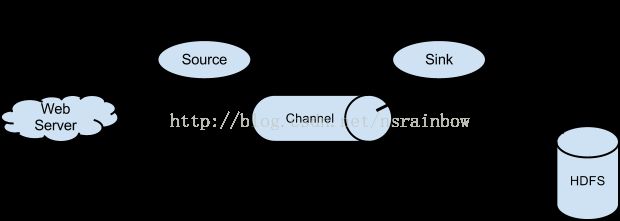
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
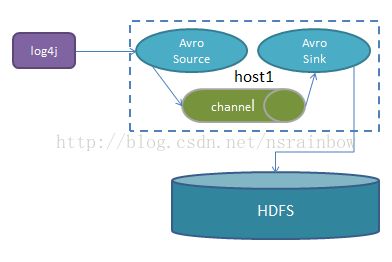
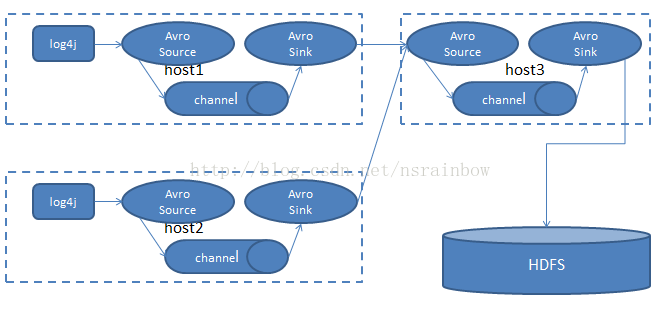
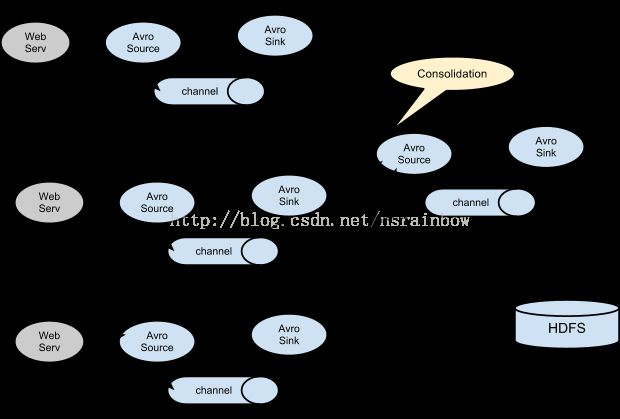
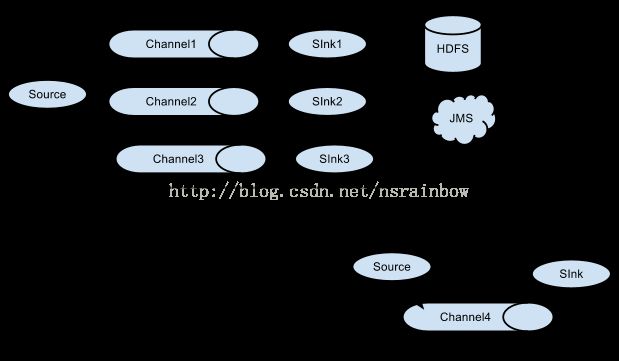
# source, channel, sink definition
agent.channels = mem-channel
agent.sources = log4j-avro-source
agent.sinks = hdfs-sink
# Channel
# Define a memory channel called mem-channel on agent
agent.channels.mem-channel.type = memory
# Source
# Define an Avro source called log4j-avro-channel on agent and tell it
# to bind to host1:12345. Connect it to channel mem-channel.
agent.sources.log4j-avro-source.type = avro
agent.sources.log4j-avro-source.bind = 192.168.1.126
agent.sources.log4j-avro-source.port = 12345
agent.sources.log4j-avro-source.channels = mem-channel
# Sink
# Define a logger sink that simply logs all events it receives
# and connect it to the other end of the same channel.
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = hdfs://mycluster/flume/events/
agent.sinks.hdfs-sink.channel = mem-channel
package org.crazycake.play_flume;
import org.apache.log4j.Logger;
public class FlumeLog {
public static void main(String[] args)
{
Logger logger = Logger.getLogger(App.class);
logger.info("hello world");
logger.info("My name is alex");
logger.info("How are you?");
}
}
同生成的做法一样,添加和移除类成员只要去修改fields和methods中的元素即可。这里我们拿一个简单的类做例子,下面这个Task类,我们来移除isNeedRemove方法,并且添加一个int 类型的addedField属性。
package asm.core;
/**
* Created by yunshen.ljy on 2015/6/
交换两个数字的方法有以下三种 ,其中第一种最常用
/*
输出最小的一个数
*/
public class jiaohuan1 {
public static void main(String[] args) {
int a =4;
int b = 3;
if(a<b){
// 第一种交换方式
int tmep =
1. Kafka提供了两种Consumer API
High Level Consumer API
Low Level Consumer API(Kafka诡异的称之为Simple Consumer API,实际上非常复杂)
在选用哪种Consumer API时,首先要弄清楚这两种API的工作原理,能做什么不能做什么,能做的话怎么做的以及用的时候,有哪些可能的问题
CompositeChannelBuffer体现了Netty的“Transparent Zero Copy”
查看API(
http://docs.jboss.org/netty/3.2/api/org/jboss/netty/buffer/package-summary.html#package_description)
可以看到,所谓“Transparent Zero Copy”是通
// this need android:minSdkVersion="11"
getActionBar().setDisplayHomeAsUpEnabled(true);
@Override
public boolean onOptionsItemSelected(MenuItem item) {
$(document).ready(function () {
var request = {
QueryString :
function (val) {
var uri = window.location.search;
var re = new RegExp("" + val + "=([^&?]*)", &
ArticleSelect类在命名空间HoverTree.Model中可以认为是文章查询条件类,用于存放查询文章时的条件,例如HvtId就是文章的id。HvtIsShow就是文章的显示属性,当为-1是,该条件不产生作用,当为0时,查询不公开显示的文章,当为1时查询公开显示的文章。HvtIsHome则为是否在首页显示。HoverTree系统源码完全开放,开发环境为Visual Studio 2013
1. php 类
I found this class looking for something else actually but I remembered I needed some while ago something similar and I never found one. I'm sure it will help a lot of developers who try to
Design pattern for graph processing.
Since we consider a large number of graph-processing algorithms, our initial design goal is to decouple our implementations from the graph representation