【智能驾驶】基于计算机视觉的自动驾驶算法研究综述
近年来,随着人工智能技术的迅速发展,传统汽车行业与信息技术结合,在汽车自动驾驶技术方面的研究取得了长足进步,业内很多大公司都在此领域投入巨资进行研发,如国外的谷歌、丰田,国内的百度、比亚迪等公司都推出了自动驾驶汽车,且实验结果令人满意:
谷歌的自动驾驶汽车已经安全行驶超过 14 万英里;
丰田则宣布旗下自动驾驶系统将于 2020 正式量产;
百度在 2015 年底宣布,其自动驾驶汽车计划三年商用五年量产,比亚迪已与百度深化合作,共同研发无人驾驶汽车。
可以预见,在不远的将来,随着技术不断发展完善,自动驾驶技术将进入实用阶段,普及到千家万户,人们可以自由出行而无需担心人为驾驶事故,如无证驾驶、超速、疲劳驾驶、酒驾等人为引起的交通事故。因此,自动驾驶技术有着广阔的应用前景。
1 自动驾驶技术
自动驾驶技术分为基于传统特征和基于深度学习驾驶技术。
在现有的基于传统特征的自动驾驶中,目标识别是核心任务之一,其包括道路及道路边沿识别、车道线检测、车辆识别、车辆类型识别、非机动车识别、行人识别、交通标志识别、障碍物识别与避让等等。目标识别系统利用计算机视觉观测交通环境,从实时视频信号中自动识别出目标,为实时自动驾驶,如启动、停止、转向、加速和减速等操作提供判别依据。
由于实际路况极度复杂,基于传统目标检测的辅助驾驶技术性能难以得到大幅提升,现有的自动驾驶技术,一般依赖于先进的雷达系统来弥补,显著增加了系统实施的成本。随着技术的发展,采用卷积神经网(Convolutional Neural Networks,CNN)可以直接学习和感知路面和道路上的车辆,经过一段时间正确驾驶过程,便能学习和感知实际道路情况下的相关驾驶知能,无需再通过感知具体的路况和各种目标,大幅度提升了辅助驾驶算法的性能。
2 基于传统特征的自动驾驶技术
自动驾驶技术中传统的特征指的是人工提取的特征,如 HOG(梯度直方图)特征、SIFF(尺度不变特征变换)特征和 CSS(颜色自相似)等特征。
目前,主流自动驾驶技术都基于视频分析。交通场景下捕捉到的视频序列中包含各种不同视频目标,如行人、汽车、路面、障碍物、背景中的各种物体等,需要在测试图像中标识出感兴趣类别的目标对象,用来提供给车辆控制系统作为决策依据。
特征的检测与表示是关键步骤,涉及到如何编码描述目标图像信息的问题,比较理想的特征表示方法要能适应各种干扰因素的影响,比如尺度、外观、遮挡、复杂背景等情况。
2.1 道路与车道识别
道路与车道识别是自动驾驶技术的基础内容,如 Caltech lane detector中论述。常见的道路的识别算法基于图像特征进行计算,其分析图像中表示车道线或道路边界等的灰度,颜色,纹理等特征,通过神经网络、支持向量机、聚类分析和区域生长等方法便可以分割出路面区域。这类方法对道路曲率的变化有很好的鲁棒性。
最近基于条件随机场的道路检测方法取得了重要的进展。由于道路及边沿的种类繁多,纷杂的车辆以及路边杂物的遮挡,树木以及建筑物的阴影干扰等,使得最基本的道路检测存在需要进一步提升的空间。
2.2 车辆检测技术
车辆检测技术为自动驾驶领域研究的热点之一。前向车辆碰撞预警系统是一种有效降低主动事故发生率的技术,其广泛采用车辆定位的方法实现,可以利用车辆自身的图像特征,如阴影、对称性、边缘等,例如常用的底部阴影以及车辆的两个纵向边缘构成的 U 型特征等,快速定位车辆感兴趣的区域,再利用多目标跟踪算法对检测的车辆进行跟踪。
2.3 行人检测及防碰撞系统
以「行人保护」为目的的行人检测及防碰撞系统也成为自动驾驶领域的研究热点。目前统计学习方法在行人检测中应用最为广泛,特征提取和分类定位是基于统计学习方法的两个关键问题。
基于统计学习的行人检测主要包含基于生成式模型(局部)的检测方法和基于特征分类(整体)的检测算法:
基于生成式模型的检测方法通常采用局部特征或者肢体模型来描述局部属性,结合局部特征的空间结构特性或分布模型进行分类。
基于特征分类的检测方法目的是找到一种能够很好地描述行人特征的方法。通过提取行人的灰度、边缘、纹理、颜色等信息,根据大量的样本构建行人检测分类器,从样本集中学习人体的不同变化,把视频图像中的行人目标从背景中分割出来并精确定位。
2005 年 Dalal 提出梯度直方图(Histogram of Oriented Gradient,HOG)是一个最基本的特征,具有非常强的鲁棒性,其他很多行人检测的算法都是在使用 HOG 的基础上,加上其它特征,如尺度不变特征转换(Scale-invariant Feature Transform,SIFT)、局部二值模式(Local Binary Pattern,LBP)、颜色自相似(Color Self—Similarity,CSS)、多通道等等。
Cheng 等人观察到物体都有闭合边缘,基于 HOG 特征提出了一种二进制归一化梯度特征(BING)来预测显著性窗口的方法,该方法运行速度非常快,可以达到 300 fps。赵勇等在 HOG 的基础上提出了一个具有较好的尺度不变特征 eHOG,将 HOG 中梯度直方图中每个 bin 的特征重构成一个位平面,再计算其 HOG 特征。实验表明,在计算量没有大幅度增加的情况下,正确率比原 HOG 高 3 ~ 6 个百分点。HOG 特征存在一个问题,即整个 HOG 特征被拉长成一个矢量,弱化了原来在二维平面局部空间的梯度特征之间的局部关联特性。
张永军等人提出的 I-HOG采用多尺度的特征提取算法和构建梯度直方图之间的关联,增强了行人边缘信息在二维平面空间的局部关联, I-HOG 特征相较于原 HOG 特征较大幅度的提高了检测率。SIFT 是一种检测局部特征的算法,该算法通过求一幅图中的特征点及其有关尺度和方向的描述得到特征并进行图像特征点匹配,用于检索或者标准图库类别的识别时,其不仅具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角也能够得到非常好的检测效果。
3 基于深度学习的自动驾驶技术
基于视频分析的目标检测与识别技术经历了从传统特征,如:HOG、SIFT、Bag of visual words和 Fisher 核矢量到深度学习的过渡过程。
HOG 得到的描述保持图像的几何和光学转化不变性。Fisher 核矢量能统一各类特征的维度、压缩时精度损失很小等,这些传统直观的特征,在目前阶段取得了很好的使用效果。但由于目标的种类繁多,变化较大,以及视角的变化等等,使得传统基于特征的目标检测遇到了很难超越的瓶颈。
近年来,深度学习的兴起,使得大量多类多状态下目标检测与识别的性能可以大幅度提升到拟人水平,甚至在许多方面超越人类。深度学习特征为从大量训练数据中自动学习到的特征,较传统特征相比,更能刻画目标的本质。
深度学习有多个常用模型框架,如自动编码器、稀疏编码、限制波尔兹曼机、深信度网络、卷积神经网络等。其中基于卷积神经网络(Convolution Neural Network,CNN)的深度学习模型是最常用的模型和研究热点之一。
20 世纪 60 年代,Hubel 和 Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了 CNN。K.Fukushima 在 1980 年提出的新识别机是 CNN 的第一个实现网络。随后,目标检测通过扫描窗来学习并进行检测,大大提高了多类检测目标识别的效率。最具有代表性的是深度学习鼻祖 Hinton 的工作 ,作者训练深度神经网络来对 LSVRC-2010 和 LSVRC-2012 的 120 万张图像进行 1000 种以上的分类,获得当时最高的检测率。这种基于扫描窗的方法主要缺点是:扫描窗的大小和位置组合太多,导致计算量过大而难以实现。
CNN 思路近年来经过不断改进,其精确度和计算效率得到极大提升。2014 年 Girshick 等人提出了 R-CNNL ,其思想为将每个图片分为约 2000 个区域输入 CNN 训练,从预选框中通过 CNN 提取出固定长度的特征,最后通过特定类别的支持向量机(SVM)来分类。由于需将每一个候选区域分别送人到 Alexnet 中进行检测,导致检测速度很慢,因此何觊名等人提出SPPnet 。SPPnet 改变以往使用剪裁一幅图片使其尺寸满足 Alexnet 输入要求,而是使用任意尺寸图片作为输入。
Fast-RCNN在 SPPnet 的基础上,使用显著性检测方法在原始图像上提取出预选区域,并将每一个区域坐标映射到特定图上,在进行目标检测时,使用 ROI 池化层选取映射的坐标区域,部分卷积图像送人分类器,无需对每一个预选区进行卷积运算,大大提高了检测速度。
2015 年 Ren 等提出 Faster-RCNN ,在之前的基础上使用一个 RPN 网络,使用卷积运算一次得到卷积特征图像,Faster-RCNN 是对 Fast-RCNN 的进一步加速。在 2015 年 12 月的 ICCV 国际会议上,邹文斌博士在 R-CNN 的基础上,提出了基于 RCNN 的多层次结构显著性目标检测方法 ,在 MSRA-B ,PASCAL-1500 和 SOD 三个数据集上的实验表明,其检测率达到当时业界最高水平。在该会议上,Kontschieder 旧引等提出了在 CNN 各层输出的特征基础上,采用随机森林,在公开的数据集 MNIST 和Imagenet上,获得了较高的检测率。
CNN 和多通道处理结合的方法在图像识别上也有不错的效果:
2011 年 Pierre Sermanet等人提出多尺度 CNN 算法,将原始图像和其子取样的卷积结果通过线性分类器分类,其 GTSRB 数据集上精确度达到 98.97%。
2012 年 Dan Ciresan等人提出使用多通道深度神经网络的方法识别交通信号。该方法将训练图片同时输入 N 个深度神经网同时训练,进行预测时,计算输入图像的 N 个深度神经网预测结果的平均值作为最终结果,其预测结果准确率达到 99.46%,超过了人工识别精度。
2014 年 Karen Simonyan钊等人将连续视频分为空间流和时间流,使用不同的 CNN 处理同一段视频的物体特征和行为特征,并将二者结合进行行为判别,也极大地提升了识别的精确度。
在辅助驾驶和自动驾驶中,需要识别和估计的目标繁多,包括前方机动车、非机动车、行人、道路标识、道路本身、车道线等等,导致基于目标监测与识别的学习算法变得十分复杂。在自动驾驶与机器人导航中,另一种方法直接从视频图像中学习前进方向的角度来寻找路径和绕开障碍物,以及Yann Lecun 的工作 ,即通过端到端学习,以实现非道路上的障碍物避让,使用 6 层的 CNN 学习人的驾驶行为,可以在穿越视野内区域的同时学习低层和高层特征,消除人工的校准、矫正、参数调整等等,该系统主要的优点是对各种不同环境下的非道路环境有非常好的鲁棒性。
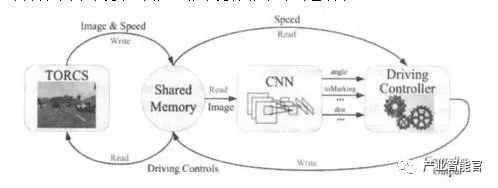
图 1 深度驾驶算法架构
以上工作均为通过深度学习直接将图像映射到行驶的角度下进行的。在这一思想的影响下,在 ICCV 2015 上,普林斯顿大学提出了深度驾驶算法,其算法架构如图 1 所示,通过深度神经网络直接感知驾驶操控(driving affordance),不仅大大简化了算法的复杂度,而且大大提高了自动驾驶的鲁棒性和智能化水平,是自动驾驶技术上的一个重大突破。
深度驾驶的技术,通过采用 CNN 来直接学习和感知一段时间正确驾驶过程以后,就能学习和感知到实际道路情况下的相关驾驶智能,无需通过感知具体的路况和各种目标,大幅度提升了辅助驾驶算法的性能。
4 总结与展望
自动驾驶技术是未来汽车智能化的研究热点之一。从综述的文章中可以得出,基于传统目标检测最有效 HOG 特征、SIFT 特征、CSS 等特征的自动驾驶技术已经取得了不错成绩。
由于实际路况极度复杂,基于传统目标检测的辅助驾驶技术性能难以得到大幅度提升,现有的自动驾驶技术,一般依赖于先进的雷达系统,显著增加了系统实施的成本。深度驾驶技术能同时感知道路和道路上的各类目标,为自动驾驶系统提供驾驶逻辑支持,是未来自动驾驶技术研究的方向之一。
在具体的辅助驾驶算法中,如果对路况和目标缺乏整体感知,则很难达到实用化和商用化水平。吸取传统自动驾驶技术中的精华,借鉴深度学习研究的最新成果,整合传统特征和深度学习特征,以提供更多信息,不失为一个较好的解决方法。设计自动驾驶技术的新算法,进一步提升深度驾驶的拟人化和实用化水平,是一条值得去继续探索的道路。
自动驾驶新思路:现实域到虚拟域统一的无监督方法
专知
【导读】近日,针对无人驾驶中端到端模型缺乏训练数据以及训练数据噪声大、模型难解释等问题,来自卡内基梅隆大学、Petuum公司的Eric P. Xing等学者发表论文提出基于无监督现实到虚拟域统一的端到端自动驾驶方法。该方法具有如下优势:1)将从不同源分布中收集的驾驶数据映射到一个统一的域; 2)充分利用标注的虚拟数据,这些数据是可以自由获取的; 3)学习除了一个可解释的、标注的驾驶图像表示方法,其可以专门用于车辆指挥预测。所提出的方法在两个公路行驶数据集的大量实验表明了方法的性能优势和可解释能力。
论文:Unsupervised Real-to-Virtual Domain Unification for End-to-End Highway Driving

▌摘要
在基于视觉的自动驾驶领域中,端到端模型在性能上表现不佳并且是不可解释的,而中介感知模型(mediated perception models)需要额外的中间表示,例如分割的masks或检测边界框(bounding boxes),在进行大规模数据训练时,这些大量的标签信息的获取可能是非常昂贵的。 原始图像和现有的中间表示中可能夹杂着与车辆命令预测无关的琐碎的细节,例如,前方车辆的风格或超过了道路边界的视野。 更重要的是,如果合并从不同来源收集的数据,所有以前的工作都不能有效应对这种域转移问题,这极大地阻碍了模型的泛化能力。
在这项工作中,本文利用从驾驶模拟器收集的虚拟数据来解决上述问题,并且提出了DU-驱动,一种无监督的真实到虚拟域的统一框架,用于端到端驾驶。 它将实际驾驶数据转换为虚拟域中的规范表示,从中预测车辆控制命令。 提出的框架有几个优点:1)将从不同源分布中收集的驾驶数据映射到一个统一的域; 2)利用标注的虚拟数据,这些数据是可以自由获取的; 3)它学习除了一个可解释的、标注的驾驶图像表示方法,其可以专门用于车辆指挥预测。 两个公路行驶数据集的大量实验表明了DU驱动的性能优势和可解释能力。
▌介绍
基于视觉的自动驾驶系统是一个长期的研究问题。在已有的各种解决方案中,将单个正面摄像机图像映射到车辆控制命令的端到端驾驶模型吸引了许多研究兴趣,因为它消除了特征工程的繁琐过程。 也有许多方法尝试了利用中间表示来提高端到端模型的性能(图1)。 例如,[33]使用语义分割作为一个辅助任务来提高模型的性能,而[8]在进行驾驶决策之前,首先训练一个检测器来检测附近的车辆。 然而,随着我们向更大的规模迈进,驾驶数据的收集和中间表示的标注可能会非常昂贵。
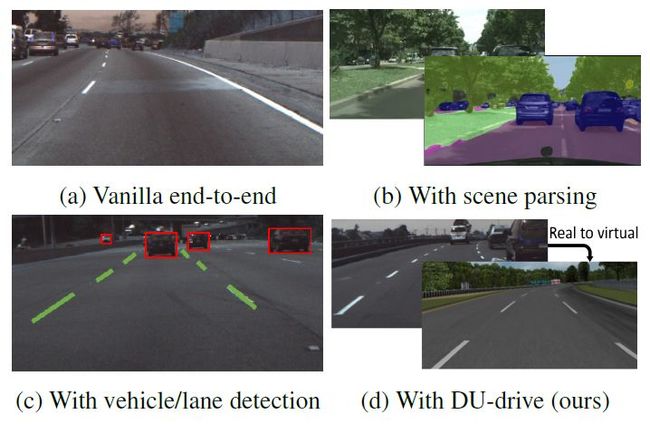
图1:各种已经提出的基于视觉的驾驶模型的方法。 标准的端到端模型(a)在性能上不可解释且不是最理想的,场景解析(b)或对象检测(c)需要昂贵的注释数据。 提出的方法(d)将不同数据集的真实图像统一到虚拟领域的规范化表示中,避免了多余的细节,提高了车辆指令预测任务的性能。
此外,由于现实场景的复杂性,驾驶场景的一般图像和中间表示中含有多余的细节。这些细节中的许多信息既不相关,也对预测任务没有帮助。例如,高速驾驶的人类驾驶者不会根据前面的汽车品牌或道路边界外的视野来改变自己的行为。理想情况下,模型应该能够通过观察人类驾驶数据来学习关键信息,但是由于深度神经网络的黑盒性质,我们难以分析模型是否学会了基于正确的信号进行预测。
文献 [6]可视化了神经网络的激活,并表明,模型不仅学习驾驶关键信息,如车道标记,同时也学到了不需要的特征,如不规则类型的车辆类别。文献 [18]提出了由因果滤波器改进的注意力map的结果,它包括相当随机的注意力blob。很难证明学习这些信息是否有助于驾驶,而且本文认为从驾驶图像中有效地提取最少的且足够的信息的能力对于提高预测任务的性能是至关重要的。
相比之下,来自于驾驶模拟器的数据自然地避免了这两个问题。 一方面,通过设置一个机器人汽车,我们可以很容易地获得用于控制信号标注的、源源不断的驾驶数据。 另一方面,我们可以控制虚拟世界的视觉外观,并通过将多余的细节保持在最低限度,来构建规范的驾驶环境。
这促使作者开发一个能够在虚拟领域有效地将真实的驾驶图像转化为规范表示的系统,从而促进车辆指挥预测任务。许多现有的工作利用了虚拟数据,通过生成对抗网络将虚拟图像转化为类似于真实的图像,同时在辅助目标的辅助下保持标注的完整。
本文的方法虽然也基于GAN,但在几个方面有所不同:首先,有别于其他方法,作者尝试将真实图像转换为虚拟域中的规范表示。通过规范表示,作者参考了像素级表示,其从背景中分离出预测任务所需的最小的足量信息。由于任何图像只能有一个规范表示,因此在生成过程中不会引入任何噪声变量。其次,本文并不直接保留标注,因为图像中确定车辆命令的确切信号是不清楚的。相反,本文提出了一种新的联合训练方案,将预测关键信息逐渐提取到生成器中,同时提高模型训练的稳定性,防止驾驶关键信息的模型崩溃。
这次工作有三个贡献:
首先,作者引入一个无监督的真实到虚拟域的统一框架,将真实的驾驶图像转换成虚拟域的规范表示,并从中预测车辆命令。
其次,作者开发了一种新的训练方案,不仅逐步将预测关键信息提取到生成器中,而且有选择地防止生成对抗网路的模型崩溃。
第三,作者给出了实验结果,证明了在虚拟域中使用统一的、规范的表示来进行端到端自动驾驶是具备优越性的。
▌模型简介:
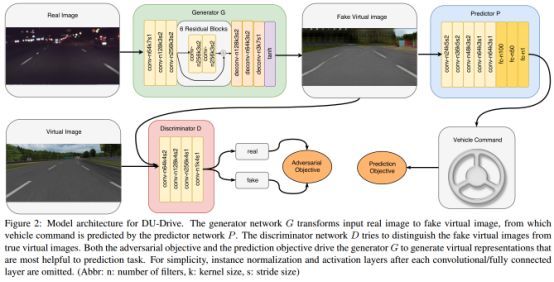
图2:DU-Drive的模型架构。 生成器网络G将输入的真实图像转换成虚拟图像,由预测器网络P预测车辆指令。 判别器网络D试图将假虚像与真虚像区分开来。 对抗目标和预测目标都驱使生成者G生成最有助于预测任务的虚拟表示。 为了简单起见,省略了每个卷积/全连接层之后的实例标准化和激活层。 (缩写:n:filters数量,k:kernel大小,s:stride大小)
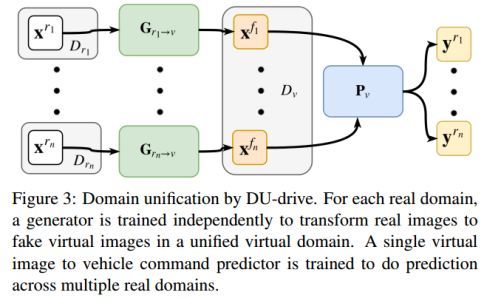
图3:DU-Drive的域统一框架。 对于每一个真实域,训练一个独立的生成器,以将真实图像转换成虚拟域中的虚拟图像。 训练单个虚拟图像进行车辆指令预测,并在多个真实域上进行预测。
▌实验结果
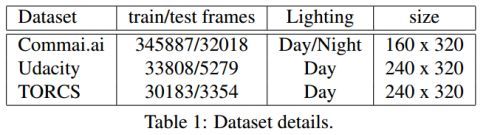
表1:数据集的细节

图4:我们的工作使用的样本数据。从上到下依次为:从TORCS模拟器捕获的虚拟数据,来自于comma.ai的真实驾驶数据,来自Udacity挑战的真实驾驶数据。

图5:DU-Drive的图像生成结果,考虑了那些对驾驶行为不重要的信息,例如昼/夜照明情况。而视野超出道路边界。有趣的是,车辆也从场景中移除,但是考虑到我们在实验中只预测转向角度,所以这实际上是合理的。另一方面,驾驶车道这样的关键信息得到很好地保存。

图6:在TORCS模拟器中的6个轨道的形状,并从中收集虚拟数据。

图7:条件GAN的图像生成结果。在背景和前景、车道标记发生的模型崩溃不予保存。

图8:CycleGAN的图像生成结果。第一行:真实的源图像和生成的虚拟图像。下一行:虚拟源图像和生成的假的真实图像。
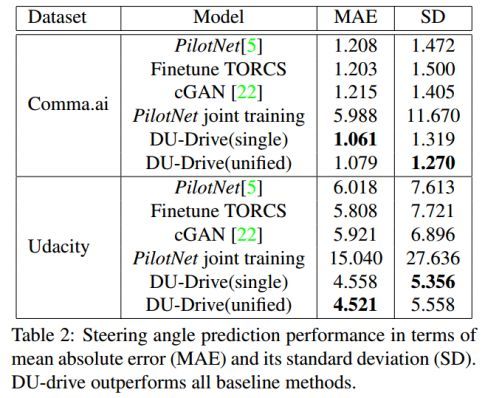
表2:转向角度预测性能。平均绝对误差(MAE)及其标准差(SD)。其中,DU-drive优于所有baseline方法。
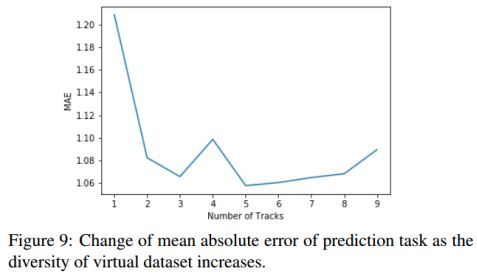
图9:随着虚拟数据集的多样性增加,预测任务的绝对误差平均值的变化。
▌结论
我们针对公路驾驶提出了一种无监督的真实到虚拟域的统一模型,或称为DU-drive,它使用条件生成对抗网络来将真实域中的驾驶图像变换到虚拟领域中的规范表示,并从中预测车辆控制命令。 在存在多个真实数据集的情况下,可以为每个真实域独立地训练生成器(从真实到虚拟域的生成器),并且可以用来自多个真实域的数据来训练全局预测器。 定性实验结果表明,该模型能够将实际图像有效地转换到虚拟域,并且只保留足够的最小信息量,结果证明了这种规范表示能消除域偏移,提高控制指令预测任务的性能。
参考链接:
https://arxiv.org/abs/1801.03458

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能金融”、“智能零售”、“智能驾驶”、“智能城市”;新模式:“财富空间”、“工业互联网”、“数据科学家”、“赛博物理系统CPS”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:[email protected]