requests库的安装
本文是基于 中国大学MOOC教程 中《Python网络爬虫与信息提取》 做的学习笔记,笔者在这里做一个分享
Request 库是python的第三方库,它也是目前公认的爬取网页最好的第三方库。关于request库的更多信息可从http://www.python-requests.org中获得。
step 1:用管理员权限启动cmd控制台(windows环境中)。

step 2:在cmd控制台以管理员权限输入pip install requests,安装requests库安装包。
在实际安装过程中,我的电脑并没有视频中那么顺利,出现了如下的bug:
ImportError: cannot import name IncompleteRead
刚开始小偷了一下懒,感觉不是什么大问题,于是在IDLE端验证requests库是否正确安装时,发现IDLE报错提示“ImportError: No module named 'requests'”看来我得重视这个bug
【问题解决过程】
经过不断的尝试,我发现可能是pip这个安装包并没有安装好,于是在我的cmd窗口命令下对pip包进行了安装。安装过程如下:首先进入网页 https://pypi.python.org/pypi/pip#downloads下载pip-9.0.1.tar.gz 。(注意是画红线的部分)

安装包下载完毕后,将其解压到制定目录下,切换到cmd窗口,将cmd命令行的当前目录制定为解压目录,同
时在图形界面找到setup.py文件(在pip-9.0.1目录中)。然后在cmd下将目录继续切换到setup.py所在目录,执行
python setup.py install
最后cmd会提示你pip安装成功。安装好之后,直接在命令行输入pip,此时会显示 pip不是内部命令,也不是可运行的程序。 出现错误的原因是还没有添加环境变量。(详细请参照 windows下面安装Python和pip终极教程)。最终,在cmd窗口输入 pip指令检查是否完整安装pip。
安装好pip后,继续完成requests库的安装,在cmd中以管理员身份安装requests:

提示requests库已经安装在对应的目录下
step 3在python(x,y)中的spyder平台下测试requests安装的效果。
首先将requests库导入,这里以访问百度主页为示例,查看它的状态码(r.status_code),状态码是200,表示访问成功。再更改它的编码为‘utf-8’编码,打印网页内容,如下:
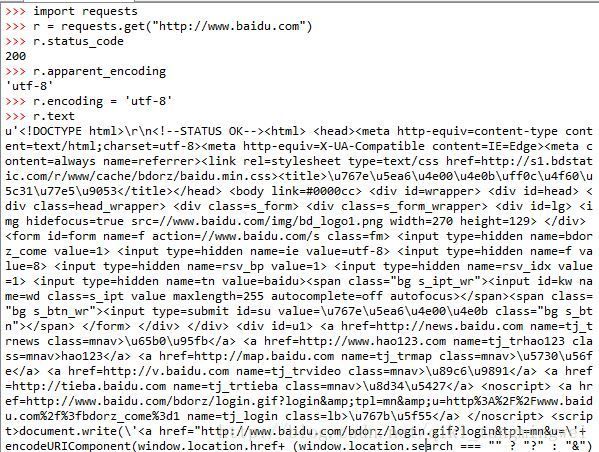
(由于屏幕显示原因,这里只截取一部分图)此时百度的主页已经成功地被抓取下来了。但是可以看出,虽然更改了r.encoding = ‘uft-8’,但是爬取的网站中的中文字符依旧是乱码,说明文字的编码不正确。而查阅资料发现,python爬取网页最终的文本处理,就是用的utf-8来解码。笔者怀疑在命令行输入中文字符的时候会不会也出现乱码,于是在脚本框输入
>>> print"你好!世界"发现依旧能正常显示,那就说明单就爬取网页的时候,对中文字符的解码出现了问题。那么问题究竟在哪呢?
于是小编又进行了尝试,尝试抓取全英文网站,看看在不含有中文字符的网站抓取中会不会出问题。

结果是正确爬取出有效数据,部分截图如下:

采用相同的爬取代码访问带有中文字符的百度主页,却提示如下问题

参考里的这篇文章详细介绍了编码问题。
经过多番尝试,笔者发现,问题在于正常使用requests的时候,它会自动猜源文件的编码方式,然后转码成Unicode的编码,但是,毕竟是程序,是有可能猜错的,所以如果猜错了,我们就需要手工来指定编码方式。
res.encoding = ('utf8'),阅读 http://jingyan.baidu.com/article/2c8c281dbb969d0008252a80.html 发现,在写脚本语句是,要注意在代码开始指定代码的默认编码! # -*- coding:utf-8 -*-
最后决定新建一个file文件,敲入代码如下:

最终得到了正确显示的中文字符,结果如下:

第一次写CSDN博文排版乱七八糟,逻辑乱七八糟,连装个requests库也不是那么一帆风顺,,coding的道路依旧艰难,爬行的程序媛继续加油吧↖(^ω^)↗