知识本体论文研究
Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks
文章已开源,点此地址传送
三个贡献点
1、提出SynGCN算法。结合语法信息(syntactic)和图卷积(GCN),并且没有增加词表规模。
2、提出SemGCN算法。结合语义信息(上下位词、同义词)以及GCN,并且只需要一个架构,而不需要针对不同的语义关系做特殊处理。
3、与ELMo联合使用时,各项数据集达到SOTA(state-of-the-art)。
图卷积 GCN 算法
1、前人用GCN在NLP方面,有机器翻译、语义角色标注、文本分类等等,但是从未用在词嵌入方面、无监督方面。
2、拓展:一些近年来GCN的变种 (Yadav et al., 2019; Vashishth et al., 2019)。如果想要了解GCN,作者推荐Bronstein et al. (2017)。
3、作者主要使用一阶函数的GCN,是由(Kipf and Welling, 2016) 提出的。
公式如下【公式1】:
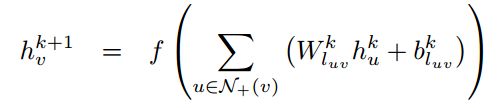
说明:
(1)luv:从u到v的有向边。
(2)W、b都是模型的学习参数。W是dxd维矩阵,b是d维向量。
(3)k是GCN模型的哪一层,每一层结构是相同的。
(4)h是目标词向量,d维。
(5)N(v)代表与v直接相连的点集,如果有+号就代表自己与自己建边。
4、边的选择机制
目的:因为在现实生活中,对于下游任务来说,某些边是错误的或者不相关的。
作者采用: edge-wise gating 方法 (Marcheggiani and Titov, 2017)
公式见下【公式2】:
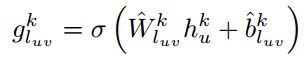
说明:
g:是一个 sigmoid激活函数处理过的一维的数值,代表这条边的可信度。
W^、b^ :与公式1一样是模型的学习参数。只不过两者是不同的参数。W^ 有d维,b^ 有一维。
5、作者最终的GCN
组合公式1、2得到【公式3】
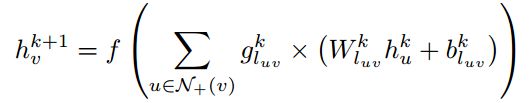
6、我认为有意思的【这节不重要,可以不看】
(1)作者认为:cbow、glove算法需要给定窗口的大小。窗口大会引入不相关的噪声词,窗口小会导致某些相关的上下文词无法参与。这样容易陷入局部最优。
他的解决办法:使用基于语境的依赖可以缓解这个问题。
(2)图像编码体系结构(graph encoding architectures) 除了GCN,还有树状的LSTM,但是GCN可以避免递归依赖,所以它适合并行。
SynGCN 算法
1、优势:别人利用语法(Syntactic)信息,会导致词表的数目增加。该作者的不会。
2、图例

说明:这是一个英文句子,左侧的带方向的箭头表示主语(subj)、目标(obj)、依存关系(nmod)。其中 scientists_subj, water_obj, mars_nmod 这三个词语都依赖于 discover 这个词语。
3、提取依赖关系
给定一个句子s = (w1; w2; …, wn) 首先进行提取依赖。作者使用Stanford CoreNLP parser (Manning
et al., 2014),估计是直接调用接口就可以了。
4、算法是cbow的泛化模型
对公式3取消自己与自己建边得到【公式4】

作者证明了 cbow的公式是上面公式的特殊情况。即当f(x)=x,层数k=1,学习参数W、b分别变为1和0的时候,公式变为如下。此时就是cbow的上下文词向量相加的过程。

SemGCN 算法
1、利用语义信息(如:上位词、下位词、同义词)。作者考虑用:WordNet、FrameNet、PPDB 这些词典。
2、作者说,利用词典有两大派别:
(1)修改语言模型目标函数的,如: (Xu et al., 2014; Kiela et al., 2015; Alsuhaibani et al., 2018)
(2)作为后处理的,如 (Faruqui et al., 2014; Mrkšic et al., 2016).
该作者提出的SemGCN属于后者。另外还说到:前人的利用不同的语义关系时,需要针对不同的语义关系独立处理,而作者的只需一个体系就能够解决。
3、算法

说明:双箭头表示对称关系,单箭头(如:上、下位词)是非对称关系。
原理:算法利用Faruqui et al. (2014)的技巧,即会有两套词向量,一套是原始的,修正的过程不能动,并且自己会与自己建边。但是,此时更新的公式是上面公式3的,而不是Faruqui et al. (2014)的。
4、其它我觉得有价值的
作者说 Faruqui et al. (2014); Mrkšic et al. ´ (2016) 这两篇使用的正、反义词对,它们是对称关系的。而非对称关系的利用,作者引用到 (Alsuhaibani et al., 2018)。
SynGCN 和 SemGCN 的训练

目标函数 P 最终可以极大似然化成上述的 E 式子。但是这个式子计算复杂度很高,所以需要用近似的方法,如:噪音对比估计noise-contrastive estimation (Gutmann and Hyvärinen, 2010) 或者 hierarchical softmax (Morin and Bengio, 2005)。作者是使用负采样negative sampling (Mikolov et al. 2013b).【其实后面两个方法,在w2v里面都有用到。】
SynGCN 和 SemGCN 的联合使用
作者说目前他们联合使用的结果不好,他们认为语法信息可获得的数量是语义信息的多几个量级。
如何与 ELMo 算法结合
作者没具体说ELMo怎么结合在一起的,只在结果分析板块,直接说预训练模型用ELMo。因为ELMo只依赖于顺序的上下文(这句话,我有点怀疑作者是说:ELMo不是双向)。所以SynGCN可以提供双向的语法信息,而SemGCN可以提供同义词等信息。这项任务他们作为未来工作。
如果想要看如何结合ELMo,要看一下他的源码,或者详细看后面的论文内容才行。
实验设置、结果分析
【后面第8章往后就是实验设置、结果分析了。后面的我没看。】
个人的简单总结全文【不重要,可以不用看】
作者主要是提出一个公式。该公式有GCN、以及cbow的影子。然后根据提供的信息不同(语法信息,还是语义信息),分别提出SynGCN、SemGCN。论文写得挺简单明了的。
SynGCN使用到很像cbow的技巧【周围词累加预测中心词】,SemGCN使用到Faruqui et al. (2014)的技巧【后修正,固定初始的词向量,自己与自己建边】。
另外,一处比较重要的,作者能够结合ELMo作为基础的预训练模型。
(Renfen Hu, ACL 2019)Diachronic Sense Modeling with Deep Contextualized Word Embeddings:An Ecological View
贡献点一:获取一个词语中的某个解释的词向量。使用BERT,以及牛津词典。
1、目的:每个词语的全部解释,都各自表示成一个词向量。
2、方法步骤:
(1)从COHA数据集中统计词频,只保留连续50年及以上,每年词频大于10次的词语。最终 4881个词语,它们在牛津词典里一共 15836个解释。
(2)选定一个词语的一个解释,牛津词典各个解释的定义和对应的例句,可以直接从网上提供。
(3)预训练BERT。使用两个数据集进行预训练 BookCorpus(800M 词语)、 English Wikipedia (2,500M 词语) ,进行 Masked LM 和 Next Sentence Prediction 任务来预训练。
(4)一个解释只选最多10条句子。然后放到预训练好的BERT中,并且只要最后一层隐藏层的结果。此时,可以获得各个例句中,该解释的词向量,然后取平均作为这个词语解释的最终词向量。 该词向量是768维。
(5)对于一个新来的含有多义词的句子。首先放到BERT中获得该多义词的词向量,然后用这个词向量与在步骤4里面该词语各个解释的最终词向量进行余弦相似度计算,取最大的相似度,对用的词语解释作为本语句的预测。
3、公开数据集及分数
【论文中也叫:无时间变化的解释辨别任务。主要是与下一个“随时间变化,词语意思在变化”的任务进行区分。】
数据集:作者自己在牛津词典里面随机选择2000条句子。

说明:使用NLTK的POS词性标注是指,预测的时候,只能预测给定好的词性。
badcase分析:124条错了,然后作者说分析后,除去答案错,答案有歧义,实际105条才是真正错了。并且说它们BERT预测也很低分。等等。他们分析挺细致的。
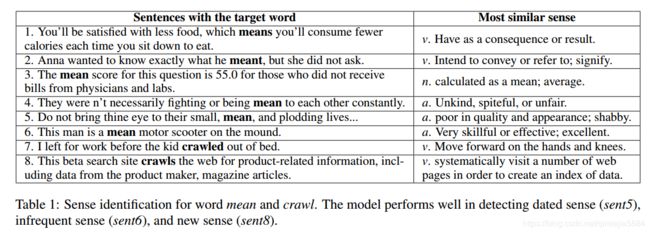
4、例子
下面是 “means”、“crawl”这两个词语例子:
5、个人认为里面讲得不错的
(1)mouse 与 rat 因为都有“老鼠”的意思,而 mouse 与 screen 以为都有“电脑配件”的意思。这是两个不同的解释,却因为 screen,导致 rat 与 screen 拉到一起了。
论文说解决方法是:前人用了Skip-gram + 知识库(即Wordnet),他是使用最新的 BERT + 牛津字典。
(2)作者在分析badcase的时候也提到,因为句子太短了而不能够提供足够的信息,所以从BERT中获得的上下文词向量不可靠。【这里他说是上下文词向量,因为我暂时没理解透彻BERT,所以我怀疑它就是该词语的词向量,并不是上下文词向量的平均之类的,毕竟文章只说了BERT最后一层作为词向量。】
贡献点二:Sense Tracking 解释追踪
1、目的:词语随年代变化,它常用的解释也在变化。
2、公式:比较简单。其实就是解释的使用频率处理词语使用的总频率。
3、方法:先对包含200年数据的COHA语料进行POS词性标注,然后使用作者上面的预测解释的方法,不断地输入到BERT中。后面就是统计,画图了。
4、例子
“please”这个词语的四种解释随使用的使用频率变化【已经区分不同词性】

5、数据集和分数【模型评估】
Gulordava and Baroni (2011)数据集:100个单词,各自的词频不同。5个标注人员,对一个词语在“1960年、1990年”的改变程度进行打离散的4分
Frermann and Lapata (2016)的度量方法大致就是:某个词语的改变程度 = max{ 各个解释在两个不同时间(1960、1990年)的使用比例 }
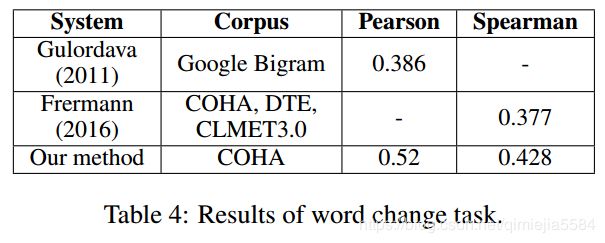
【这个表格我有点疑惑的是:Corpus列,作者没有使用Google Bigram,那么第一行与最后一行的比较就没有意义了,但文中却说比他们都高。可能是作者笔误吧?】
6、个人认为里面讲得不错的
(1)如果对不同年代的语料使用聚类的方法。这时选择的 k 通常是很困难且通常是随意的,很少有工作去解释为什么确定这个k。
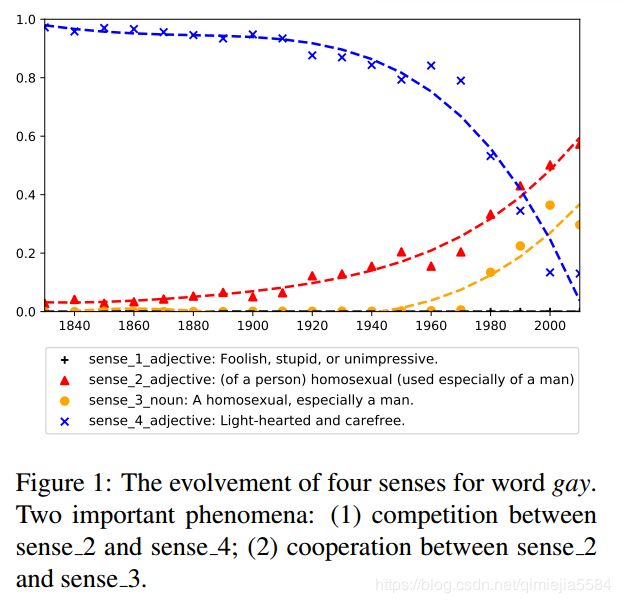
贡献点三:从生态学的角度,观察一个词语里面的语义间的竞争与合作。
1、目的:竞争存在与一个词语内的解释之间。
2、例子
gay 这次词语:解释2(形容词;男同性恋)与解释4(形容词;轻松,无忧无虑)存在竞争关系。解释2与解释3(名词;男同性恋)是合作关系。
(Ivan Vuli´c et al., ACL 2017)morph-fitting:fine-tuning word vector spaces with simple language-specitic rules
- 解决的问题:低频的词语置信度不高,反义词语义相近的问题。
- 数据集: SimLex-999、SimVerb-3500、对话状态跟踪(NLP下游的应用)
- 主要思想:同义词应该进行拉近,反义词就拉远。
- 具体方法:
(1)先使用skip-gram + negative sampling 预生成词向量。
(2)进入三轮阶段: - 第一阶段,同义词拉近:

· 公式的原理:找出最相近的非同义词,同义词的相关程度要比非同义词的更相近。它是损失函数。
· 公式的细节:词向量相乘是可以得到它们的相关程度的。xl-xr是同义词对。tl是xl最相近的非同义词。tr同理。δ的作用是间隔边界作用,是一个常数。B是batch,即小批数据。A是ATTRACT,即同义词起吸引作用。 - 第二阶段:

· 公式的原理:反义词的相关程度要比非反义词的更远。与同义词的原理差不多,只是加号和减号换了一下位置。
· 公式的细节:红色的r个人认为是要变成l的,见另一篇与它最想关的论文。xl-xr是反义词对。tl是xl最远的非反义词。tr同理。R是repel,即反义词起抵制作用。 - 第三阶段:

· 公式的原理:不希望改变初始的词向量程度太大,于是用改变后的词向量与初始的词向量计算L2距离作为损失。
· 公式的细节:init是原始词向量,λ是常系数。