本篇主要内容:ROC曲线、多分类混淆矩阵
ROC曲线
ROC全称是Receiver Operation Characteristic Curve,它描述的是TPR和FPR之间的关系。
TPR(True Positive Rate)的计算公式为:
它表示预测值为1,真实值也为1中预测正确的比例,TPR其实就是Recall。FPR(False Positive Rate)的计算公式为:
它表示预测值为1,真实值为0中预测错误的比例。和上篇文章中Precision和Recall负相关不同,TPR和FPR之间是正相关关系,TPR增加相应地FPR也会增加。
接下来使用我们自己的模块绘制ROC曲线,在这之前,首先在play_Ml模块的metrics.py中添加相关代码:
'''分类问题评价指标'''
import numpy as np
from math import sqrt
def TN(y_true, y_predict):
assert len(y_true)==len(y_predict)
return np.sum((y_true==0)&(y_predict==0))
def FP(y_true,y_predict):
assert len(y_true)==len(y_predict)
return np.sum((y_true==0)&(y_predict==1))
def FN(y_true,y_predict):
assert len(y_true)==len(y_predict)
return np.sum((y_true==1)&(y_predict==0))
def TP(y_true,y_predict):
assert len(y_true)==len(y_predict)
return np.sum((y_true==1)&(y_predict==1))
def confusion_matrix(y_true,y_predict):
return np.array([
[TN(y_true,y_predict),FP(y_true,y_predict)],
[FN(y_true,y_predict),TP(y_true,y_predict)]
])
def precision_score(y_true,y_predict):
tp = TP(y_true,y_predict)
fp = FP(y_true,y_predict)
'''分母为0'''
try:
return tp/(tp+fp)
except:
return 0.0
def recall_score(y_true,y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
'''分母为0'''
try:
return tp/(tp+fn)
except:
return 0.0
def f1_score(precision,recall):
try:
return 2*precision*recall/(precision+recall)
except:
return 0.0
def TPR(y_true,y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
'''分母为0'''
try:
return tp/(tp+fn)
except:
return 0.0
def FPR(y_true,y_predict):
fp = FP(y_true,y_predict)
tn = TN(y_true,y_predict)
'''分母为0'''
try:
return fp/(fp+tn)
except:
return 0.0
使用的数剧集仍然和上篇相同,是处理为2类的手写数字数据集,分类方法使用Logistic回归:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9]=1
y[digits.target!=9]=0
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
decision_scores = log_reg.decision_function(X_test)
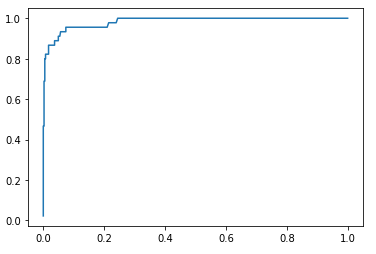
绘制ROC曲线:
from play_Ml.metrics import FPR,TPR
fprs = []
tprs = []
thresholds = np.arange(np.min(decision_scores),np.max(decision_scores),0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold,dtype=int)
fprs.append(FPR(y_test,y_predict))
tprs.append(TPR(y_test,y_predict))
'''绘制ROC曲线'''
plt.plot(fprs,tprs)
plt.show()
ROC曲线:
同样也可以使用sklearn中已经封装好的函数roc_curve,该函数传入参数标签的真值和decision_scores,得到三个返回值fprs, tprs, thresholds,这样就可以根据fprs和tprs做图:
from sklearn.metrics import roc_curve
fprs, tprs, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs,tprs)
plt.show()
ROC曲线:
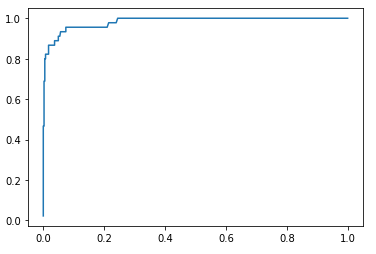
得到的是相同的结果。ROC曲线下的面积一定程度上代表了模型的好坏,面积越大模型一般就越好,这个面积最大是1。sklearn中封装了求ROC曲线下面积的函数:
'''求面积,area under curve'''
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test,decision_scores)
本例模型中ROC曲线下面积:
在本例中0.98这个结果是相当好的,不过,ROC曲线面积指标并不对有偏数据很敏感,因此一般不用来单独评价一个模型性能的好坏,而是有多个模型在一块时,将ROC曲线绘制在一起,它能用来直观比较孰优孰劣。
多分类问题的混淆矩阵
前面关于混淆矩阵是基于二分类问题讨论的,现在来看一下对于多分类问题,混淆矩阵是什么样的。仍然使用手写数字数据集,只是不再让它变为二分类,直接处理这样的10分类,我们来看一下它的混淆矩阵:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.8, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
'''OVR'''
y_predict = log_reg.predict(X_test)
from sklearn.metrics import confusion_matrix
'''天然支持多分类混淆矩阵'''
confusion_matrix(y_test,y_predict)
混淆矩阵:

sklearn中的confusion_matrix是支持多分类问题求混淆矩阵的。有了混淆矩阵我们可以为混淆矩阵做图观察分析分类出错的地方都出现在哪里,以更好地改进模型,首先看一下各种错误所占百分比:
row_sums = np.sum(cfm,axis=1)#求行和
err_matrix = cfm/row_sums
np.fill_diagonal(err_matrix,0)
err_matrix
犯错百分比:

接下来对这些错误做图,对于犯错越多的相应的像素值越高,用灰度图像展示出来也就是亮度越亮:
plt.matshow(err_matrix,cmap=plt.cm.gray)
plt.show

由图看出,犯错最多的是有两个地方,一个是1被错分类为9,另一个是8被错分类为1,知道这两种错误最多之后就可以相应的改进模型调整模型参数,使之表现更佳。