试执行中,前台观察到的大约200多个虚拟用户由于失败等原因停止。开发人员监控后台日志,发现抛出了大约20个左右的并发超时异常信息。该问题,在测试之前阶段,测试和开发人员无法分析出问题原因,2000个并发用户,分布到10个服务器节点,每个服务器承担了约200个并发用户,理论上对于16CPU16G内存的服务器来说,应该能够承受。具体原因,需要架构师进行深入分析。
在部署10台服务器节点,使用6台压力机和1台Controller进行压力测试情况下,无法达到2000个并发,但是TPS能达到20000的要求,响应时间不管是在单交易并发还是混合交易并发情况下,都不超过0.2秒的响应时间。交易成功率虽然无法达到100%,但是超过了99.99%,有少量的失败或停止。增加服务器节点和压力机应该可以达到性能要求指标。由于该系统是通过添加服务器节点来支持更多的并发用户数量,但是有不是线性关系,毕竟每增加一个节点,其在合约判定上都会增加时间消耗。
测试过程问题:
在测试过程中,曾经出现的问题和解决方案如下:
1、压力机问题,在开始时,单业务2000个并发用户时,会出现虚拟用户加载时间过长,或用户中间由于错误、超时等原因停止。采取的措施是增加压力机的方法,由3台压力机增加到6台,这样controller不再兼做压力机了,对于服务器性能指标监控就更及时一些。
2、监控CentOS时,没有安装RPC服务。通过下面方法安装RPC服务,安装后,启动3个服务解决。
Step 1 安装RPC相关程序
执行命令:yum install inetd,这一步是为了安装rstatd的守护进程
执行命令:yum install rusers-server
Step 2 启动服务
service rpcbind start
service xinetd start
service rstatd start
3、构造测试用例数据
 测试过程中,比较麻烦是进行大量交易hash值的构造,该值本来应该是在客户端每次调用服务时产生,而现在是需要在进行执行压力测试之前产生。通过post调用,在内存数据库中产生需要的hash值,只要服务器不重启,该值一直存在。在下面的post提交的前3个值确定构造3种交易hash的值的数量。
测试过程中,比较麻烦是进行大量交易hash值的构造,该值本来应该是在客户端每次调用服务时产生,而现在是需要在进行执行压力测试之前产生。通过post调用,在内存数据库中产生需要的hash值,只要服务器不重启,该值一直存在。在下面的post提交的前3个值确定构造3种交易hash的值的数量。
4、2000个并发时,Controller出现下面错误信息。
Action.c(35): Error -27796: Failed to connect to server "172.17.0.10:38000": [10048] Address already in use.TrychangiACAL_MACHINE\System\CurrentControlSet\Services\tcpip\Parameters\TcpTimedWaitDelay to 30 and HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\tcpip\Parameters\MaxUserPort to 65534 and rebooting the machine See the readme.doc file for more information
按照提示信息,判断可能是压测目标是一个简单方法调用,服务器端口数不够造成的。根据上面提示在注册表中已将压力机注册表中的TcpTimedWaitDelay 改为 1;MaxUserPort 改为 65534;并且重启电脑,运行压力仍出现上面的错误。之后在 run-time setting/browser emulation中将simulate a new user on each iteration 选项去掉,重新运行一切正常,不再有错误出现。每次迭代不再模拟一个新的虚拟用户,这样相当于保持客户机和服务器连接,也不用每次迭代下载数据。具体的原因需要更深入研究Loadrunner本身的机制。
5、在3台压力机时,压力机本身的CPU、内存等资源充足,但是模拟的用户数量却上不去?
我们的压力机安装的windows sever 2008。在Windows计算机的标准设置下,操作系统已经默认限制只能使用最大线程数所导致。修改注册表可以打开该限制。
(1)HKEY_LOCAL_MACHINE找到:System\CurrentControlSet\Control\Session Manager\SubSystems。
(2)找到下面字段:
%SystemRoot%\system32\csrss.exe bjectDirectory=\Windows
SharedSection=1024,3072,512 Windows=On SubSystemType=Windows ServerDll=basesrv,1
ServerDll=winsrv:UserServerDllInitialization,3 ServerDll=winsrv:ConServerDllInitialization,2
ProfileControl=Off MaxRequestThreads=16
其中SharedSection=1024,3072,512格式为xxxx,yyyy,zzz,其中,xxxx定义了系统范围堆的最大值(以KB为单位),yyyy定义每个桌面堆的大小。
(3)将yyyy的设置从3072更改为8192(即8MB),增加SharedSection参数值。
通过对注册表的更改,系统将允许运行更多的线程,产生更多的Vuser。另外,也需要调整Loadrunner本身对压力机的控制。在loadrunner中,默认的是每50个vuser会使用一个mdrv.exe进程,可以启动多个mdrv.exe的进程,每个进程中的vuser数量少一点,具体的办法如下:安装目录下"dat"protocols"CsNet.lrp文件中,在[Vugen]下面新加一条MaxThreadPerProcess=要设置的vuser数量。这样每个mdrv.exe进程中的vuser数量就是设置的数量。
6、Docker中JVM监控问题。
JVM监控可以使用JDK自带的jvisualvm应用监控,通过图形判断比使用jstat等命令监控更方便一些。但是Docker中的JVM外部是访问不了,所以,我们使用了jvisualvm监控了服务器的JVM。Docker内部的JVM只能通过命令行,进行监控。
7、Loadrunner在大量并发写文件问题分析。
在大量并发用户执行过程中,发现了Loadrunner写文件上的问题。在两个事务中,要把产生的hash值写入文件中,目的是为了检查返回的hash值是否正确。发现在记录的文件中,大约1%左右的hash值记录的长度超长或缩短了,Loadrunner在大量的并发用户在同时写一个文件时,是否会出现,一个线程时间片写不完,下个时间片再写导致出错呢?或者是系统在返回hash只上面就有问题。解决方法是在写文件时,首先对根据左右边界找到的hash值进行长度判断,如果长度等于要求的长度64,则写入,否则不写文件。这样再次执行写入文件时,发现还是会出现超过64个字符长度或缩短的问题,是否是loadrunner本身的问题,需要后续研究。在后面的调用查验事务时,直接通过关联把hash值插入,也不会出现hash值不正确问题。
8、在对运用区块链技术的系统性能测试中,出现了很多问题,有些没有在上面列出,例如,京东云的不稳定,腾讯云的不稳定,最后换成阿里云,应用服务器和压力机才比较稳定下来。刚开始时压力机安装的Windows sever 2012,作为压力机限制较多,后面换成阿里云后,全部换成Windows server 2008,远程桌面连接和rps服务使用起来方便很多。用服务器版本作为压力机应该不是最佳选择,但是由于租用的服务器上无Win 7等,所以只能这样选择。在测试过程中,开发人员遇到系统上的问题,也会升级解决,没有把问题全部汇总出来。
测试中的不足,由于没有参与进行功能测试,只是根据性能指标要求进行压力负载测试,所以对于验证数据的返回,但是没有验证返回数据的正确性。由于对于云服务器的使用,包括应用服务器和压力机,都是第一次使用,对于系统支持并发用户的数量提前没有估计,所以对于为达到TPS和并发用户数,有一个试探性的过程,消耗了时间。感觉基于云的服务与物理的服务器在性能上还是会存在较大差距。
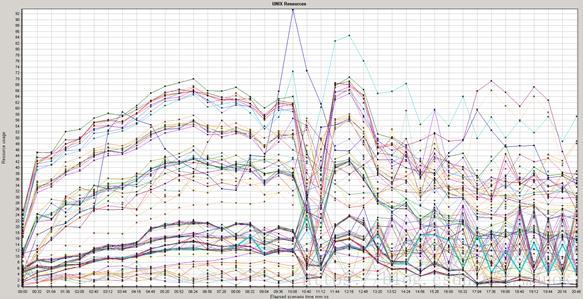
下面贴几张监控得到的图,以供了解。
2000并发时,TPS图,截取持续压力期间的图形
2000用户并发时,各应用服务器上的资源监控
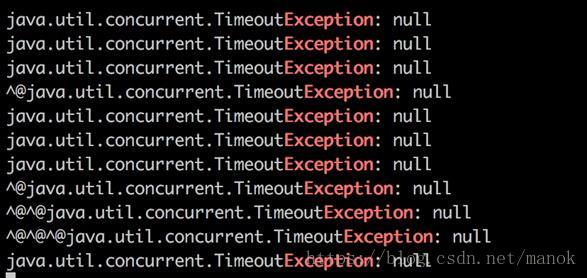
1600和2000个并发用户时,出现的并发超时日志截图:
(完)