文本检测年度2018梳理
论文:Verisimilar Image Synthesis for Accurate Detection and Recognition of Texts in Scenes
论文主要通过人工生成数据的方式来辅助训练,使得最终精度有提升。
制造训练数据的主要改进点:
- 语义一致性,保证所写的字只能在一个语意的目标上,而不能横跨多个语意,比如字只能写在墙壁上,而不是天空。字只能写在本子上,而不是一半写在本子上,一半写在花盆上。
- 视觉显著性,保证所写的字和背景目标可以明显区别。
- 自适应文本颜色亮度,保证所写的字的亮度要明显。

论文使用EAST进行实验,最终结果比原始EAST提升5个点。
论文:Boosting up Scene Text Detectors with Guided CNN
主要贡献:
提出了Guided CNN——two stage 文本检测方法
模型包括两部分:
(1)guidance subnetwork,预测guidance mask用于后续的文本检测
(2)primary text detector,关注text和hard non-text区域

guided convolution:
有点类似dropblock的思想。思路就是在上图的guidance mask后,还在背景区域随机取一些区域加入到mask中,形成最终的区域。就是将guidance mask中黑色的像素变为白色。
论文给出了一个guided convolution的加速实现

就是只对红色的像素做卷积操作。
实验结果:
有近1个点的提升。



论文:Using Object Information for Spotting Text
论文贡献:
文本和带有文本的目标之间是有依赖关系的,文字背后的载体对文字是否出现有很强的相关性和指导性。基于此,提出了Text and Object-based CNN (TO-CNN),即Object VGG-16 + Text VGG-16。
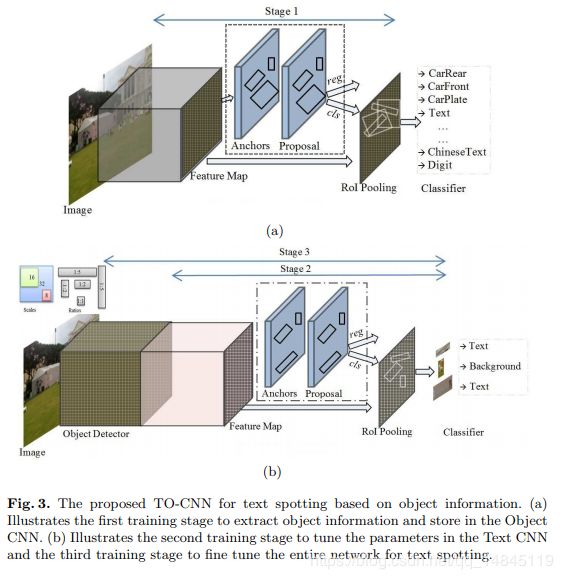
具体就是首先使用vgg基础结构的faster rcnn进行voc21分类或者coco81分类的训练。然后只取基础vgg机构,然后再后面再叠加一个新的vgg一样的结构,再接faster rcnn后续的部分模块。然后对文字检测进行训练。
论文:Single Shot Scene Text Retrieval
Github:https://github.com/lluisgomez/single-shot-str
论文目的,检索包含关键词的图像
主要贡献:
提出了文本编码PHOC (Pyramidal Histogram Of Characters),只适应于英文。

PHOC就是对单词保持原长度(L1),平均分为2份(L2),平均分为3份(L3)......。然后再对每一个份进行one-hot形式的编码。最后再将需要用到的one-hot形式的编码concat起来。
整体结构:

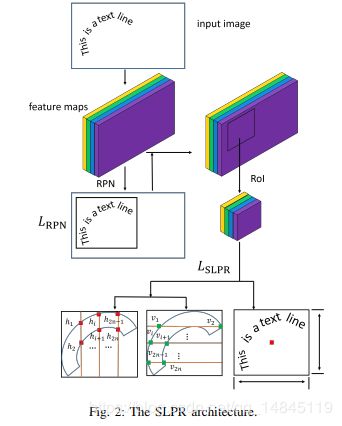
论文:Sliding Line Point Regression for Shape Robust Scene Text Detection
论文贡献:
提出基于滑线点回归(SLPR),优势就是SLPR可以检测任意形状文本
整体框架基于2-stage框架 Faster-Rcnn 或者 RFCN
其中,SLPR水平垂直分别用了7条等距线,对于一个多边形需要预测32个参数,bbox(4) + 文本与水平线交点(14) + 文本与垂直线交点(14)

如上图所示,只有水平或者垂直的14个点还不能确定这个多边形框。还少4个红色的实心点。这4个红色的实心点是对水平或者垂直的14个点进行连线,然后顺延这个连线和外面蓝色的框相交的交点。因此,还需要预测box的4个点。
另外对于水平和垂直的各14个点的后期使用,可以选择使用长边的预测的14个,忽略短边的预测的14个。也可以两个预测求平均使用。
SLPR结构:
实验结果:
整体召回率提升近3个多点。

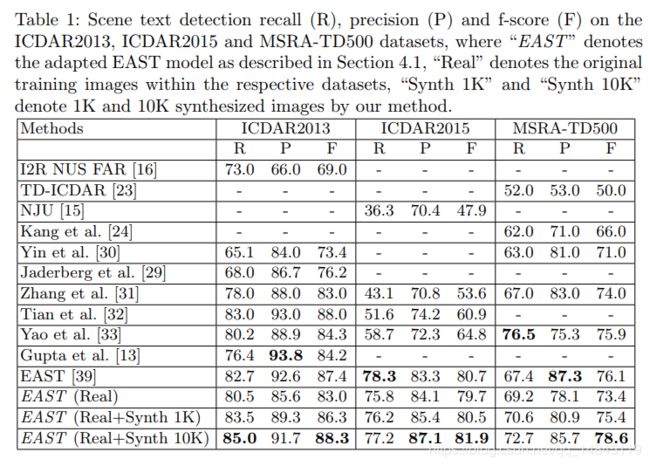
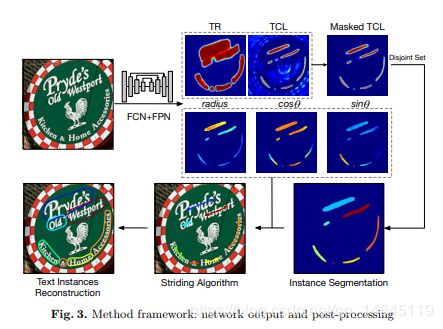
论文:TextSnake A Flexible Representation for Detecting Text of Arbitrary Shapes
论文贡献:
提出一种检测任意形状的文本表示法,TextSnake
文本表示成一个序列,不同半径的重叠圆组成的序列
整体结构:

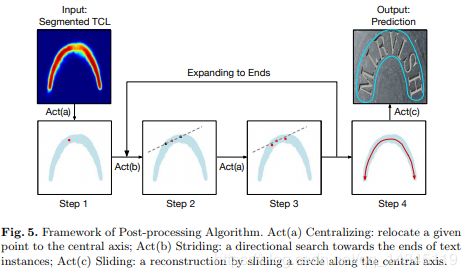
后处理流程:
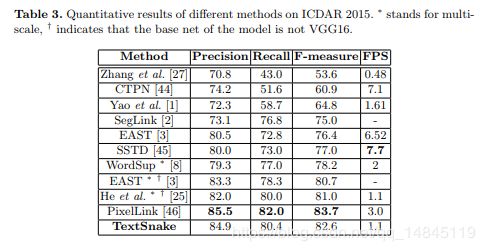
实验结果:
准确性和召回率都很高
论文:Rotation-Sensitive Regression for Oriented Scene Text Detection
Github:https://github.com/MhLiao/RRD
主要贡献:
提出提出旋转敏感回归(RSR)
作者认为分类和回归两个任务是不兼容的,共享基础特征会导致性能下降,所以他提出使用两个独立的网络分支,分别进行分类和回归。旋转不变特征用于分类;方向敏感特征用于回归。

可以看出分类的特征主要集中在框的中间,回归的特征主要集中在框的边界。
整体结构:
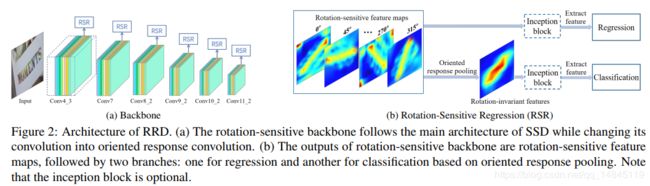
(a)表示网络的基本结构,采用的ssd的结构。
(b) 表示RSR模块的结构,对于回归任务和方向有关系,所以使用所有的rotation-sentitive fearure map。而对于分类任务,对于方向不敏感,所以将所有方向的fearure map做一个基于channl的pooling操作,这样就失去方向信息,然后基于该fearure map进行分类。
这里的旋转feature map操作使用了主动旋转滤波器(ARF),不是对feature map进行旋转,而是对滤波器的核进行旋转。
实验结果:
召回和准确性都有极大的提升。
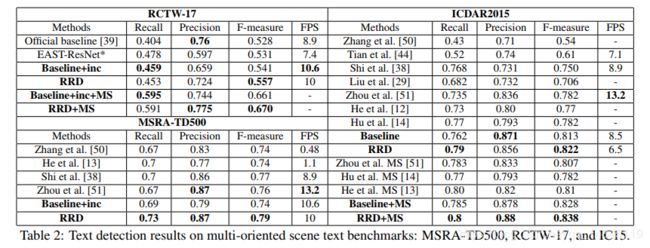
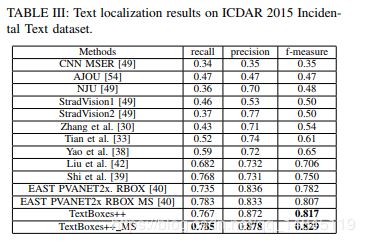
论文:TextBoxes++: A Single-Shot Oriented Scene Text Detector
Github:https://github.com/MhLiao/TextBoxes_plusplus
创新点:
(1)用四边形或者旋转矩形表示文本框
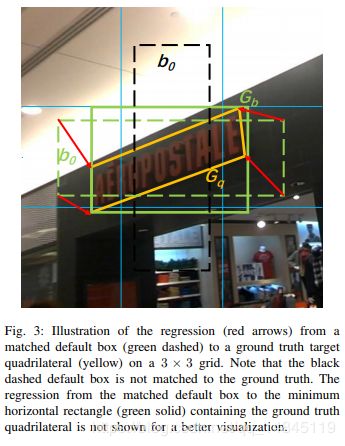
如上图所示,分别预测绿色实线的box和黄色实线的旋转box。
(2)为anchor设置上下偏置,方便预测临近的文本,弥补anchor在坚直方向稀疏的缺点

如上图所示,黑色的虚线框为默认的anchor,但是会存在覆盖不全的情况,因此对anchor设置上下的偏移,再加上黄色的anchor。
(3)修改卷积核, 3*3->3*5
(4)最后接CRNN进行文本识别,反馈给detection网络,refine detection
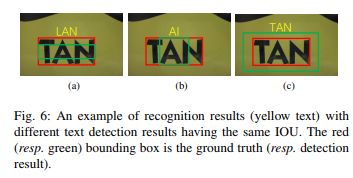
如上图所示,红色表示groundtruth,绿色表示预测的框,使用识别结果对检测进行校正。
(5)6个尺度检测并做nms
整体结构:
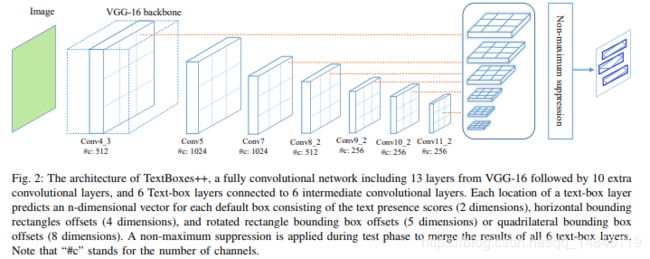
实验结果:
准确性和召回率都有一定提升。
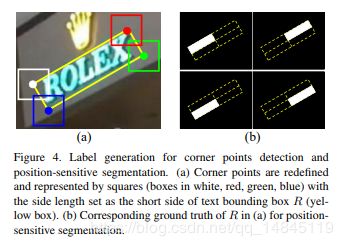
论文:Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
主要贡献:
结合回归和分割的多方向场景文本检测,优势就是可区分重叠文本
- 定位角点,回归的方法预测候选框
- 预测位置感知分割图 position-sensitive segmentation maps,分割的方法筛选候选框
整体结构:
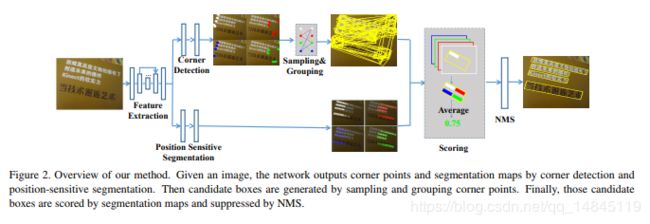
网络分别进行4个角点的回归操作和像素的分割操作。角点的回归分别输出上下左右4个feature map,像素的分割也分别预测上下左右4个部分的分割结果。有点类似openpose,4个点之间会存在好多种组合,通过像素的分割的结果可以过滤掉大部分,剩下的进行NMS,输出最终的文本框。
网络模块:
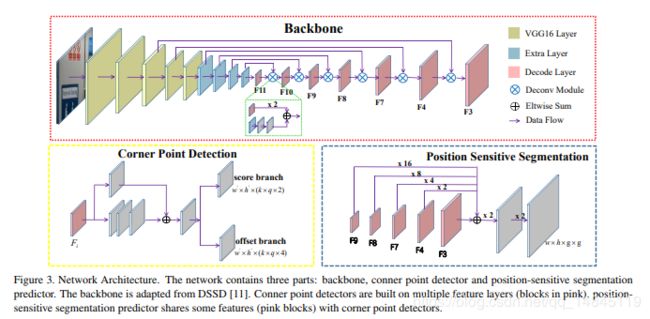
实验结果:
准确性提升比较多,召回一般。
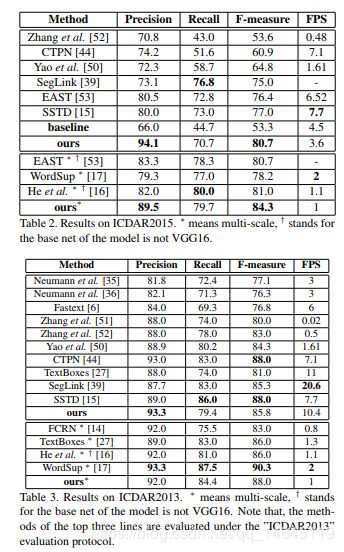
论文:IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection
主要贡献:
(1)Incept模块处理多尺度文本;
(2)Deformable PSROI Pooling模块处理多方向文
网络结构:
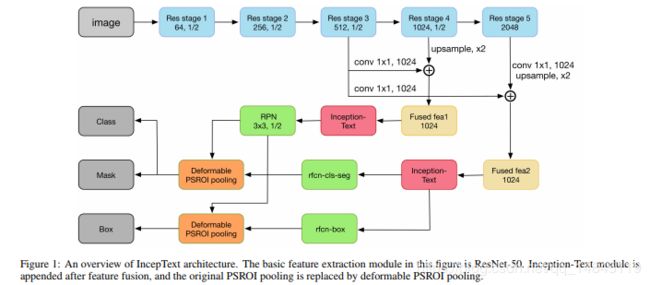
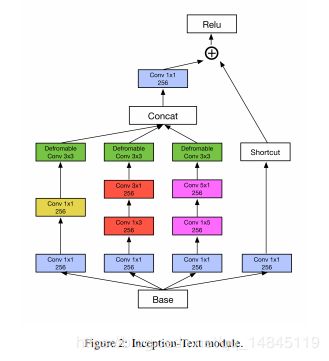
PSROI Pooling:
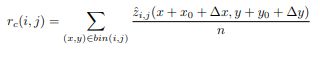
2点改进的有效性证明:
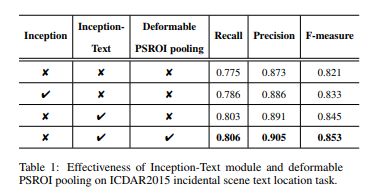
实验结果:
准确性和召回都比较高
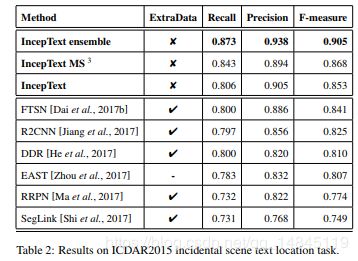
论文:Learning Markov Clustering Networks for Scene Text Detection
主要贡献:
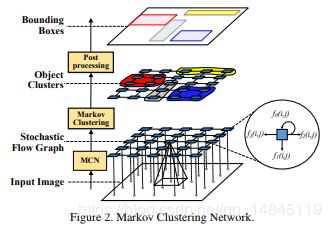
将文本检测问题转化为图聚类问题,图像被表示成网格化的Graph,即随机流图。节点表示为图像上一个等大小的重叠方块区域,边表示相关性。
网络结构:
attractor 设计:

attractor 表示为一个文本实例内的所有节点最终都会收敛到的节点,每个文本实例都有一个attractor。attracotr GroundTruth 制作如上图。
(a)首先取矩形框的长边的中线,该中线会和短边有一个交点,取离该交点最近的点所在的竖线作为最终的竖线。然后使用矩形框最下面的点构成一条虚线,即最终的横线。横线和竖线的交点就是attractor 点P。
(b)矩形框中所有的点都有一条路径可以到达attractor点P
(c)对整个图片,从左下角从0开始从小到大一直写入数据。其次对矩形框进行一定程度的外延,使得矩形框可以覆盖attractor点P,然后使用attractor点P的值71替代框内其他点的值都为71。
(d)将矩形框内的每一个点都表示为一个长度为109的one-hot向量,71处的值为1,其他处为0
整体流程:
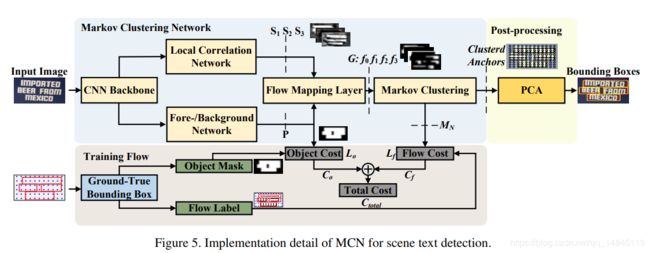
实验结果:
准确性和召回率在不同数据集上有不同表现,整体来看,还是有提升。
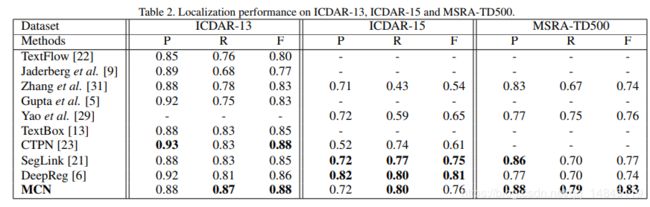
论文:Shape Robust Text Detection with Progressive Scale Expansion Network
Github:https://github.com/whai362/PSENet
基于分割的、多尺度预测的方法。
主要贡献:
- 检测弯曲文本
- 分离靠的很近的文本
- 通过”kernel”来构建完整的文字块

(a)原图
(b)基于anchor的方法
(c)基于分割的方法
(d)本文的PSENet
整体流程:
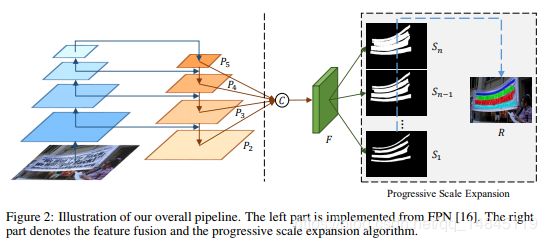
左面为FPN结构,右面为通过预测不同粗细的特征图进行特征融合。从s1,s2......sn,逐渐由细到粗。
尺度扩展:
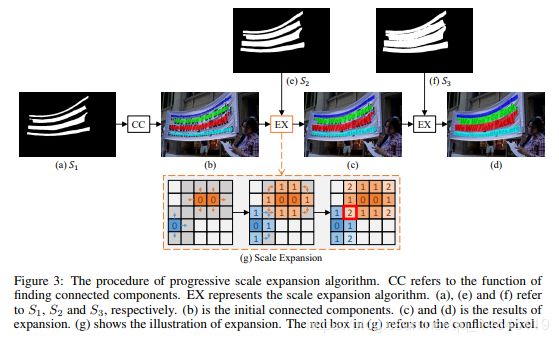
在connected components过程中,逐渐从细的到粗的扩展。每次扩展最外一圈的像素,如果该像素在后面一个feature map上是1,则不做处理,如果是0,则不进行扩展。即从s1到s2扩展,对s1进行最后一层的扩展,如果扩展的像素在s2中被激活,就保持该扩展,如果没被激活,就不扩展该像素。
如果红色的扩展和蓝色的扩展冲突,按照先到先得进行处理。
实验结果:
准确性和召回都挺高。
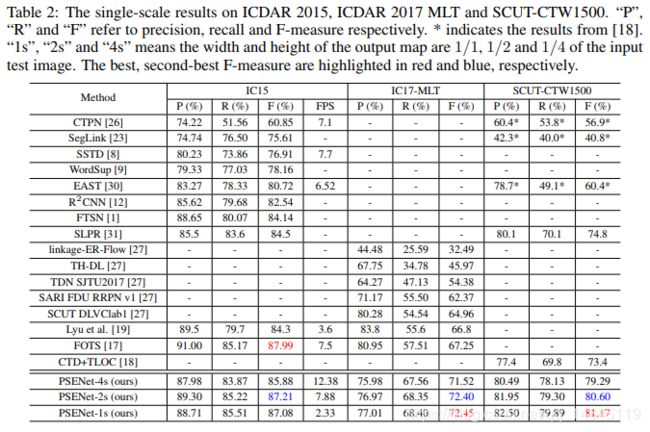
论文:Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
主要贡献:
(1)采用Bootstrapping进行数据扩增

(2)增加border-loss,通过边界语义的引导来准确检测文本,因为边界像素比中间像素更准确回归边框,最终使得相邻文本行更容易区分。和advanced-east的处理很像。

实验结果:
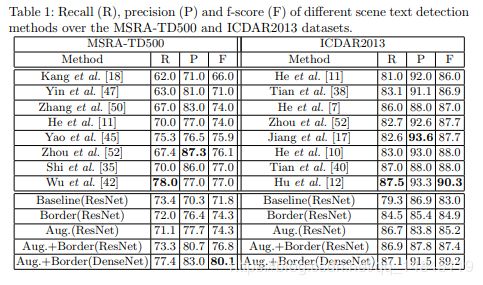
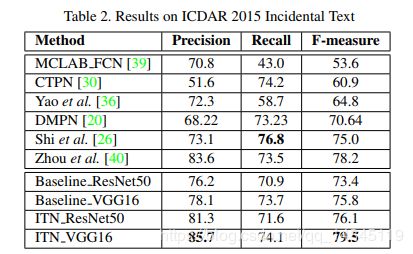
论文:Geometry-Aware Scene Text Detection with Instance Transformation Network
Github:https://github.com/zlmzju/itn
主要贡献:
提出基于几何感知的实例变换ITN,类似STN,STN在整个feature map执行全局的转换,本文instance-level转换,每个文本实例有各自的变换。
固定感受野与自适应感受野的区别:

ITN模块:
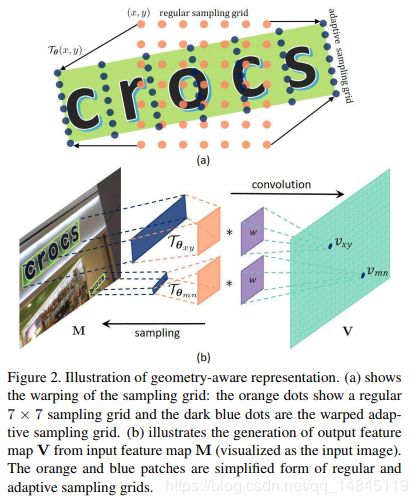
(a)表示进行自适应的采样,有点类似可变形卷积。橙色的点表示正常的采样的grid。蓝色的点表示进行完ITN变换后的采样的点。
(b)表示ITN的具体操作,可以将倾斜的ROI处理为坐标系平行的ROI。
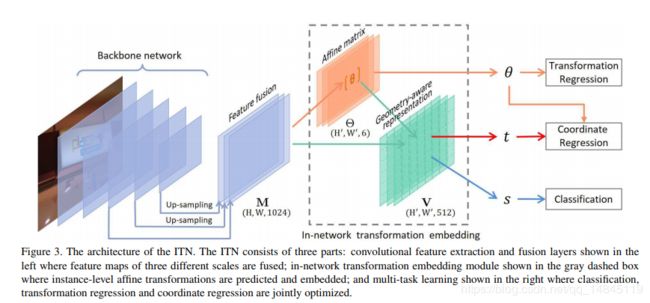
ITN 模块的结构如上图,主要由3个部分组成。
- 蓝色部分,卷积特征提取层和进行一些feature fusion操作。
- 橙色,绿色部分,主要进行仿射变换操作。
- 最右面的部分,主要进行分类和回归操作。
实验结果:
准确性很高,召回率一般