CRF模型在NLP中的运用
一、 CRF模型
CRF(Conditional Random Field) 条件随机场是近几年自然语言处理领域常用的算法之一,基于统计学的模型。CRF本质上是隐含变量的马尔科夫链+可观测状态到隐含变量的条件概率。CRF是判别模型,其原理如下:

如何用简单易懂的例子解释隐马尔可夫模型?https://www.zhihu.com/question/20962240
CRF与HMM(隐马尔可夫模型)的区别:http://blog.csdn.net/heavendai/article/details/7228621
二、 CRF运用场景
(1) 基于字标注的分词
(2) 基于词或字标注的主题提取(人名、地名、机构名、品牌、商品等实体识别)
三、 CRF使用过程
在词料方面,业界的研究和评测往往基于98年人民日报或微软亚洲研究院的语料,两者都进行了比较权威的分词和词性标注。目前封闭测试最好的结果是4-tag+CFR标注分词,在北大语料库上可以在准确率,召回率以及F值上达到92%以上的效果,在微软语料库上可以到达96%以上的效果。下文中代码和文本举例基于98年人民日报实验。
分词过程概述:
CRF是基于序列标注的分词。其中标注标签(tag)一般分两种:4-tag(BMES)和6-tag(BB2B3MES)。下面用4-tag(B:begin;M:middle;E:end;S:single)举例说明分词过程。

本文采用CRF++的工具包,使用方法参照以下:
CRF++工具包使用介绍:
https://wenku.baidu.com/view/547dea89f7ec4afe05a1df7a.html
下面实现其过程:
(1) 准备训练样本
CRF所需的训练样本格式,每行【一个字+\t+tag】,不同句子间用空行隔开,举例如下(文件名:pku_training.txt):
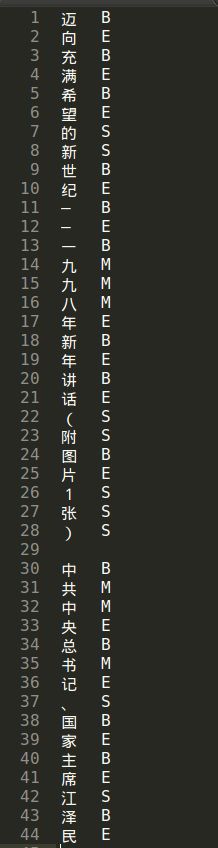
由分词文件生成样本数据:
#-*-coding:utf-8-*-
#4-tags for character tagging: B(Begin),E(End),M(Middle),S(Single)
import codecs
import sys
file_orig_path = r'/home/songhongwei/jd/xstore/word/crf/icwb2-data/training/pku_word.txt
file_train_path = r'/home/songhongwei/jd/xstore/word/crf/crf_text/ pku_training.txt '
def character_tagging(input_file, output_file):
input_data = codecs.open(input_file, 'r', 'utf-8')
output_data = codecs.open(output_file, 'w', 'utf-8')
for line in input_data.readlines():
word_list = line.strip().split()
for word in word_list:
if len(word) == 1:
output_data.write(word + "\tS\n")
else:
output_data.write(word[0] + "\tB\n")
for w in word[1:len(word)-1]:
output_data.write(w + "\tM\n")
output_data.write(word[len(word)-1] + "\tE\n")
output_data.write("\n")
input_data.close()
output_data.close()
print('生成训练文件完成!')
if __name__ == '__main__':
character_tagging(file_orig_path, file_train_path)(2) 创建特征模板(文件名:template)
# Unigram template 模板
# unigram-features一元特征
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
# bigram-features二元特征
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# trigram-featuress三元特征
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
# Bigram template 模板
B T**:%x[#,#]中的T表示模板类型,两个”#”分别表示相对的行偏移与列偏移。每行就是一个函数模板。
一共有两种模板:
第一种是Unigram template:第一个字符是U,这是用于描述unigram feature的模板。每一行%x[#,#]生成一个CRFs中的点(state)函数: f(s, o), 其中s为t时刻的的标签(output),o为t时刻的上下文.如CRF++说明文件中的示例函数:
func1 = if (output = B and feature=”U02:那”) return 1 else return 0
它是由U02:%x[0,0]在输入文件的第一行生成的点函数.将输入文件的第一行”代入”到函数中,函数返回1,同时,如果输入文件的某一行在第1列也是“那”,并且它的output(第2列)同样也为B,那么这个函数在这一行也返回1。
第二种是Bigram template:第一个字符是B,每一行%x[#,#]生成一个CRFs中的边(Edge)函数:f(s’, s, o), 其中s’为t – 1时刻的标签.也就是说,Bigram类型与Unigram大致机同,只是还要考虑到t – 1时刻的标签.如果只写一个B的话,默认生成f(s’, s),这意味着前一个output token和current token将组合成bigram features。
说明:
如果L是输出的类型数,N是定义的unique特征模板个数。只使用Unigram template,一个模型生成的特征函数总数为L*N;只使用Bigram template相当于使用前一个output token和current token组合成bigram features;同时使用二者将产生特征函数总数为L*L*N。
Ps:
对crf++的template的理解:http://www.cnblogs.com/littleseven/p/6481315.html
(3) 根据CRF训练模型,获得model文件
- 训练样本格式:
crf_learn -f 3 -c 4.0 模板文件 训练样本文件 输出model文件例如:
crf_learn -f 3 -c 4.0 template pku_training.txt model(只输出一个二进制的model文件)
或crf_learn -f 3 -c 4.0 template pku_training.txt model –t(输出一个二进制的model文件和一个文本类型的model.txt文件,一般用于调试分析)
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。Ps:全部可选参数如下:
-f, –freq=INT使用属性的出现次数不少于INT(默认为1)
-m, –maxiter=INT设置INT为LBFGS的最大迭代次数 (默认10k)
-c, –cost=FLOAT 设置FLOAT为代价参数,过大会过度拟合 (默认1.0)
-e, –eta=FLOAT设置终止标准FLOAT(默认0.0001)
-C, –convert将文本模式转为二进制模式
-t, –textmodel为调试建立文本模型文件
-a, –algorithm=(CRF|MIRA)
选择训练算法,默认为CRF-L2
-p, –thread=INT线程数(默认1),利用多个CPU减少训练时间
-H, –shrinking-size=INT
设置INT为最适宜的跌代变量次数 (默认20)
-v, –version显示版本号并退出
-h, –help显示帮助并退出

输出说明:
iter:迭代次数。当迭代次数达到maxiter时,迭代终止
terr:标记错误率
serr:句子错误率
obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成
diff:与上一个对象值之间的相对差。当此值低于eta时,训练完成
Ps:
CRF模型格式:http://www.hankcs.com/nlp/the-crf-model-format-description.html
- 测试样本格式:
crf_test -m 模板文件 测试样本文件 > 重定向结果文件例如:
crf_test -m model pku_testing.txt > pku_result.txt
说明:
预测结果是在每行后面添加一列显示预测标签,如下图,第一列为文本,第二列为标注tag,第三列为预测tag。

(4) 待分词文本预测
当一个新的文本用于预测时候,可以通过两种方式:
(1) 调用工具库一行一行的预测,可以参考如下代码;
#-*-coding:utf-8-*-
#CRF Segmenter based character tagging:
# 4-tags for character tagging: B(Begin), E(End), M(Middle), S(Single)
import codecs
import sys
import CRFPP
file_orig_path = r'/home/songhongwei/jd/xstore/word/text/pku_testing.txt '
file_test_path = r'/home/songhongwei/jd/xstore/word/crf/crf_text/pku_result.txt '
file_model_path = r'/home/songhongwei/jd/xstore/word/crf/crf_text/crf_model'
def crf_segmenter(input_file, output_file, tagger):
input_data = codecs.open(input_file, 'r', 'utf-8')
output_data = codecs.open(output_file, 'w', 'utf-8')
for line in input_data.readlines():
tagger.clear()
for word in line.strip():
word = word.strip()
if word:
tagger.add((word + "\to\tB").encode('utf-8'))
tagger.parse()
size = tagger.size()
xsize = tagger.xsize()
for i in range(0, size):
for j in range(0, xsize):
char = tagger.x(i, j).decode('utf-8')
tag = tagger.y2(i)
if tag == 'B':
output_data.write(' ' + char)
elif tag == 'M':
output_data.write(char)
elif tag == 'E':
output_data.write(char + ' ')
else:
output_data.write(' ' + char + ' ')
output_data.write('\n')
input_data.close()
output_data.close()
if __name__ == '__main__':
crf_model = file_model_path
input_file = file_orig_path
output_file = file_test_path
tagger = CRFPP.Tagger("-m " + crf_model)
crf_segmenter(input_file, output_file, tagger)
(2) 借用crf_test批量预测,即把句子转换为每行一个字,不同句子用空行隔开(类似于训练样本,只是每行只有第一列即可),调用crf_test命令后给出预测tag后,再调用程序处理即可。
注:熟悉了CRF整个运行原理,剩下的工作就是:准备样本数据-调用命令训练模型-预测文本tag-生成分词文本。其中准备样本数据和生成分词文本只需生成的正确的格式即可(具体什么语言实现倒无所谓了)
四、 CRF使用总结
CRF是使用机器学习的方式,能够通过不断的迭代学习,逐渐增强其分词效果。CRF适用一些判别或提取信息的场景,而对一些“无中生有”的场景显然就不合适。明白了CRF的运行原理,那么基于词标注的信息提取的理解也就是水到渠成的事了,网站针对这方面的讲解也较多了,这里就不再讲解了。运用CRF的关键就是适合自己场景的标注样本就显得很重要了,一方面可以通过其他方法获得一些原始数据,再通过CRF的学习后,对一些错误样本纠正后放入原始样本后重新训练等方法,这段时间一直在学NLP相关的方法,对分词、主题提取、文本分类(fasttext、textgrocery等)等方向有了更深入的了解,本文是整理网上资料和自己理解并实践后的总结,如有误欢迎留言讨论谢谢!