团员分享_如何构建客服机器人的知识体系_@Wing
前言:本文作者是咱们“AI产品经理大本营”团员@Wing (微信公众号:鸡翅姐),是就职于平安寿险智能平台总部的AI产品经理,主要负责寿险知识库平台的产品设计以及与问答引擎相关联项目的落地支持。本文,是为了解答团员@小醋 的如下问题而作的详细剖析干货。
【@小醋:“团长您好!目前在负责公司一款起步阶段的智能客服产品,我的难题在于机器人的训练需要大量有效的Q&A问答库,但目前主要依靠客服手工整理,效率低下。饭团里智能客服有关的我都会认真看,但知识库构建这块却鲜少文章设计,希望团长可以指点一二,感谢!”】

首先,谢谢团长的信任,邀请我就以上团员提出问题做个简单的分享。本文分3个部分:
一、客服机器人的分类和决策引擎
二、客服机器人的数据来源与使用方法(重点)
三、客服机器人的知识管理方式(重点)
1
客服机器人的分类和决策引擎
1、客服机器人的分类
无论是哪个领域,只要是一个定位明确的客服机器人,其产品设计的目标都是通过最短路径为用户提供服务,“服务”包括信息查询(比如电商场景下的查询订单状态)、购买咨询(比如保险场景下的产品购买建议)、FAQ类咨询(比如公司地址与联系电话等)等等。
如下图,我把客服机器人与用户的对话,分为三个类型:
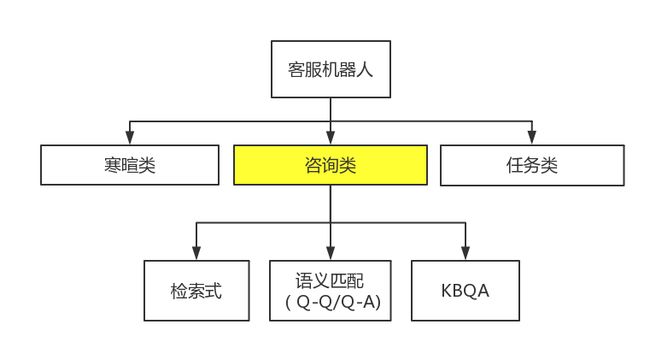
寒暄类:与核心业务流程无关的对话,可以统称为“寒暄类”,也是客服机器人的兜底话术。我这里没有用“闲聊”,是因为我个人不认为“闲聊”是客服机器人应提供的核心服务之一。
任务类:通过一或多轮对话的方式帮用户完成某项目的明确任务。
咨询类:为用户答疑解惑,通常为一问一答的方式,也包括通过澄清和指代消解而产生的多轮对话。
本文分享的内容,主要是聚焦在(针对于)咨询类对话。
从实现方式上作区分,咨询类对话又可以分为检索式、语义匹配式和KBQA三种;不过,在咨询的时候,用户是感知不到这三类的区别的。
2、客服机器人的决策引擎
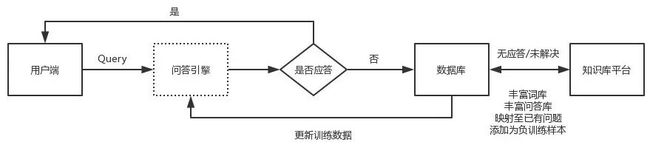
客服机器人在解析用户query的第一步是在去判断用户的意图。意图检测是由叫做“Route bot(路由机器人)”的系统来完成,比如,当用户输入“我银行卡余额”时,可以识别出用户此时是想完成“查询银行卡余额”这一任务;而当用户询问“银行卡余额在哪儿可以查”时,则需要识别出用户需要一个查询银行卡余额的路径。确认用户意图后,路由机器人再将此query交给不同的“子机器人(Botlets)”去处理。最后,Botlets生成的回复将在策略中心完成融合、去重和重排序等过程,最终产生一个或一组最优解。
下面这幅流程图,描述了从用户Query到生成回复的过程。该流程的每一步都值得深挖,但由于不是本次分享的重点暂不赘述。
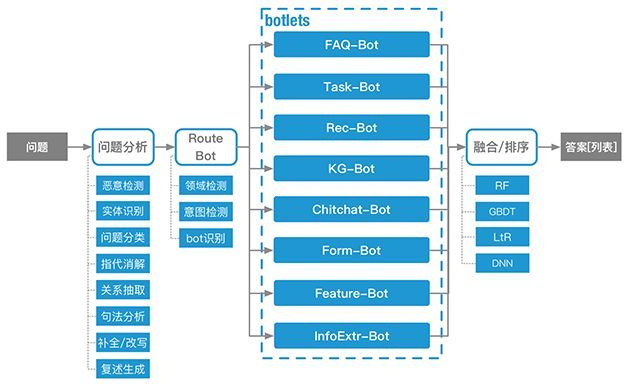
(摘自 http://t.cn/ReuDX71 )
在客服场景中,我们尝试去重现的,就是一个积累了业务流程知识、产品与服务知识以及用户交流技巧的客服人员。
对于刚上岗、零经验的真实客服人员来说,Ta首先需要了解的,通常是以下几点:
服务的边界:自己负责的产品线/业务线的服务范围是什么?对于不在服务范围内的项目,如何与客户沟通?
服务的特色:有哪些是服务的核心亮点?如何在服务的过程中巧妙地趋利避害?
升级渠道:服务过程中遇到难以解决或意外情况如何处理?
类似的,客服机器人也需要经历“培训”,本文,我们主要探讨的就是如何培养客服机器人的数据能力。
2
客服机器人的数据来源与使用方法
前文提到,咨询机器人可以通过“检索式”、“语义匹配”以及“KBQA”三种方式来生成答案,其实,上述每一种方式都需要收集相应的语料来训练,且不管是哪一类语料,从数据的结构化程度来说,都可以分为以下三种:
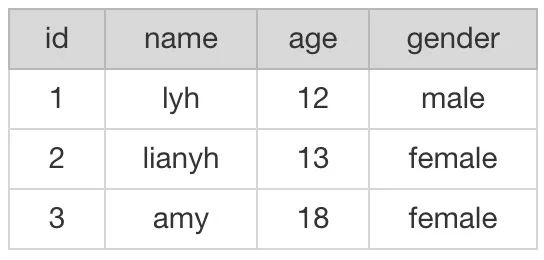
1、结构化数据:指可以使用关系型数据库表示和存储、表现为二维形式的数据。例子:
2、半结构化数据:结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记。这些标记是用来分隔语义元素,以及对记录和字段进行分层。半结构化数据也被称为自描述的结构。例子:

3、非结构化数据:即就是没有固定结构的数据。各种文档、图片、视频、音频等都属于非结构化数据。这种数据广泛地存在,但并不直接可用。需要通过一定手段来提取/标注每个数据所包含的关键信息。
下面,我们逐个聊聊这三种类型的数据如何获取与使用。
2.1 结构化数据的来源与使用方法
目前大多数的DUI平台,都支持以“Question-Answer”的格式批量导入语料。比如下图,是海知智能(ruyi.ai) 机器人平台提供的知识库批量导入模板与示例。
以及图灵机器人配置平台提供的批量导入模板:

以及思必驰会话精灵知识问答批量导入模板:
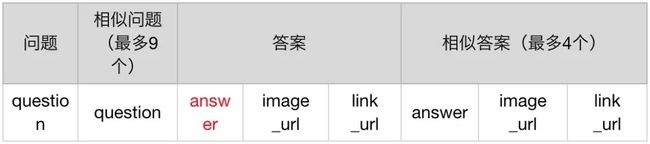
当客服机器人有这样一个充满QA语料的知识库之后,就可以通过基于语义相似度的Q-Q匹配模型,从知识库中召回与用户query相似度较高的几个标准问题。(注:有相关的参考文章《NLP基本功-文本相似度 | AI产品经理需要了解的AI技术通识》)
然而,从我观察客服手工整理知识库的经验来看,扩充相似问题/相似说法并不是件容易的事情,特别的,当涉及到垂直领域业务强相关的问题时,客服人员很难开脑洞给每个问题想出几百种不同的问法。我司的客服机器人在上线之前,相似说法/标准问题的比率大概在10。
然而当机器人上线之后,我们从每天客服bot与用户的聊天日志中找到了灵感。在聊天日志中,我们主要关注并收集了大量“未应答问题”(由于置信度不够没有返回答案导致的badcase),这些未应答问题一部分可以作为存量标准问题的相似说法,还有一部分为新增标准问题提供了灵感。我们发现,让标注人员去“猜用户的疑惑”的难度远高于“将用户query标注为扩展问”。做填空题是难于做选择题的。
因此,我们的知识库平台在多个环节,都会尝试引导知识库管理员去标注扩展问。这里简单分享两个设计点:
1、助手机器人:平台内部用于测试问答表现效果的Demo机器人。
知识管理员在与Demo bot对话时,通常会通过口语化的表达来测试问答匹配效果。在Demo界面,我们提供了与测试query语义最相似的Top 5列表。如发现问题匹配错误,可以在测试的过程中,及时将测试query映射至其他的标准问题,这既是纠错、也是标注相似说法的过程。
2、日志挖掘:将与未应答问题相似度最高的Top 5标准问题返回给知识管理员进行标注。
为了提高标注效率,可以考虑根据语义相似度,先将未应答问题做聚类,然后标注人员再统一将这一组问题映射至一个标准问题。并且,出于标注的准确性考虑,我们会提供上下文信息给标注人员,以帮助其更好地对bad case进行分析。最后,要想继续提高效率与精准度,可以根据业务发展情况与线上的表现来做调整。
此外,如果在上线客服机器人之前,业务已经有线上客服的渠道或者论坛(类似于百度知道/知乎的版块),则可以在设计机器人初期,就将线上客服沉淀下来的数据做清洗,并从中提炼出热点/高频问题优先进行梳理。
讲完结构化数据后,下面我们讲讲半结构化知识数据的来源与使用方法。
2.2 半结构化数据的来源与使用方法
假设我们需要给耐克设计一个客服机器人,对于如下所示的产品类信息,可以从哪里低成本获得呢?

如果你本身就是这家企业的员工,那一定能找到product catalogue(产品目录)。它可能是以多个excel文件的形式散落在各个部门,也有可能已经被存至数据库、并应用在官网或其他电商渠道。如果客服bot所需的部分信息已经在线上,直接去爬取就可以获得大量半结构化数据。当然,在爬取之前,需要对目标网站内容的可信度进行充分评估。若从多于一个渠道爬取数据,则还涉及到数据融合的问题。
当我们有一个整理如上述格式的产品目录之后,就可以通过搭建知识图谱来回答以下几个问题:
“复刻男子运动鞋”类有哪些选择/产品?
Air Jordan 1 多少钱?
绿色的鞋有哪些选项?
Air Jordan 1 有货吗?
也可以基于简单的推理回答以下问题:
价格在800-1000左右的鞋有哪些选项?
Air Jordan 1 和 Air Force 哪个便宜?
除了Air Jordan 1 之外,绿色的运动鞋还有哪些选项?
复刻系列里面最便宜的是哪一款?
大家可能尝试过,在Google或百度的搜索框里直接问一些与人物、机构相关的问题,比如“微软的创始人是谁?”,它会直接把比尔盖茨的信息卡片返回给你。这个过程,就是基于底层的一个庞大的人物&机构知识图谱。当然,你的知识图谱能回答哪些问题,是需要根据图谱搭建的深度和广度去人为定义模板的。比如“绿色的鞋有哪些选项?”这个问题就会被解析成一个“ ? (产品)—颜色属性—绿色”的查询语句,在整个知识图谱中完成搜索,并输出符合该条件的答案。
这种基于知识图谱构建的问答也被叫做KBQA。与客服手工构建QA pair相比,KBQA的最大好处就是可以回答预设好的“几类问题”。比如说“XX色的鞋有哪些选项?”,就是一类问题,而XX这个实体的值可以是任何颜色。这样就不需要手工去逐个编写“蓝色的鞋有哪些选择?”“红色的鞋有哪些选择?”…从而节省了大量的人工标注成本。
2.3 非结构化知识的来源与使用方法
之前我们讲过,非结构化数据就是没有固定结构的数据,而“在线客服与用户的聊天日志”就属于非结构化知识。在3.1小节提到过,可以把聊天日志中用户的Query抽取并清洗出来,进而丰富问答语料。但其实,如果你保留了大量的对话片段,也可以使用检索式模型从库中pick最优回复。
基于检索的对话模型所需的语料形式是“Context-Utterance”,即“上下文-回复”对,而标签则是“0”和“1”,其中“1”表示该Utterance可以作为Context的回复(见下图:Ubuntu Dialog Corpus的样例)。

(摘自Lowe et al., 2016. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems)
模型的原理和实现细节,就不在此赘述了。该模型的本质,是一个预测模型,即对于一个输入的Context,预测某个Utterance为合理回复的概率。比如,当我的库中已经有了大量与手机维修相关的Context-utterance正样本后,当该情景再次出现时,我会将最大概率为正确回复的Utterance返回给用户。

(摘自Bartl & Spanakis, 2017. A retrieval-based dialogue system utilizing utterance and context embeddings.图中的Context描述了一个手机维修的对话场景;“Actual Response”是该Context的真实回复内容。而“HREDG-CAR”是文中所用模型召回的三个最佳候选回复。)
如果要使用这样的方法来生成回复,那需要标注人员做的,就是将在线客服与用户的聊天记录做场景化整理。比如“报修”、“退换货”、“补差价”、“优惠券领取”等。对于情景复杂、需要上下文信息的咨询类场景来说,可以尝试使用这样的模型。
3
客服机器人的知识管理方式
客服机器人与闲聊机器人最大的区别,在于前者是与公司的核心业务强相关的,而后者不是。因此,做客服机器人的知识管理,需要考虑到知识的时效性、专业性和一致性。比如,活动类的QA有起效和过期的时间,在到期之前和过期之后,都要给客户/用户一个友好的引导;服务和产品类QA需要与用户属性相关,比如,对于不同的新客户和VIP客户,即使是同一个问题,其答案也要做差异化的回复和引导;还比如,对于同一个用户,如果Ta在不同时间、不同渠道(比如官方小程序、App、微信公众号后台)问了同一个问题(比如某某分店的地址是哪里联系方式是什么),我们需要确保答案(表意)的一致性,否则会使用户迷惑。
因此,客服机器人的知识库构建,不仅需要Q-A相关的信息,也需要其他的字段来给Q-A做描述或限制。这里,就需要产品经理结合公司的核心业务来做深入思考,并设计一个拓展性强、可用性与灵活性高的知识管理平台。
这个知识管理平台,需要兼顾对语料的管理和对聊天日志的管理,并结合NLP手段尽可能地降低bad case的分析与标注成本。如下图,知识管理平台需要给知识管理员提供一个bad case标注功能,用线上数据快速扩充语料并优化模型。
除此之外,引导并鼓励知识管理员去丰富专业词库、丰富问答语料或将匹配度较高的标准问题标记为用户query的负样本,都对提升问答引擎的表现有帮助。当然,以上功能点的重要性以及投入产出比,需要产品与算法工程师以及业务负责人沟通后再决定优先级。
END.
支持hanniman,赞赏原创AI干货

注:以上内容来自由黄钊hanniman建立的、行业内第一个“AI产品经理成长交流社区”,通过每天干货分享、每月线下交流、每季职位内推等方式,帮助大家完成“AI产品经理成长的实操路径”;详情可点击“阅读原文”查看。
- hanniman往期精选 -
一、AI产品分析
【重点】如何从“品类”角度做AI产品(2C)的需求定位
【重点】产品视角看智能客服
智能音箱上的语音技能市场,能否对标手机上的应用市场?
进击的人工智能:产品视角解析“对话机器人”
如何从零开始搭建智能外呼系统
现阶段实践“拿着锤子找钉子”的六个步骤
二、AI产品经理
【重点】【重磅福利】人工智能产品经理的新起点(200页PPT下载)(注:后台回复“200”,可获取PPT下载链接)
【重点】AI产品经理的定义和分类
【重点】AI产品经理的价值和未来 | 学习俞军老师分享有感
团员分享_AI小白如何拿到AI产品经理offer
深度报告 | AI新职位“人工智能训练师”
福利 | 《从互联网产品经理到AI产品经理》PPT下载及讲解(58P)
三、AI技术
【重点】AI产品经理需要了解的语音交互评价指标
【重点】值得收藏 | 关于机器学习,这可能是目前最全面最无痛的入门路径和资源!
NLP基本功-文本相似度 | AI产品经理需要了解的AI技术通识
看AI产品经理如何介绍“计算机视觉”(基于实战经验和案例)
人脸识别 | AI产品经理需要了解的CV通识(二)
多目标跟踪 | AI产品经理需要了解的CV通识(三)
填槽与多轮对话 | AI产品经理需要了解的AI技术概念
AI产品经理需要了解的数据标注工作入门
语音识别类产品的分类及应用场景
四、AI行业及个人成长
【重点】【深度】工作5年以上,到底要不要进AI创业公司?
【重点】深度 | 人工智能让我们失业?不,这取决于我们自己
【重点】我们还没准备好和AI共生——柯洁和AlphaGo大战之观后感
“人工智能与法律”对AI产品经理有何实际借鉴意义
稻盛和夫的这些话,是鸡汤还是干货?
跨过这十个误区,提前2年告别职场小白
如何分辨明师并遇到他 | 周日换频道(7)
---------------------
作者:黄钊hanniman,图灵机器人-人才战略官,前腾讯产品经理,6年AI实战经验,9年互联网背景,微信公众号/知乎/在行ID“hanniman”,饭团“AI产品经理大本营”,分享人工智能相关原创干货,200页PPT《人工智能产品经理的新起点》被业内广泛好评,下载量1万+。