使用Mahout搭建推荐系统之入门篇4-Mahout实战
一、基本内容
二、运行环境
三、程序运行
3.1 调整N值和Threshold值对推荐结果的影响:
public static void main(String[] args) throws Exception {
int userId = 1;
int rankNum = 2;
QingRS qingRS = new QingRS();
for(int neighberNum = 2; neighberNum < 10; neighberNum++) {
System.out.println("neigherNum=" + neighberNum);
qingRS.initRecommenderIntro(filename, neighberNum);
String resultStr = qingRS.getRecommender(userId, rankNum);
System.out.println(resultStr);
}
}Recommend=313 4.5
neigherNum=3
Recommend=286 5.0
neigherNum=4
Recommend=286 5.0
neigherNum=5
Recommend=990 5.0
neigherNum=6
Recommend=990 5.0
neigherNum=7
Recommend=990 5.0
neigherNum=8
Recommend=990 5.0
neigherNum=9
Recommend=990 5.0
解释: neigherhood一开始变化时, 参考的人数增多了, 所谓三个臭皮匠顶过一个诸葛亮, 推荐将会变化, 但是随着neigherhood的变大, 加再多的人进来也只是凑人数而已没有多大的决定能力.
List
rankNum);
但是: 我们发现除了neigherNum = 2以外, 推荐结果均发生了变化, 而且数据开始震荡, 如果将neigherNum放大到30, 推荐结果依旧不停地震荡.
Recommend=313 4.5
neigherNum=3
Recommend=323 5.0
neigherNum=4
Recommend=898 5.0
neigherNum=5
Recommend=323 5.0
neigherNum=6
Recommend=323 5.0
neigherNum=7
Recommend=898 5.0
neigherNum=8
Recommend=326 5.0
neigherNum=9
Recommend=326 5.0
解释???: 问题应该出在排序算法上, Mahout为了节约内存使用了qSort, 因此排序算法不稳定. 但是我去查看Mahout源代码发现GenericUserBasedRecommender中使用了Collections.sort(), sort默认使用的是MergeSort, 所以排序应该是稳定的. 依旧存在着疑问.
3.2. 针对DataModel做一些数据分析,
类似于博文2, 判断item和user数量, value范围, 方差等.
代码如下:
package com.qingfeng.rs.test;
import java.io.File;
import java.io.IOException;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.model.DataModel;
public class QingDataModelTest {
private final static String filename = "data/u.data";
public static void main(String[] args) throws IOException, TasteException {
DataModel dataModel = new FileDataModel(new File(filename));
// compute the max and min value
// 计算最大最小值
float maxValue = dataModel.getMaxPreference();
float minValue = dataModel.getMinPreference();
// compute the number of usersNum and itemsNum
// 计算用户和物品总数
int usersNum = dataModel.getNumUsers();
int itemsNum = dataModel.getNumItems();
int[] itemsNumForUsers = new int[usersNum];
int[] usersNumForItems = new int[itemsNum];
LongPrimitiveIterator userIDs = dataModel.getUserIDs();
int i = 0;
while (userIDs.hasNext()) {
itemsNumForUsers[i++] = dataModel.getPreferencesFromUser(
userIDs.next()).length();
}
assert (i == usersNum);
LongPrimitiveIterator itemIDs = dataModel.getItemIDs();
i = 0;
while (itemIDs.hasNext()) {
usersNumForItems[i++] = dataModel.getPreferencesForItem(
itemIDs.next()).length();
}
assert (i == itemsNum);
// compute mean and variance
// 计算平均值和方差
double usersMean;
double usersVar;
int sum = 0;
int sqSum = 0;
for (int num : itemsNumForUsers) {
sum += num;
sqSum += num * num;
}
usersMean = (double) sum / usersNum;
double userSqMean = (double) sqSum / usersNum;
usersVar = Math.sqrt(userSqMean - usersMean * usersMean);
double itemsMean;
double itemsVar;
sum = 0;
sqSum = 0;
for (int num : usersNumForItems) {
sum += num;
sqSum += num * num;
}
itemsMean = (double) sum / itemsNum;
double itemsSqMean = (double) sqSum / itemsNum;
itemsVar = Math.sqrt(itemsSqMean - itemsMean * itemsMean);
System.out.println("Preference=(" + minValue + ", " + maxValue + ")");
System.out.println("usersNum=" + usersNum + ", userMean=" + usersMean
+ ", userVar=" + usersVar);
System.out.println("itemsNum=" + itemsNum + ", itemsMean=" + itemsMean
+ ", itemsVar=" + itemsVar);
}
}设置门限过滤数据
for (int num : itemsNumForUsers) {
sum += num;
if (num < 20) {
countLower++;
// System.out.println("user warning(" + countLower + ")=" + num);
}
sqSum += num * num;
}
System.out.println("user warning(" + countLower + ")");
for (int num : usersNumForItems) {
sum += num;
if (num < 20) {
countLower++;
//System.out.println("item warning(" + countLower + ")=" + num);
}
sqSum += num * num;
}
System.out.println("item warning(" + countLower + ")");item warning(743)
Preference=(1.0, 5.0)
usersNum=943, userMean=106.04453870625663, userVar=100.87821227051644
itemsNum=1682, itemsMean=59.45303210463734, itemsVar=80.3599467406018
item warning(743) 表示有743个item评分个数小于20.
物品评分较为稀疏程度和物品总数大小是一致的. 使用user-based则用户少,节约内存, 且矩阵致密。
设置门限为20时, 发现物品矩阵稀疏、方差大和过滤器的统计结果item warning(743)大是一致, 此处先不过滤数据, 后期再说.
注:当然优秀的过滤器需要改变门限值来不停的调试
3.3 选择DataModel, 并计算内存使用情况
public class QingMemoryTest {
private static final String filename = "data/u.data";
public static void main(String[] args) throws Exception {
DataModel dataModel = new FileDataModel(new File(filename));
UserSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(5,
similarity, dataModel);
Recommender recommender = new GenericUserBasedRecommender(dataModel,
neighborhood, similarity);
System.out.println("1: jvm free-memory= "
+ Runtime.getRuntime().freeMemory() + "Bytes");
System.gc();
System.out.println("2: jvm free-memory= "
+ Runtime.getRuntime().freeMemory() + "Bytes");
// dataModel被回收, 所以推荐结果错误.
System.out.println(recommender.recommend(1, 2).get(1).getValue());
}
}after dataModel: jvm used-memory= 19.2872314453125MB
after similarity: jvm used-memory= 19.2872314453125MB
after neighborhood: jvm used-memory= 19.58240509033203MB
after recommender: jvm used-memory= 19.58240509033203MB
recommend=340
after recommend first: jvm used-memory= 19.877883911132812MB
after gc: jvm used-memory= 9.829483032226562MB
recommend=340
after recommend second: jvm used-memory= 9.829483032226562MB
分析: 由上述数据可见,gc回收内存后, JVM内存消耗回收了10Mbytes, 与猜测一致.
问题: 回收完数据后, 为什么recommender还可以进行推荐, 而且没有额外的内存开销???
数据增长10倍, 即使用1M数据进行测试
简单统计分析结果:
user warning(0)
item warning(663)
Preference=(1.0, 5.0)
usersNum=6040, userMean=165.5975165562914, userVar=192.73107252940773
itemsNum=3706, itemsMean=269.88909875876953, itemsVar=383.9960197430679
估计内存消耗: usersNum和itemsNum增长了3到6倍, 而相似矩阵消耗内存为平方级别, 那么内存消耗上线为9到36倍; 此外数据增长10倍, DataModel内存消耗为线性增长, 增长10倍内存消耗. 那么估计内存消耗= 2.8M * 10 + (9~36)*8M = 100M ~ 316M内存之间. 如果不存储相似矩阵, 那么内存消耗为28M左右.
由于数据以"::"作为分割符, 用python简单处理一下,替换为\t
f = open("result.dat", "w")
for line in open("ratings.dat", "r"):
newLine = line.replace("::", "\t")
f.write(newLine)运行结果如下
start: jvm used-memory= 0.5967178344726562MB
after dataModel: jvm used-memory= 204.9770050048828MB
after similarity: jvm used-memory= 204.9770050048828MB
after neighborhood: jvm used-memory= 204.9770050048828MB
after recommender: jvm used-memory= 204.9770050048828MB
recommend=2908
after recommend first: jvm used-memory= 208.10643768310547MB
after gc: jvm used-memory= 76.12030029296875MB
recommend=2908
after recommend second: jvm used-memory= 76.12030029296875MB
分析: 由上述数据可以: 数据回收了132Mbytes, 76M为运行开销. 与估计内存消耗移植. DataModel线性增长, 相似矩阵平方级别增长.
结论: 如果评分数增加到10M级别, 用户或者物品数增长3~10倍, 那么需要4G到40G的内存才能快速的计算出推荐结果, 需要增加内存条, 设置JVM配置以及使用hadoop来实现. 另外真实的数据用户数达到GB级别, 总数达到TB级别, 需要的内存数量和运算量是十分恐怖的. 传统地算法已经无法满足要求, 需要借助Hadoop这种分布式来实现运算.
当然内存不够大, 硬盘可以很大, 处理10M级别以上的推荐数据时, 选择使用MysqlJDBCDataModel来实现存储.
另外: 据数盟的一位Q友说, "淘宝有8kw的商品(记忆也许有出入),用户2亿,多大的矩阵啊". 每次想到这里, 都会默默地闭上双眼, 遥想远方的宇宙, 数据又是多么地浩淼. 在上帝眼中, 我们也许还只是玩过家家, 学1+1的小孩子吧.
3.4. 选择相似性矩阵和调参
此外, 后期希望考虑user-based, item-based, slope-one算法的比较, 同时参考运行时间.
相似矩阵选择下面4种
PearsonCorrelationSimilarity EuclideanDistanceSimilarity TanimotoCoefficientSimilarity LogLikeLihoodSimilarity
[注:其中EuclideanDistanceSimilarity比较特殊, 它没有实现UserSimilarity接口, 所以不能放到一个Collection]
[注: 勿看了org.apache.mahout.math.hadoop.similarity.cooccurrence.measures文件]
参数调整只选择近邻N和threashold
这里给出代码原型, 但是在普通PC上跑100K的数据集都太慢了, 使用intro.csv这个toy数据跑一跑.
N选择[2, 4, 8, ... 64], Threshold选择[0.9, 0.85, ... 0.7];
代码如下:
public class QingParaTest {
private final String filename = "data/intro.csv";
private double threshold = 0.95;
private int neighborNum = 2;
private ArrayList userSims;
private final int SIM_NUM = 4;
private final int NEIGHBOR_NUM = 64;
private final double THRESHOLD_LOW = 0.7;
public static void main(String[] args) throws IOException, TasteException {
new QingParaTest().valuate();
}
public QingParaTest() {
super();
this.userSims = new ArrayList();
}
private void valuate() throws IOException, TasteException {
DataModel dataModel = new FileDataModel(new File(filename));
RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();
// populate Similarity
populateUserSims(dataModel);
int simBest = -1;
double scoreBest = 5.0;
int neighborBest = -1;
double thresholdBest = -1;
System.out.println("SIM\tNeighborNum\t\tThreshold\tscore");
for (int i = 0; i < SIM_NUM; i++) {
for (neighborNum = 2; neighborNum <= NEIGHBOR_NUM; neighborNum *= 2) {
for (threshold = 0.75; threshold >= THRESHOLD_LOW; threshold -= 0.05) {
double score = 5.0;
QingRecommenderBuilder qRcommenderBuilder = new QingRecommenderBuilder(
userSims.get(i), neighborNum, threshold);
// Use 70% of the data to train; test using the other 30%.
score = evaluator.evaluate(qRcommenderBuilder, null,
dataModel, 0.7, 1.0);
System.out.println((i + 1) + "\t" + neighborNum + "\t"
+ threshold + "\t" + score);
if (score < scoreBest) {
scoreBest = score;
simBest = i + 1;
neighborBest = neighborNum;
thresholdBest = threshold;
}
}
}
}
System.out.println("The best parameter");
System.out.println(simBest + "\t" + neighborBest + "\t" + thresholdBest
+ "\t" + scoreBest);
}
private void populateUserSims(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = new PearsonCorrelationSimilarity(
dataModel);
userSims.add(userSimilarity);
userSimilarity = new TanimotoCoefficientSimilarity(dataModel);
userSims.add(userSimilarity);
userSimilarity = new LogLikelihoodSimilarity(dataModel);
userSims.add(userSimilarity);
userSimilarity = new EuclideanDistanceSimilarity(dataModel);
userSims.add(userSimilarity);
}
}
class QingRecommenderBuilder implements RecommenderBuilder {
private UserSimilarity userSimilarity;
private int neighborNum;
private double threshold;
public QingRecommenderBuilder(UserSimilarity userSimilarity,
int neighborNum, double threshold) {
super();
this.userSimilarity = userSimilarity;
this.neighborNum = neighborNum;
this.threshold = threshold;
}
@Override
public Recommender buildRecommender(DataModel dataModel)
throws TasteException {
UserNeighborhood neighborhood = new NearestNUserNeighborhood(
neighborNum, threshold, userSimilarity, dataModel);
return new GenericUserBasedRecommender(dataModel, neighborhood,
userSimilarity);
}
}
运行结果如下:
SIM NeighborNum Threshold score
1 2 0.75 0.4858379364013672
1 2 0.7 NaN
1 4 0.75 0.4676065444946289
1 4 0.7 NaN
1 8 0.75 0.8704338073730469
1 8 0.7 0.014162302017211914
1 16 0.75 NaN
1 16 0.7 0.7338032722473145
1 32 0.75 0.7338032722473145
1 32 0.7 0.4858379364013672
1 64 0.75 NaN
1 64 0.7 1.0
The best parameter
1 8 0.7 0.014162302017211914
分析: 运行最佳的结果为N = 8, Threshold = 0.7 当然, 这个方法, 十分的粗糙, 但是也说明了参数的重要性, 毕竟推荐系统上线了必须有优秀的A\B Test结果, 要不然还不如使用打折, 优惠券来的简单实在.
顺便截一张Mahout in Action上一个真实案例的数据, 如下图所示
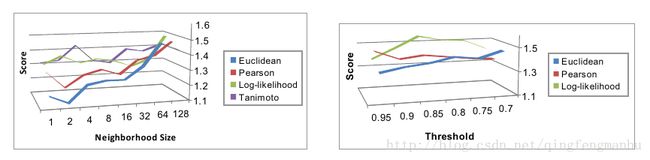
3.5 slope-one
public class SlopeOne {
public static void main(String[] args) throws IOException, TasteException {
DataModel dataModel = new FileDataModel(new File("data/intro.csv"));
RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();
double score = evaluator.evaluate(new SlopeOneNoWeighting(), null,
dataModel, 0.7, 1.0);
System.out.println(score);
}
}
class SlopeOneNoWeighting implements RecommenderBuilder {
public Recommender buildRecommender(DataModel model) throws TasteException {
DiffStorage diffStorage = new MemoryDiffStorage(model,
Weighting.UNWEIGHTED, Long.MAX_VALUE);
return new SlopeOneRecommender(model, Weighting.UNWEIGHTED,
Weighting.UNWEIGHTED, diffStorage);
}
}四、总结
五、Similarity和Algorithm相关总结
| 相似距离(距离越小值越大) |
优点 | 缺点 | 取值范围 |
|
PearsonCorrelation
类似于计算两个矩阵的协方差
|
不受用户评分偏高
或者偏低习惯影响的影响
|
1. 如果两个item相似个数小于2时
无法计算相似距离.
[可以使用item相似个数门限来解决.]
没有考虑两个用户之间的交集大小[使用
weight参数来解决]
2. 无法计算两个完全相同的items
|
[-1, 1] |
|
EuclideanDistanceSimilarity
计算欧氏距离, 使用1/(1+d)
|
使用与评分大小较
重要的场合
|
如果评分不重要则需要归一化,
计算量大
同时每次有数据更新时麻烦
|
[-1, 1] |
|
CosineMeasureSimilarity
计算角度
|
与PearsonCorrelation一致 | [-1, 1] | |
|
SpearmanCorrelationSimilarity
使用ranking来取代评分的
PearsonCorrelation
|
完全依赖评分和完全放弃评分之间的平衡 |
计算rank消耗时间过大
不利于数据更新
|
[-1, 1] |
|
CacheUserSimilarity
保存了一些tag, reference
|
缓存经常查询的user-similarity | 额外的内存开销 | |
|
TanimotoCoefficientSimilarity
统计两个向量的交集占并集的比例
同时并集个数越多, 越相近.
|
适合只有相关性
而没有评分的情况
|
没有考虑评分,信息丢失了 | [-1,1] |
|
LogLikeLihoodSimilarity
是TanimoteCoefficientSimilarity
的一种基于概率论改进
|
计算两者重合的偶然性
考虑了两个item相邻的独特性
|
计算复杂 | [-1,1] |