用Python爬取在线观看的视频
爬取原则
爬虫告诉我们,但凡浏览器可以正常浏览的,都是可以爬取的。
爬取分析
在相对名气响亮的部分视频网站,都提供了相应的下载链接,包括只有会员才能观看的视频;而还有另一部分网站,提供了海量的免费视频,包括其他网站的VIP视频,都可以免费在线观看,可是没有提供下载链接;当然还有一些特殊网站的视频,也是只能观看,不能下载。如果苛求将上述部分下载来做其他用途,那爬取在此时将变得有意义。
链接分析
以Http请求为主的视频链接,目前比较常用的是.ts文件格式,我称为碎片文件。
如图: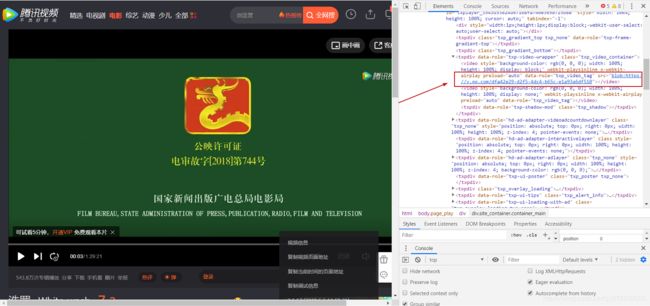
打开层层的源码,发现里面是一个以‘blod’开头的链接,复制链接打开发现并没有任何东西。一些大神解释:此种链接可以比喻为C/C++中的指针,指向真实视频链接,并不断进行迭代,使视频进度迭代式加载。所以,我们正常看到的完整视频,就是一个一个被切割成几秒的视频拼接而成的。
文件被加载的真正位置在,如图:

是XHR中的request Ulr,以ts结尾的链接。
比如:开始链接:https://vip.okokbo.com/20180105/x1CtL9MR/800kb/hls/DQwFVk1919000.ts
浏览器直接访问该链接,将会触发自动下载,如图:

此时一个碎片就下载好了。
分析该链接,发现其实链接是以000.ts结尾的,将进度条拖到末尾发现如图:

结束链接:https://vip.okokbo.com/20180105/x1CtL9MR/800kb/hls/DQwFVk19192000.ts
是2000.ts结尾的。也就是说一部2小时13分钟的电影被切割成了2000个文件。表面上看是这样的,也有可能现在我得到的结果是二次切割得来的。就是说,文件本来有可能只是20个,然后每个又被切割了100次,采生出来2000个文件。比如腾讯视频:如图:

4个指示箭头所指的 花里胡哨的参数,是按照某一算法生成的开始和结束段,在总 区间内,大致切割10秒左右,每次的起始是上次的结束,但是增长区间是随机的毫秒数,范围在10000毫秒左右。
就在我为此而绝望的时候,突然想看看去掉这些花里胡哨的拼接参数是什么样子。然后去掉以?拼接的参数后,惊奇的发现试看5分钟的视频合成了一个完整的文件,一次性就下载了下来。
去掉参数以后,发现这个文件是以321882.1.ts结尾的。忍不住就想试一下,将1.ts改为2.ts会是什么结果,结果也很惊喜,VIP视频的第二个5分钟也被下载了下来。
当我顺势改为3.ts的时候,发生了404请求错误,服务器收到了我的请求,却拒绝响应。
这是对腾讯视频的一次实验,前提是在没有登录的情况下,得到了VIP视频的第二个五分钟。咱也没有钱,咱也没有vip,就到此结束了。毕竟这些大网站,都是允许正规下载的。
上述分析的二次切割的问题,告一段落。说回2000个文件的下载和合成。
下载
url拼接
当我知道了一部电影是2000个文件,并且每个链接都是有规律的。这时候很容易可以拼接出所有的链接。
url_list = []
# 开始链接:https://vip.okokbo.com/20180105/x1CtL9MR/800kb/hls/DQwFVk1919000.ts
# 结束链接:https://vip.okokbo.com/20180105/x1CtL9MR/800kb/hls/DQwFVk19192000.ts
for i in range(2000):# 这个循环结束以后,将获得2000个拼接好的链接列表 为整部电影
# 找到的电影的ts链接
urls = 'https://vip.okokbo.com/20180105/x1CtL9MR/800kb/hls/DQwFVk1919' + '%03d'%(i) + '.ts'
url_list.append(urls)
url分配
2000个文件使用多线程来执行,合理利用资源并加快下载速度,预备开启6个线程。
# 将拼接好的链接地址 分配给所要开启的线程
# 这里可以支持二次续点下载。当第一次没有全部下载完毕时,可以适当调节切片的起点。
url_list1 = url_list[0:400]
url_list2 = url_list[400:800]
url_list3 = url_list[800:1200]
url_list4 = url_list[1200:1500]
url_list5 = url_list[1500:1750]
url_list6 = url_list[1750:2000]
这里可以支持二次续点下载。当第一次没有全部下载完毕时,可以适当调节切片的起点
多线程开启
# 开启线程
# 开启合适的线程个数 接受分配好的任务
th1 = threading.Thread(target=run_thread, args=(url_list1,))
th2 = threading.Thread(target=run_thread, args=(url_list2,))
th3 = threading.Thread(target=run_thread, args=(url_list3,))
th4 = threading.Thread(target=run_thread, args=(url_list4,))
th5 = threading.Thread(target=run_thread, args=(url_list5,))
th6 = threading.Thread(target=run_thread, args=(url_list6,))
# 开启线程
th1.start()
th2.start()
th3.start()
th4.start()
th5.start()
th6.start()
# 线程等待 保证每个线程可以在主线程结束前结束
th1.join()
th2.join()
th3.join()
th4.join()
th5.join()
th6.join()
以selenium为爬取手段
这里我驱动的是谷歌浏览器,其实后续总结,使用无头浏览器更好一些,只需要后台运作,界面不会显得很忙。
def run_thread(url_list):
for url in url_list:
print(url + '开始下载')
# 创建webdriver对象 用来驱动浏览器
driver = webdriver.Chrome('chromedriver.exe')
# ts文件 浏览器访问则自动下载
driver.get(url)
# 一个ts文件的大小约400K,睡眠5秒 保证每个文件可以在5秒的时间内下载完成
time.sleep(3)
# 关闭打开的浏览器
driver.quit()
分析
6个线程,每个线程每次执行3秒,保证每个文件下载完毕。如果网速够快,可以设置为2秒,那么就表示每秒钟可以下载3个文件,大概11分钟的时间可以完成一部电影的下载。
这种方法,局限性太大,对于不同的电影,需要做不同的链接分析。
插入语
对于爬虫的学习,马上也要结束了,可能再没有太多的时间去做深入的研究,后续的机器学习和深度学习才是我所学课程的重点。
从爬取征整站的文字数据,图片数据,到爬取特定的一部电影,也算是简单的做一个结束。爬虫很好玩,可是我要走了。希望后续,在工作中能学到更简洁的爬虫方法。
对于爬虫的scrapy框架,本来也想写一个练习贴,但是scrapy我用的并不好。大部分的网页现在都是js动态加载,我并没有找到框架对于动态链接是怎么的处理方式,希望会有朋友指点。反而selenium加requests在解决这一问题时,用起来很顺手。
合成
将下载好的2000个ts文件,使用ts合成工具合成。一个电影下载流程,就这么笨拙的走完了。
其他格式的视频链接
还有很多网站,诸如校花网上的短视频,链接都是以.mp4结尾的,这种类型的链接,就和下载图片一样简单,直接使用requests库中的request访问,然后写入到本地,不做过多赘述。