1 MLlib概述
1.1 MLlib 介绍
◆ 是基于Spark core的机器学习库,具有Spark的优点
◆ 底层计算经过优化,比常规编码效率往往要高
◆ 实现了多种机器学习算法,可以进行模型训练及预测
1.2 Spark MLlib实现的算法
◆ 逻辑回归 朴素贝叶斯 线性回归 SVM 决策树 LDA 矩阵分解
1.3 Spark MLlib官方介绍
1.3.1 搜索官方文档
1.3.2 阅读文档 - 机器学习库(MLlib)指南
简介
MLlib是Spark的机器学习(ML)库。 其目标是使实用的机器学习可扩展且简单。 从较高的层面来说,它提供了以下工具:
- ML算法:常见的学习算法,如分类,回归,聚类和协同过滤
- 特征化:特征提取,转换,降维和选择
- 管道:用于构建,评估和调整ML管道的工具
- 持久性:保存和加载算法,模型和管道
- 实用程序:线性代数,统计,数据处理等。
公告:基于DataFrame的API是主要的API
基于MLlib RDD的API现在处于维护模式。
从Spark 2.0开始,spark.mllib包中基于RDD的API已进入维护模式。 Spark的主要机器学习API现在是spark.ml包中基于DataFrame的API
有什么影响?
- MLlib仍将支持
spark.mllib中基于RDD的API以及错误修复 - MLlib不会为基于RDD的API添加新功能
- 在Spark 2.x版本中,MLlib将为基于DataFrames的API添加功能,以实现与基于RDD的API的功能奇偶校验。
- 在达到功能奇偶校验(粗略估计Spark 2.3)之后,将弃用基于RDD的API。
- 预计基于RDD的API将在Spark 3.0中删除。
为什么MLlib会切换到基于DataFrame的API?
- DataFrames提供比RDD更加用户友好的API。 DataFrame的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
- 基于DataFrame的MLlib API跨ML算法和多种语言提供统一的API。
- DataFrames有助于实用的ML管道,特别是功能转换。有关详细信息,请参阅管道指南
什么是“Spark ML”?
“Spark ML”不是官方名称,但偶尔用于指代基于MLlib DataFrame的API。这主要是由于基于DataFrame的API使用的org.apache.spark.ml Scala包名称,以及我们最初用来强调管道概念的“Spark ML Pipelines”术语。
MLlib已被弃用吗?
不,MLlib包括基于RDD的API和基于DataFrame的API。基于RDD的API现在处于维护模式。但是,API都不被弃用,也不是MLlib
依赖关系
MLlib使用线性代数包Breeze,它依赖于netlib-java进行优化的数值处理。如果本机库1在运行时不可用,您将看到一条警告消息,而将使用纯JVM实现。
由于运行时专有二进制文件的许可问题,我们默认不包括netlib-java的本机代理。要配置netlib-java / Breeze以使用系统优化的二进制文件,请包含com.github.fommil.netlib:all:1.1.2(或使用-Pnetlib-lgpl构建Spark)作为项目的依赖项并阅读netlib-java文档为您的平台提供其他安装说明。
最受欢迎的原生BLAS,如英特尔MKL,OpenBLAS,可以在一次操作中使用多个线程,这可能与Spark的执行模型冲突。
配置这些BLAS实现以使用单个线程进行操作实际上可以提高性能(请参阅SPARK-21305)。通常最好将此与每个Spark任务配置使用的核心数相匹配,默认情况下为1,通常保留为1。
请参考以下资源,了解如何配置这些BLAS实现使用的线程数:Intel MKL和OpenBLAS。
要在Python中使用MLlib,您将需要NumPy 1.4或更高版本。
2.3中的亮点
下面的列表重点介绍了Spark 2.3版本中添加到MLlib的一些新功能和增强功能:
- 添加了内置支持将图像读入DataFrame(SPARK-21866)。
- 添加了OneHotEncoderEstimator,应该使用它来代替现有的OneHotEncoder转换器。 新的估算器支持转换多个列。
- QuantileDiscretizer和Bucketizer(SPARK-22397和SPARK-20542)也增加了多列支持
- 添加了一个新的FeatureHasher变换器(SPARK-13969)。
- 在使用TrainValidationSplit或CrossValidator(SPARK-19357)执行交叉验证时,添加了对并行评估多个模型的支持。
- 改进了对Python中自定义管道组件的支持(请参阅SPARK-21633和SPARK-21542)。
- DataFrame函数用于矢量列的描述性摘要统计(SPARK-19634)。
- Huber损失的稳健线性回归(SPARK-3181)。
打破变化
逻辑回归模型摘要的类和特征层次结构被更改为更清晰,更好地适应了多类摘要的添加。对于将LogisticRegressionTrainingSummary强制转换为BinaryLogisticRegressionTrainingSummary的用户代码,这是一个重大变化。用户应该使用model.binarySummary方法。有关更多详细信息,请参阅SPARK-17139(请注意,这是一个实验API)。这不会影响Python摘要方法,它对于多项和二进制情况仍然可以正常工作。
废弃和行为变化
弃用
- OneHotEncoder已被弃用,将在3.0中删除。它已被新的OneHotEncoderEstimator所取代(参见SPARK-13030)。请注意,OneHotEncoderEstimator将在3.0中重命名为OneHotEncoder(但OneHotEncoderEstimator将保留为别名)。
行为的变化
- SPARK-21027:OneVsRest中使用的默认并行度现在设置为1(即串行)。在2.2及更早版本中,并行度级别设置为Scala中的默认线程池大小。
- SPARK-22156:当numIterations设置为大于1时,Word2Vec的学习速率更新不正确。这将导致2.3和早期版本之间的训练结果不同。
- SPARK-21681:修复了多项Logistic回归中的边缘案例错误,当某些特征的方差为零时,导致系数不正确。
- SPARK-16957:树算法现在使用中点来分割值。这可能会改变模型训练的结果。
- SPARK-14657:修复了RFormula在没有截距的情况下生成的特征与R中的输出不一致的问题。这可能会改变此场景中模型训练的结果。
2 MLlib的数据结构
2.1 本地向量(Local vector)
具有整数类型和基于0的索引和双类型值
本地向量的基类是Vector,我们提供了两个实现:DenseVector 和 SparseVector
◆ 本地向量是存储在本地节点上的,其基本数据类型是Vector.
其有两个子集,分别是密集的与稀疏的
- 密集向量由表示其条目值的双数组支持
- 而稀疏向量由两个并行数组支持:索引和值
我们一般使用Vectors工厂类来生成
例如:
◆ Vectors.dense(1.0,2.0,3.0) 主要使用稠密的
◆ Vectors.sparse(3,(0,1),(1,2),(2,3)) 稀疏的了解即可
向量(1.00.03.0)可以密集格式表示为1.00.03.0,或以稀疏格式表示为(3,02,1.03.0),其中3是矢量的大小。
2.2 标签数据(Labeled point)
与标签/响应相关联的局部矢量,密集或稀疏
在MLlib中,用于监督学习算法。 我们使用双重存储标签,所以我们可以在回归和分类中使用标记点
对于二进制分类,标签应为0(负)或1(正)
对于多类分类,标签应该是从零开始的类索引:0,1,2,....
标记点由事例类 LabeledPoint 表示
◆ 我们在前面介绍过"监督学习”, 知道监督学习是(x,y)数据形式,其中这个y就是标签,X是特征向量
标签数据也是一样,我们看一下这个代码
LabeledPoint(1.0,Vectors.dense(1.0,2.0,3.0))
2.3 本地矩阵
本地矩阵具有整数类型的行和列索引和双类型值,存储在单个机器上。 MLlib支持密集矩阵,其入口值以列主序列存储在单个双阵列中,稀疏矩阵的非零入口值以列主要顺序存储在压缩稀疏列(CSC)格式中
与向量相似,本地矩阵类型为Matrix , 分为稠密与稀疏两种类型。同样使
用工厂方法Matrices来生成。但是要注意,MLlib的矩阵是按列存储的。
例如下面创建一个3x3的单位矩阵:
Matrices.dense(3,3,Array(1,0,0,0,1,0,0,0,1))
类似地,稀疏矩阵的创建方法
Matrices.sparse(3,3,Array(0,1,2,3),Array(0,1,2),Array(1,1,1))
2.4 分布式矩阵
◆ 把一个矩数据分布式存储到多个RDD中
将分布式矩阵进行数据转换需要全局的shuffle函数
最基本的分布式矩阵是RowMatrix.
分布式矩阵具有长类型的行和列索引和双类型值,分布式存储在一个或多个RDD中。选择正确的格式来存储大型和分布式矩阵是非常重要的。将分布式矩阵转换为不同的格式可能需要全局shuffle,这是相当昂贵的。到目前为止已经实现了四种类型的分布式矩阵。
基本类型称为RowMatrix。 RowMatrix是没有有意义的行索引的行向分布式矩阵,例如特征向量的集合。它由其行的RDD支持,其中每行是局部向量。我们假设RowMatrix的列数不是很大,因此单个本地向量可以合理地传递给驱动程序,也可以使用单个节点进行存储/操作。 IndexedRowMatrix与RowMatrix类似,但具有行索引,可用于标识行和执行连接。 CoordinateMatrix是以坐标 list(COO) 格式存储的分布式矩阵,由其条目的RDD支持。 BlockMatrix是由MatrixBlock的RDD支持的分布式矩阵,它是(Int,Int,Matrix)的元组。
2.5 分布式数据集
◆ RDD Dataset DataFrame都是Spark的分布式数据集的数据格式
三者在一定程度上可以互相转化,有各自的适用范围
其中RDD是最为基础与简单的一种数据集形式
2.5.1 RDD
◆ RDD(Resilient Distributed Datasets),弹性分布式数据集,是Spark中结构最简单,也是最常用的一类数据集形 式。
可以理解为把输入数据进行简单的封装之后形成的对内存数据的抽象。

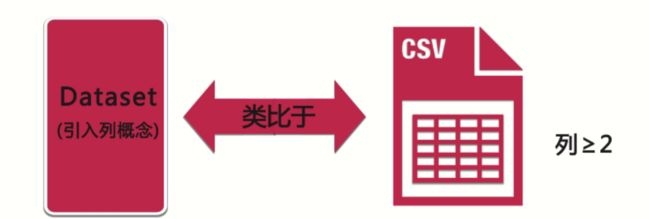
2.5.2 Dataset
◆ 与RDD分行存储,没有列的概念不同,Dataset 引入了列的概念,这一点类似于一个CSV文件结构。类似于一个简单的2维表
2.5.3 DataFrame
DataFrame结构与Dataset 是类似的,都引|入了列的概念
与Dataset不同的是,DataFrame中的毎一-行被再次封装刃Row的対象。需要通过该対象的方法来获取到具体的值.
3 MLlib与ml
3.1 Spark提供的机器学习算法
◆ 通用算法
分类,回归,聚类等
◆ 特征工程类
降维,转换,选择,特征提取等
◆数学工具
概率统计 ,矩阵运算等
◆ pipeline 等
3.2 MLlib与ml的区别
MLlib采用RDD形式的数据结构,而ml使用DataFrame的结构.
◆ Spark官方希望 用ml逐步替换MLlib
◆ 教程中两者兼顾
如无特殊指明,MLlib指代Spark的机器学习组件
4 MLlib的应用场景
4.1 海量数据的分析与挖掘
◆ 例如对海量的房屋出租,出售信息进行数据挖掘,预测房价价格,租金
◆ 典型数据集:波士顿房价数据集
◆ 主要用到传统的数据挖掘算法,例如使用回归算法
4.2 大数据机器学习系统
◆ 例如自然语言处理类的系统,推荐系统等
◆ 推荐系统,需要实时进行数据的收集,统计,任务调度,定期更新训练模型
◆ 核心实现: Spark Streaming +MLlib
Spark机器学习实践系列
- 基于Spark的机器学习实践 (一) - 初识机器学习
- 基于Spark的机器学习实践 (二) - 初识MLlib