YOLOv3论文解析: An Incremental Improvement

先说一些题外话:作者真的6,骨骼清奇的写了一个随笔式的论文,比如开头就写:
有时,你一整年全在敷衍了事而不自知。比如今年我就没做太多研究,在推特上挥霍光阴,置 GANs 于不顾。凭着上年余留的一点动力,我成功对 YOLO 做了一些升级。但实话讲,没什么超有趣的东西,只不过是些小修小补。同时我对其他人的研究也尽了少许绵薄之力。
于是就有了今天的这篇论文。我们有一个最终截稿日期,需要随机引用 YOLO 的一些更新,但是没有资源。因此请留意技术报告。
然后他在这个论文的一个插图下面这样写到:
![]()
![]()
意思是:你能引用自己的论文吗,猜猜谁会这样做?这个家伙会!然后转到了参考文献14,结果点击超链接蹦到第14个参考文献,发现正是本论文的:(在本论文中引用本论文(笑cry!))
然后下面一段:
“还有一个更好地问题:‘我们如何使用检测器?’Facebook和Google的很多研究员也在做相关研究啊。我认为,我们至少能知道技术被应用在了有利的方面,并且不会被恶意利用并将它们卖给…等一下,你说这就是它的用途??Oh!”
还有最后写了一句,最后,不要@我(因为我终于退出了Twitte), 等等.........,真的是


Joseph Redmon 是一作,Ali Farhadi是他导师,另外,看一下Joseph Redmon自己做的简历

然后再看一下Joseph Redmon的真面目,没错,这就是他本人。
正文:
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf,
相关代码:https://github.com/pjreddie/darknet ,
实验代码:https://github.com/AlexeyAB/darknet#how-to-use
由于本论文不是太长,而且写的一些术语也比较好理解,所以先贴出来原文翻译,才进行解析:
Abstract
我们对YOLO进行了一些更新!我们做了一些小设计,使它的表现更好。我们还对这个新网络进行了训练。更新版的YOLO网络比上一版本稍大,但更准确。它的速度也还是很快,这点不用担心。在320 × 320下,YOLOv3以22.2 mAP在22 ms运行完成,达到与SSD一样的精确度,但速度提高了3倍。与上个版本的 0.5 IOU mAP检测指标相比,YOLOv3的性能是相当不错的。在Titan X上,它在51 ms内达到57.9 AP50,而RetinaNet达到57.5 AP50需要198 ms,性能相似,但速度提升3.8倍。
所有代码都在以下网址提供:https://pjreddie.com/yolo/ ,
1. Introduction
有时,你一整年全在敷衍了事而不自知。比如今年我就没做太多研究,在推特上挥霍光阴,置 GANs 于不顾。凭着上年余留的一点动力,我成功对 YOLO 做了一些升级。但实话讲,没什么超有趣的东西,只不过是些小修小补。同时我对其他人的研究也尽了少许绵薄之力。
于是就有了今天的这篇论文。我们有一个最终截稿日期,需要随机引用 YOLO 的一些更新,但是没有资源。因此请留意技术报告。
这篇文章接下来将介绍YOLOv3,然后我会告诉你我们是怎么做的。我还会写一下我们尝试过但失败了的操作。最后,我们将思考这一切意味着什么。
YOLOv3
关于YOLOv3:我们主要是从其他人那里获得好点子。我们还训练了一个更好的新的分类网络。本文将从头开始介绍整个系统,以便大家理解。
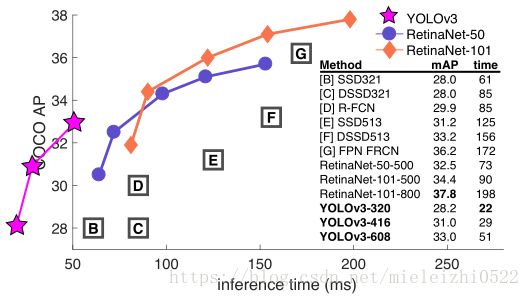
图1:这张图是从Focal Loss论文[7]拿来并修改的。 YOLOv3的运行速度明显快于其他性能相似的检测方法。运行时间来自M40或Titan X,基本上用的是相同的GPU。
边界框预测
在YOLO9000之后,我们的系统使用维度聚类(dimension cluster)作为anchor box来预测边界框[13]。网络为每个边界框预测4个坐标,tx,ty,tw,th。如果单元格从图像的左上角偏移了(cx,cy)并且先验边界框具有宽度和高度pw,ph,则预测对应以下等式:
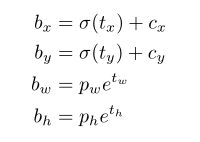
在训练期间,我们使用平方误差损失的和。如果一些坐标预测的ground truth是![]() ,梯度就是ground truth值(从ground truth box计算出来)减去预测,即:
,梯度就是ground truth值(从ground truth box计算出来)减去预测,即:![]() 。 通过翻转上面的方程可以很容易地计算出这个ground truth值。
。 通过翻转上面的方程可以很容易地计算出这个ground truth值。
YOLOv3使用逻辑回归来预测每个边界框的 objectness score。如果边界框比之前的任何其他边界框都要与ground truth的对象重叠,则该值应该为1。如果先前的边界框不是最好的,但确实与ground truth对象重叠超过某个阈值,我们会忽略该预测,如Faster R-CNN一样[15]。我们使用.5作为阈值。 但与[15]不同的是,我们的系统只为每个ground truth对象分配一个边界框。如果先前的边界框未分配给一个ground truth对象,则不会对坐标或类别预测造成损失,只会导致objectness。
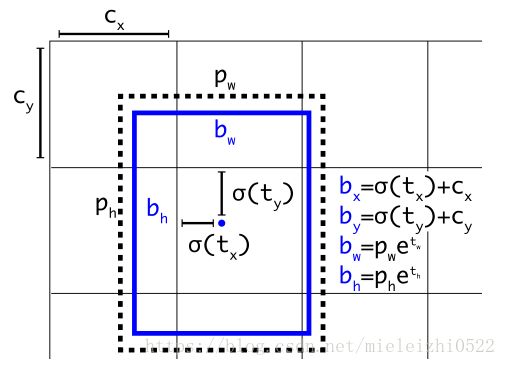
图2: 具有dimension priors和location prediction的边界框。我们预测了框的宽度和高度,作为cluster centroids的偏移量。我们使用sigmoid函数预测相对于滤波器应用位置的边界框的中心坐标。这个图是从YOLO9000论文[13]拿来的。
类别预测
每个框使用多标签分类来预测边界框可能包含的类。我们不使用softmax,因为我们发现它对于性能没有影响,而是只是使用独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失来进行类别预测。
这个公式有助于我们转向更复杂的领域,如Open Images数据集[5]。在这个数据集中有许多重叠的标签(例如,Woman和Person)。使用softmax强加了一个假设,即每个box只包含一个类别,但通常情况并非如此。多标签方法可以更好地模拟数据。
不同尺度的预测
YOLOv3可以预测3种不同尺度的box。我们的系统使用一个特征金字塔网络[6]来提取这些尺度的特征。在基本特征提取器中,我们添加了几个卷积层。其中最后一层预测三维tensor编码的边界框,objectness 和类别预测。我们在COCO[8]数据集的实验中,每个尺度预测3个box,因此tensor为N×N×[3 *(4 + 1 + 80)],4个边界框offset,1 objectness预测,以及80个类别预测。
接下来,我们从之前的2个层中取得特征图,并对其进行2倍上采样。我们还从网络获取特征图,并使用 element-wise 添加将其与我们的上采样特征进行合并。这种方法使我们能够从上采样的特征和早期特征映射的细粒度信息中获得更有意义的语义信息。然后,我们再添加几个卷积层来处理这个组合的特征图,并最终预测出一个相似的Tensor,虽然现在它的大小已经增大两倍。
我们再次执行相同的设计来对最终的scale预测box。因此,我们对第3个scale的预测将从所有之前的计算中获益,并从早期的网络中获得精细的特征。
我们仍然使用k-means聚类来确定bounding box priors。我们只是选择了9个clusters和3个scales,然后在整个scales上均匀分割clusters。在COCO数据集上,9个cluster分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90) ,(156×198),(373×326)。
特征提取器
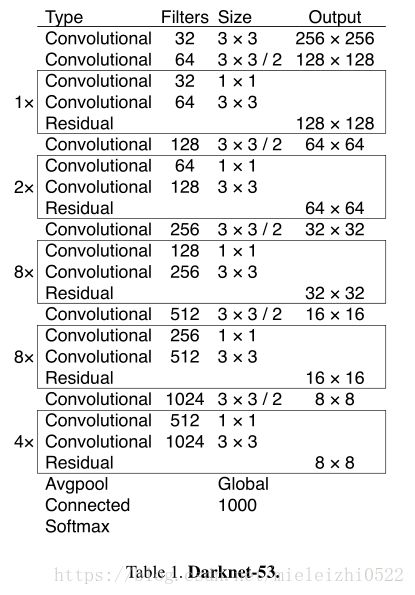
我们使用一个新的网络来执行特征提取。该新网络是用于YOLOv2,Darknet-19的网络和更新的残差网络的混合方法。我们的网络使用连续的3×3和1×1卷积层,但现在也有一些shortcut连接,并且网络的大小显著更大。它有53个卷积层,所以我们称之为...... Darknet-53!
这个新网络比Darknet19强大得多,而且比ResNet-101或ResNet-152更高效。以下是在ImageNet上的结果:
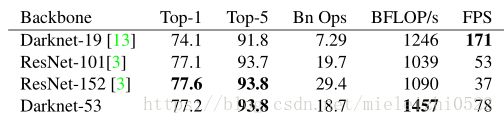
表2:网络的比较。各网络的准确性、Bn Ops、每秒浮点运算次数,以及FPS。
每个网络都使用相同的设置进行训练,并在256×256的单精度进行测试。Runtime是在Titan X上以256×256进行测量的。可以看到,Darknet-53可与最先进的分类器相媲美,但浮点运算更少,速度更快。Darknet-53比ResNet-101性能更好,而且速度快1.5倍。Darknet-53与ResNet-152具有相似的性能,速度提高2倍。
Darknet-53也可以实现每秒最高的测量浮点运算。这意味着网络结构可以更好地利用GPU,从而使其评估效率更高,速度更快。这主要是因为ResNets的层数太多,效率不高。
训练
我们仍然用完整的图像进行训练。我们使用不同scale进行训练,使用大量的数据增强,批规范化,等等。我们使用Darknet神经网络框架进行训练和测试[12]。
具体做法和结果
YOLOv3的表现非常好!请参见表3。就COCO奇怪的平均mean AP指标而言,它与SSD的变体性能相当,但速度提高了3倍。不过,它仍比RetinaNet模型差一些。
当时,以mAP的“旧”检测指标比较时,当IOU = 0.5(或表中的AP50)时,YOLOv3非常强大。它的性能几乎与RetinaNet相当,并且远高于SSD的变体。这表明YOLOv3是一个非常强大的对象检测网络。不过,随着IOU阈值增大,YOLOv3的性能下降,使边界框与物体完美对齐的效果不那么好。
过去,YOLO不擅长检测较小的物体。但是,现在我们看到了这种情况已经改变。由于新的多尺度预测方法,我们看到YOLOv3具有相对较高的APs性能。但是,它在中等尺寸和更大尺寸的物体上的表现相对较差。
当用AP50指标表示精确度和速度时(见下图),可以看到YOLOv3与其他检测系统相比具有显着的优势。也就是说,YOLOv3更快、而且更好。
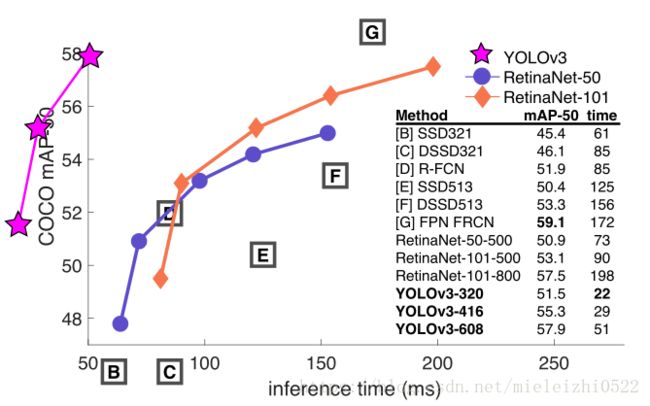
图3.再次根据[7]进行调整,这次显示的速度/准确度在mAP上以0.5 IOU度量进行折衷。 你可以看到YOLOv3是好的,因为它非常高,而且离左边很远。 你能引用你自己的论文吗? 猜猜谁会这样做,这个家伙→[14]。
一些试了没用的方法
我们在研究YOLOv3时尝试了很多方法。很多都不起作用。这些可以了解一下。
Anchor box x,y 偏移量预测。我们尝试使用常规的anchor box预测机制,可以使用线性激活将x,y的偏移预测为box的宽度或高度的倍数。我们发现这种方法降低了模型的稳定性,并且效果不佳。
线性x,y预测,而不是逻辑预测。我们尝试使用线性激活来直接预测x,y的偏移,而不是用逻辑激活。这导致了MAP的下降。
Focal loss。我们尝试使用Focal loss。这一方法使mAP降低了2点左右。YOLOv3对Focal loss解决的问题可能已经很强健,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他原因?这点还不完全确定。
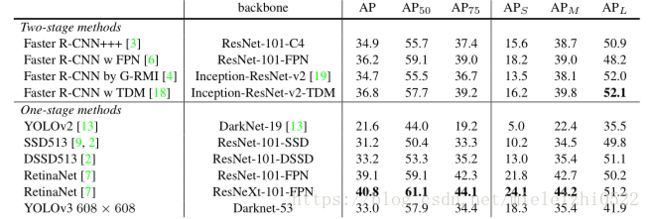
表3.我认真地从[7]中窃取了所有这些表,他们花了很长时间才从头开始制作。 好的,YOLOv3没问题。 请记住,RetinaNet处理图像的时间要长3.8倍。 YOLOv3比SSD变种好得多,而且在AP 50指标上可以与最高水平的模型相媲美。
双IOU阈值和truth分配。 Faster RCNN在训练期间使用两个IOU阈值。如果一个预测与.7的 ground truth 重叠,它就是一个正面的例子,[.3-.7]它被忽略。如果对于所有ground truth对象,它都小于.3,这就是一个负面的例子。我们尝试了类似的策略,但无法取得好的结果。
这一切意味着什么
YOLOv3是一个很好的检测器。速度很快,而且很准确。在COCO上,平均AP介于0.5和0.95 IOU时,准确度不是很好。但是,对于0.5 IOU这个指标来说,YOLOv3非常好。
为什么我们要改变指标?原始的COCO论文上只有这样一句含糊不清的句子:“一旦评估服务器完成,我们会添加不同评估指标的完整讨论”。Russakovsky等人在论文中说,人类很难区分0.3与0.5的IOU。“人们目测检查一个IOU值为0.3的边界框,并将它与IOU 0.5的区分开来,这是非常困难的事情。”[16]如果人类都很难区分这种差异,那么它就没有那么重要。
也许更值得思考的问题是:“现在我们有了这些检测器,我们拿它们来做什么?”很多做这类研究的人都在Google或Facebook工作。我想至少我们已经知道这项技术已经被掌握得很好了,绝对不会用来收集你的个人信息并将其出售给....等等,你说这正是它的目的用途?Oh.
放心,大多数研究计算机视觉的人都只是做点令人愉快的、好的事情,比如计算国家公园里斑马的数量[11],或者追踪溜进他们院子时的猫[17]。但是计算机视觉已经被用于被质疑的使用,作为研究人员,我们有责任至少思考一下我们的工作可能造成的损害,并思考如何减轻这种损害。我们非常珍惜这个世界。
最后,不要@我。(因为我终于退出了Twitter)。
分析:
YOLOv3 确实提高了不少,看图3 可以知道,速度/准确度在mAP上以0.5 IOU度量进行折衷时可以比RetinaNet还高一点,而速度快了3.8倍。网络修改的地方也是蛮大的,先从特征提取网络说起。
1.YOLOv2时用的是Darknet-19网络来提取特征,这次修改成了Darknet-53,网络又加深了不少,看一下Darknet-53的结构与性能:
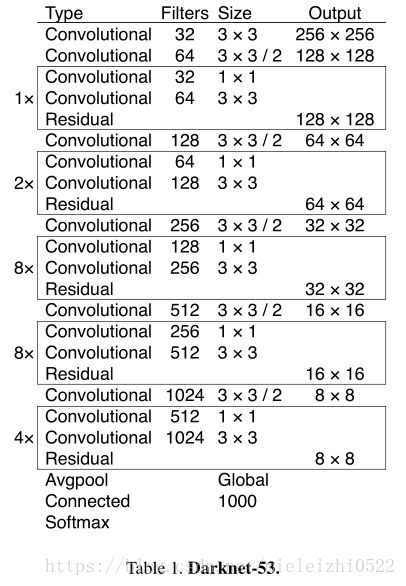
性能:
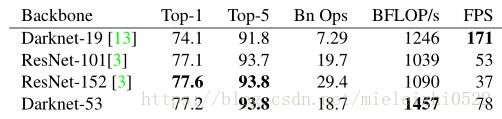
虽然运算复杂度提升了一点,但是它的浮点运算能力以及top-1,top-5表现有很大提高.速度降了一点,但是还是很高。
看一下YOLOv3网络整体:
Demo
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs
4 res 1 208 x 208 x 64 -> 208 x 208 x 64
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
8 res 5 104 x 104 x 128 -> 104 x 104 x 128
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs
11 res 8 104 x 104 x 128 -> 104 x 104 x 128
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BFLOPs
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
15 res 12 52 x 52 x 256 -> 52 x 52 x 256
16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
18 res 15 52 x 52 x 256 -> 52 x 52 x 256
19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
21 res 18 52 x 52 x 256 -> 52 x 52 x 256
22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
24 res 21 52 x 52 x 256 -> 52 x 52 x 256
25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
27 res 24 52 x 52 x 256 -> 52 x 52 x 256
28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
30 res 27 52 x 52 x 256 -> 52 x 52 x 256
31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
33 res 30 52 x 52 x 256 -> 52 x 52 x 256
34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
36 res 33 52 x 52 x 256 -> 52 x 52 x 256
37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512 1.595 BFLOPs
38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
40 res 37 26 x 26 x 512 -> 26 x 26 x 512
41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
43 res 40 26 x 26 x 512 -> 26 x 26 x 512
44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
46 res 43 26 x 26 x 512 -> 26 x 26 x 512
47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
49 res 46 26 x 26 x 512 -> 26 x 26 x 512
50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
52 res 49 26 x 26 x 512 -> 26 x 26 x 512
53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
55 res 52 26 x 26 x 512 -> 26 x 26 x 512
56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
58 res 55 26 x 26 x 512 -> 26 x 26 x 512
59 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
60 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
61 res 58 26 x 26 x 512 -> 26 x 26 x 512
62 conv 1024 3 x 3 / 2 26 x 26 x 512 -> 13 x 13 x1024 1.595 BFLOPs
63 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
64 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
65 res 62 13 x 13 x1024 -> 13 x 13 x1024
66 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
67 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
68 res 65 13 x 13 x1024 -> 13 x 13 x1024
69 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
70 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
71 res 68 13 x 13 x1024 -> 13 x 13 x1024
72 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
73 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
74 res 71 13 x 13 x1024 -> 13 x 13 x1024
75 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
76 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
77 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
78 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
79 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs
80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs
81 conv 255 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 255 0.088 BFLOPs
82 detection
83 route 79
84 conv 256 1 x 1 / 1 13 x 13 x 512 -> 13 x 13 x 256 0.044 BFLOPs
85 upsample 2x 13 x 13 x 256 -> 26 x 26 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 26 x 26 x 768 -> 26 x 26 x 256 0.266 BFLOPs
88 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
89 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
90 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
91 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs
92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs
93 conv 255 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 255 0.177 BFLOPs
94 detection
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BFLOPs
97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOPs
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
2.跨尺度的预测(Predictions Across Scales)
之前的预测bounding boxes的时候只是在特征网络的最顶层预测出5个bounding boxes,而这次完全不同,采用了类似于FPN( feature pyramid networks)的结构,我叫它特征金字塔网络,这个是什么东西呢?
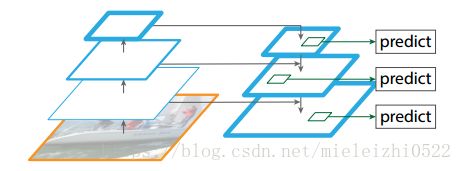
简单来说就像上面这样,FPN论文中是这样解释的:
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
如果你还不明白,那我就解释一下上面的图,你看看上面的图,自低向上很好理解,我解释一下自顶向下的过程,这个过程采用上采样(upsampling,会使特征图变大)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。融合之前,那个自低向上的图会用1*1去conv,目的是减少该特征图的卷积核个数(如下图),在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。预测是在每一融合层后独立进行,看看上面的小方框就明白了。可以对照YOLOv3的网络结构去理解。
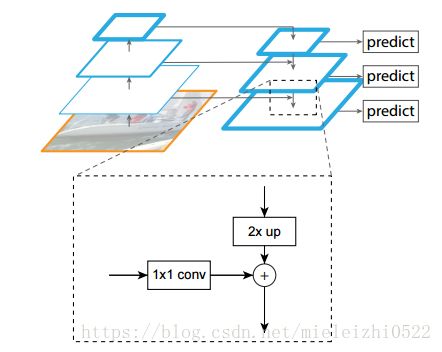
YOLOv3网络在三个不同尺寸特征图下每个特征图预测出3个boxes,而此时anchor box依然用聚类的方法得到了9个anchor box(这一段不明白的可以看我的上一篇文章),分别将9个anchor box平分给3个不同尺度的boxes。这样就得到了N ×N ×[3∗(4+1+80)] ,N为格子大小,3为每个格子得到的边界框数量, 4是边界框坐标数量,1是目标预测值,80是类别数量。
这种方法使我们能够从上采样的特征和早期特征映射的细粒度信息中获得更有意义的语义信息。换句话说,就是对小目标提取的更精准了。
3.类别预测
为了实现多标签分类,模型不再使用softmax函数作为最终的分类器,而是使用logistic作为分类器,使用 binary cross-entropy作为损失函数。
yolov3对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bounding box与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1.如果overlap没有达到一个阈值(yolov3中这里设定的阈值是0.5),那么这个预测的bounding box将会被忽略,也就是会显示成没有损失值。
YOLOv3在[email protected]@0.5及小目标APSAPS上具有不错的结果,但随着IOU的增大,性能下降,说明YOLOv3不能很好地与ground truth切合.
用YOLOv3训练数据的时候打印出的参数的意思:
Region 82- index of current [yolo]-layer (in the defaultyolov3.cfgthere are 3 yolo layers: 82, 94, 106)Avg IOU- is average intersect of union between Detected objects and Ground truth from label-txt-fileClass:- is average of the probabilities of correctly classified objectsObj:- is average of the objectnessT0(probabilities that there is an object in this cell).5R:- is average true positives with (IoU > 0.5).75R:- is average true positives with (IoU > 0.75)
Conclusion: So if the best anchor isn't suitable for this [yolo]-layer, then count of Ground truth labels which suitable for this [yolo]-layer is equal to zero (count=0), then will be divide by zero
Avg IOU=/count = /0 = nanClass=/class_count = /0 = nanObj=/count = /0 = nan
But this indicator calculated in any cases:
No Obj:- is average of the probabilities of all objects (both correctly and not correctly classified)
具体请参考https://timebutt.github.io/static/understanding-yolov2-training-output/
谢谢大家,我的表演结束
参考文献:
1.https://zhuanlan.zhihu.com/p/35074244 ,
2.http://www.sohu.com/a/226481716_473283,
3,https://blog.csdn.net/u014380165/article/details/72890275,
4,https://www.cnblogs.com/makefile/p/YOLOv3.html