利用TextCNN对IMDB做文本分类
正文
参考博客:
IMDB预处理
TextCNN模型
1.下载kaggle数据集,并进行文本预处理:
# 导入相应的包
import pandas as pd
import warnings
import re
import matplotlib.pyplot as plt
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, LSTM, Embedding, Dropout, Conv1D, MaxPooling1D, Bidirectional
from keras.models import Sequential
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
# 读取数据
df1 = pd.read_csv('word2vec-nlp-tutorial/labeledTrainData.tsv', sep='\t', error_bad_lines=False)
df2 = pd.read_csv('word2vec-nlp-tutorial/imdb_master.csv', encoding="latin-1")
df3 = pd.read_csv('word2vec-nlp-tutorial/testData.tsv', sep='\t', error_bad_lines=False)
df2 = df2.drop(['Unnamed: 0','type','file'],axis=1)
df2.columns = ["review","sentiment"]
df2 = df2[df2.sentiment != 'unsup']
df2['sentiment'] = df2['sentiment'].map({'pos': 1, 'neg': 0})
# 合并数据
df = pd.concat([df1, df2]).reset_index(drop=True)
train_texts = df.review
train_labels = df.sentiment
test_texts = df3.review
# 英文缩写替换
def replace_abbreviations(text):
texts = []
for item in text:
item = item.lower().replace("it's", "it is").replace("i'm", "i am").replace("he's", "he is").replace("she's", "she is")\
.replace("we're", "we are").replace("they're", "they are").replace("you're", "you are").replace("that's", "that is")\
.replace("this's", "this is").replace("can't", "can not").replace("don't", "do not").replace("doesn't", "does not")\
.replace("we've", "we have").replace("i've", " i have").replace("isn't", "is not").replace("won't", "will not")\
.replace("hasn't", "has not").replace("wasn't", "was not").replace("weren't", "were not").replace("let's", "let us")\
.replace("didn't", "did not").replace("hadn't", "had not").replace("waht's", "what is").replace("couldn't", "could not")\
.replace("you'll", "you will").replace("you've", "you have")
item = item.replace("'s", "")
texts.append(item)
return texts
# 删除标点符号及其它字符
def clear_review(text):
texts = []
for item in text:
item = item.replace("
", "")
item = re.sub("[^a-zA-Z]", " ", item.lower())
texts.append(" ".join(item.split()))
return texts
# # 删除停用词 + 词形还原
def stemed_words(text):
stop_words = stopwords.words("english")
lemma = WordNetLemmatizer()
texts = []
for item in text:
words = [lemma.lemmatize(w, pos='v') for w in item.split() if w not in stop_words]
texts.append(" ".join(words))
return texts
# # 文本预处理
def preprocess(text):
text = replace_abbreviations(text)
text = clear_review(text)
text = stemed_words(text)
return text
train_texts = preprocess(train_texts)
test_texts = preprocess(test_texts)
2.token编码、padding操作、切分数据集
也就是建立onehot向量,这里只取频率排行前6000个单词构建词典,令max_features = 6000; 然后将每个样本(句子)定为长度130(不够长补0,多余截断)
max_features = 6000
texts = train_texts + test_texts
# 转换为onehot向量,num_words:保留词频前max_features的词汇,其他词删去。仅num_words-1保留最常用的词。
tok = Tokenizer(num_words=max_features)
tok.fit_on_texts(texts)
vocab = tok.word_index
# 将文本按照词典编号的方式进行编码
list_tok = tok.texts_to_sequences(texts)
#对每个样本最大长度做限制,定为130,其余补0
maxlen = 130
seq_tok = pad_sequences(list_tok, maxlen=maxlen)
x_train = seq_tok[:len(train_texts)] #只取到train_texts的样本
y_train = train_labels
embed_size = 128 #此为通过embedding矩阵乘法,我们想让一个样本(句子)中每个单词压缩成的向量维度
x_train,x_test,y_train,y_test = train_test_split(x_train,y_train) #切分训练、测试集
3.整理好数据后,采用TensorFlow中的CNN模型或者TextCNN模型进行训练
import pandas as pd
import jieba
from keras.models import Sequential
from keras.layers.merge import concatenate
from keras.utils import to_categorical
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tensorflow import *
from keras.layers.embeddings import Embedding
from keras.layers import Conv1D, MaxPooling1D, Flatten, Dropout, Dense, Input, Lambda,BatchNormalization
from sklearn.metrics import accuracy_score, f1_score
from keras.models import Model
import numpy as np
#构建TextCNN模型
#模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
def TextCNN_model_1(x_train_padded_seqs,y_train,x_test_padded_seqs,y_test):
main_input = Input(shape=(130,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=130, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=128)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=127)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=126)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(2, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=2) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=10)
#y_test_onehot = keras.utils.to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
# y_predict = list(map(str, result_labels))
# print('准确率', metrics.accuracy_score(y_test, y_predict))
# print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))
print('准确率', accuracy_score(y_test, result_labels))
print('平均f1-score:', f1_score(y_test, result_labels, average='weighted'))
4.训练结果(在colab上训练):

读取数据集


5.模型理解:
这里可以通过model.summary或者keras中的plot_model来输出模型整体结构,帮助理解,plot_model报错踩坑
尤其是像这种有concatenate函数合并的结构,图形可视化很直观,方便学习。
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(10000 + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(10, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
from keras.utils import plot_model
import pydot
plot_model(model,to_file='TextCNNmodel2.png',show_shapes=True,show_layer_names=False)

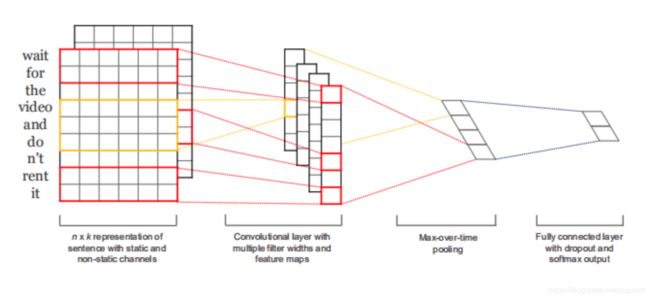
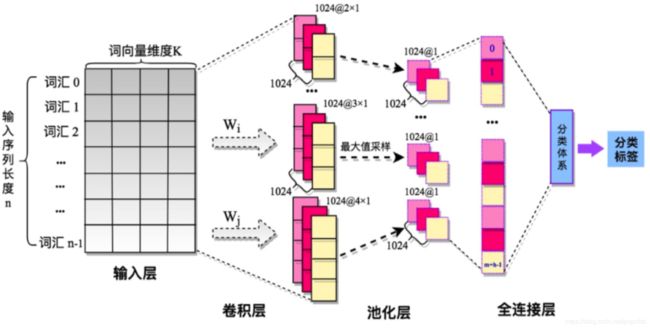
相比于图像领域的CNN,文本处理中的TextCNN有一定的差异,第一是在维度上面,由图二(普通CNN):每一个卷积核宽度就是每个词向量的长度,从上向下滑动,没有图像领域中的横向滑动,故调用Conv1D,每次滑动几个单词就是卷积核的高度,如图三:三种不同高度的卷积核,能够每次读取不同相邻个数的单词,这里有点像n-gram的感觉,不同高度的卷积核能够提取不同的特征,而这些特征恰好能够体现词与词之间的关联,
图一中:每一层的第一个维度是None,这里的None就是你的batchsize,每次处理的样本个数,因为这个参数是在model.fit中定义,所以这里显示none。
-
输入层:维度为batchsize × \times × input_length ,input_length就是我们的一个句子的长度,就像图二中 输入层左边从上到下就是一句话,一个句子就是一个样本。
-
Embedding层:将batchsize × \times × input_length输入embedding层中,embedding层的参数300,就是我们想要每个词向量维度变成的长度,为什么要这么做呢?因为如果每个词都是用onehot向量,那么整个单词词典有多长,词向量就有多长,这样第一:计算能力要求会非常高,当词典无限大的时候也没法办了,第二:onehot向量只体现了词频,无法体现语义上的含义,我们更希望采用一个低维的向量来刻画单词本身,embedding的作用就是降维,当输入之后,embedding层用input_length × \times ×(len(vocab)+1) 来与 (len(vocab)+1)$\times$300相乘,就将每个句子变成了:input_length $\times$300的矩阵,从而实现词向量的降维,而这一层刚开始就是起到初始化的作用。这里不同于word2vec的是:word2vec的目的是训练词向量,而embedding是训练词向量的一种方式,或者说在整个模型任务达到收敛后,embedding层训练出来的词向量就是切合任务需求的(这里模型后面层可能是二分类,也可能是多分类或者等等任务)。
-
卷积层:这里TextCNN设置了3、4、5的三个不同高度的卷积核,每次滑动的时候进行向量乘法,padding选为same就是让卷积之后得到的长度和原来长度(50)一致,举例:当卷积核高度为3时,步长为1向下滑动,每滑动一次生成一个向量值,那么要保证前后长度都为50的话,就要在原来的50长度下面加2个padding值。
-
池化层:参数中如果不特别设定步长,keras默认和池化大小(pool_size)相同,定为48就是因为没算padding的0.