Spark工作原理
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
1.运行速度快,Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
2.适用场景广泛,大数据分析统计,实时数据处理,图计算及机器学习
3.易用性,编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
4.容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
Spark的适用场景
目前大数据处理场景有以下几个类型:
1.复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
2.基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
3.基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
架构及生态
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:
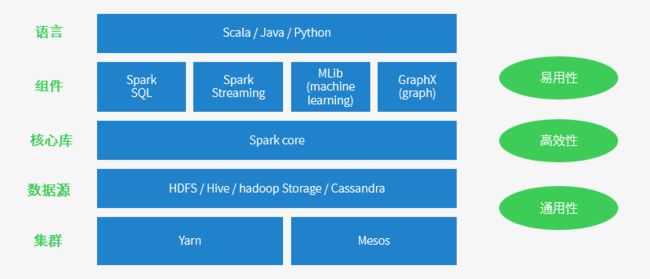
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。Spark提供的sql形式的对接Hive、JDBC、HBase等各种数据渠道的API,用Java开发人员的思想来讲就是面向接口、解耦合,ORMapping、Spring Cloud Stream等都是类似的思想。
Spark Streaming:基于SparkCore实现的可扩展、高吞吐、高可靠性的实时数据流处理。支持从Kafka、Flume等数据源处理后存储到HDFS、DataBase、Dashboard中。对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
Spark的架构设计
Hadoop存在缺陷:
基于磁盘,无论是MapReduce还是YARN都是将数据从磁盘中加载出来,经过DAG,然后重新写回到磁盘中,计算过程的中间数据又需要写入到HDFS的临时文件,这些都使得Hadoop在大数据运算上表现太“慢”,Spark应运而生。
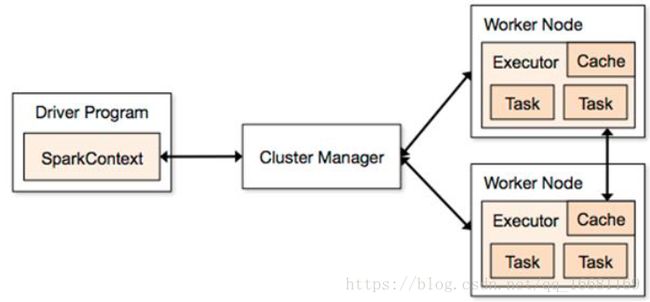
Cluster Manager在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器负责分配资源,有点像YARN中ResourceManager那个角色,大管家握有所有的干活的资源,属于乙方的总包。
WorkerNode是可以干活的节点,听大管家ClusterManager差遣,是真正有资源干活的主。从节点,负责控制计算节点,启动Executor或者Driver。
Executor是在WorkerNode上起的一个进程,相当于一个包工头,负责准备Task环境和执行
Task,负责内存和磁盘的使用。Task是施工项目里的每一个具体的任务。
Driver是统管Task的产生与发送给Executor的,运行Application 的main()函数,是甲方的司令员。
SparkContext是与ClusterManager打交道的,负责给钱申请资源的,是甲方的接口人。
整个互动流程是这样的:
1 甲方来了个项目,创建了SparkContext,SparkContext去找ClusterManager申请资源同时给出报价,需要多少CPU和内存等资源。ClusterManager去找WorkerNode并启动Excutor,并介绍Excutor给Driver认识。
2 Driver根据施工图拆分一批批的Task,将Task送给Executor去执行。
3 Executor接收到Task后准备Task运行时依赖并执行,并将执行结果返回给Driver
4 Driver会根据返回回来的Task状态不断的指挥下一步工作,直到所有Task执行结束。
运行流程及特点

1.构建Spark Application的运行环境,启动SparkContext
2.SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
3.Executor向SparkContext申请Task
4.SparkContext将应用程序分发给Executor
5.SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
6.Task在Executor上运行,运行完释放所有资源
Spark运行特点:
1.每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
2.Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了
提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换
Task采用了数据本地性和推测执行的优化机制
Spark任务调度模块DAGScheduler、TaskScheduler:
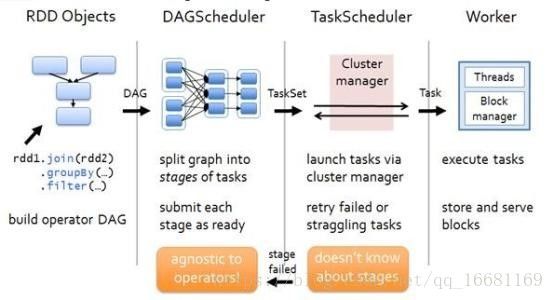
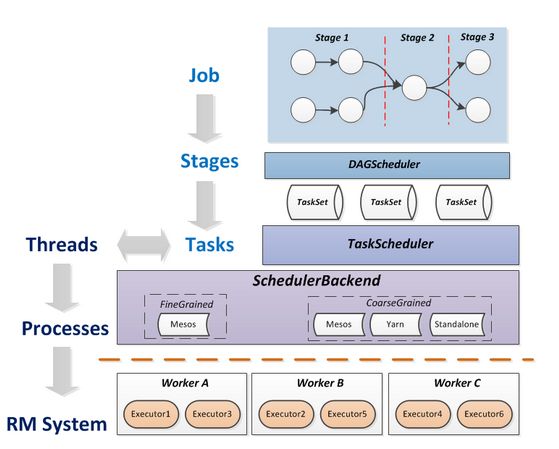
用户编排的代码由一个个的RDD Objects组成,DAGScheduler负责根据RDD的宽依赖拆分DAG为一个个的Stage,买个Stage包含一组逻辑完全相同的可以并发执行的Task。TaskScheduler负责将Task推送给从ClusterManager那里获取到的Worker启动的Executor。
DAGScheduler(统一化的,Spark说了算):
详细的案例分析下如何进行Stage划分,请看下图
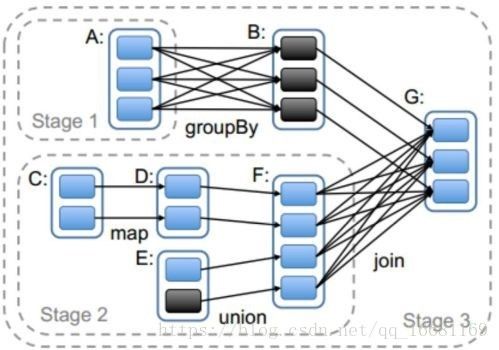
1 stage是触发action的时候从后往前划分的,所以本图要从RDD_G开始划分。
2 RDD_G依赖于RDD_B和RDD_F,随机决定先判断哪一个依赖,但是对于结果无影响。
3 RDD_B与RDD_G属于窄依赖,所以他们属于同一个stage,RDD_B与老爹RDD_A之间是宽依赖的关系,所以他们不能划分在一起,所以RDD_A自己是一个stage1
4 RDD_F与RDD_G是属于宽依赖,他们不能划分在一起,所以最后一个stage的范围也就限定了,RDD_B和RDD_G组成了Stage3
5 RDD_F与两个爹RDD_D、RDD_E之间是窄依赖关系,RDD_D与爹RDD_C之间也是窄依赖关系,所以他们都属于同一个stage2
6 执行过程中stage1和stage2相互之间没有前后关系所以可以并行执行,相应的每个stage内部各个partition对应的task也并行执行
7 stage3依赖stage1和stage2执行结果的partition,只有等前两个stage执行结束后才可以启动stage3.
8 我们前面有介绍过Spark的Task有两种:ShuffleMapTask和ResultTask,其中后者在DAG最后一个阶段推送给Executor,其余所有阶段推送的都是ShuffleMapTask。在这个案例中stage1和stage2中产生的都是ShuffleMapTask,在stage3中产生的ResultTask。
9 虽然stage的划分是从后往前计算划分的,但是依赖逻辑判断等结束后真正创建stage是从前往后的。也就是说如果从stage的ID作为标识的话,先需要执行的stage的ID要小于后需要执行的ID。就本案例来说,stage1和stage2的ID要小于stage3,至于stage1和stage2的ID谁大谁小是随机的,是由前面第2步决定的。
虽然理论上Task应该交给workerNode上的executor来执行的,但是有一种情况下是是在DAG划分结束后直接在本地执行的。
1 Spark.localExecution.enabled设置为true;
2 用户显示指定允许本地执行;
3 整个DAG只有一个stage;
4 仅有一个Partition。
同时满足上面4个条件下,可以直接在SparkContext(Driver)节点上本地执行。
TaskScheduler(接口化的,根据不同的部署方式Standalone、Mesos、YARN、Local):

每个TaskScheduler对应着一个帮手SchedulerBackend,SchedulerBackend负责与ClusterManager交互获得资源,然后将这些资源信息传给TaskScheduler,TaskScheduler负责监督Task的执行状态并进行相应的调度。这里主要做的工作有:就近原则、失败重试、慢任务推测性执行
任务调度的时候默认是FIFO(先到先得)的,由jobID和stageID的大小来决定;也可以配置成FAIR(公平)的,重新确定调度顺序推送task给Executor。
Executor执行完Task后会通过向Driver发送StatusUpdate的消息来通知Driver任务更新Task的状态。Driver会将Task状态通知转告给TaskSchedule,后者会重新分配计算任务。
假如Task有执行失败的,根据失败原因和阈值进行该Task的重试或者放弃。
假如所有Task执行成功,如果Task是ResultTask,那么任务结束;如果是ShuffleMapTask那么启动下一个stage。
Spark运行模式:
Local模式:
比较简单,只适用于自己玩和测试,甲方SparkContext乙方Executor等都部署在一起,物理位置上角色定位不明确。
Mesos模式:

Worker部分采用Master/Slaver模式,Master是整个系统的核心部件所以用ZooKeeper做高可用性加固,Slaver真正创建Executor执行Task并将自己的物理计算资源汇报给Master,Master负责将slavers的资源按照策略分配给Framework。
Mesos资源调度分为粗粒度和细粒度两种方式:
粗粒度方式是启动时直接向Master申请执行全部Task的资源,并等所有计算任务结束后才释放资源;细粒度方式是根据Task需要的资源不停的申请和归还。两个方式各有利弊,粗粒度的优点是调度成本小,但是会因木桶效应造成资源长期被霸占;细粒度没有木桶效应,但是调度上的管理成本较高。
YARN模式:

YRAN模式下分为Cluster和Client两种模式,上图中的为Cluster模式。
Cluster模式下就是将Spark作为一个普通的YARN任务,Client端通过ResourceManager申请到资源,创建ApplicationMaster、Task到Container中去。ApplicationMaster负责监督Task的执行情况。
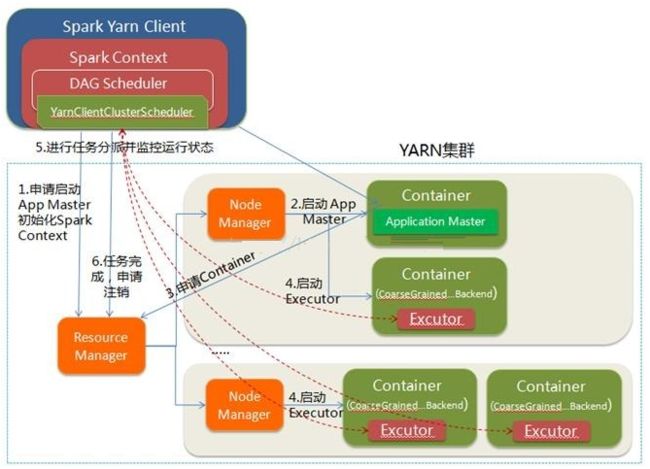
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问
YARN-client的工作流程步骤为:
Spark Cluster模式:
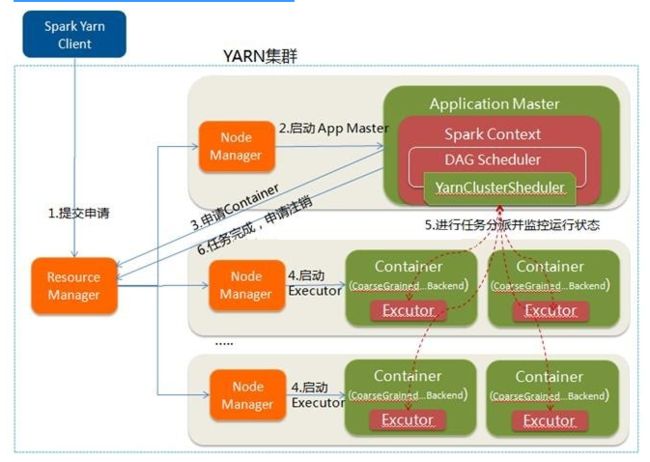
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
YARN-cluster的工作流程分为以下几个步骤
Spark Client 和 Spark Cluster的区别:
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开
Standalone(也叫Deploy)模式:
与Mesos模式有点像,也是Master/Slavers的架构。Standalone模式使用Spark自带的资源调度框架,选用ZooKeeper来实现Master的HA
框架结构图如下:
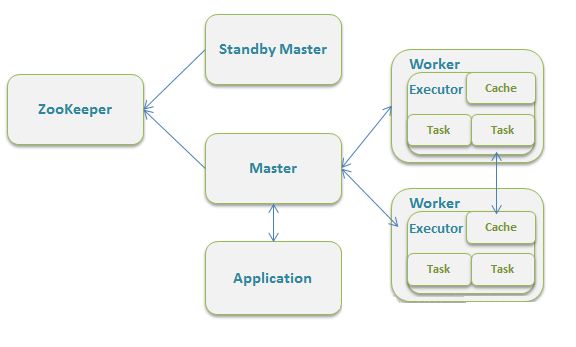
该模式主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的
运行过程如下图
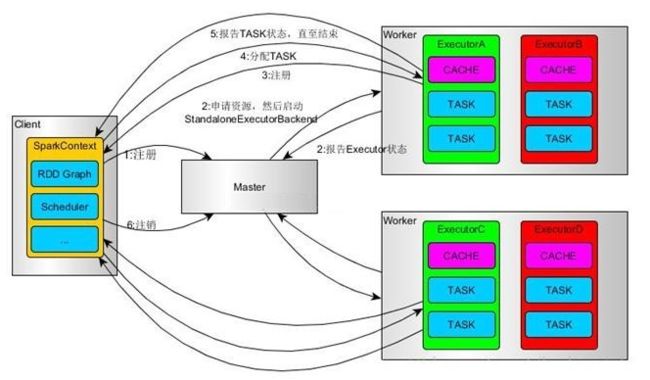
1.SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)
2.Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
StandaloneExecutorBackend向SparkContext注册;
3.SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
4.StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成
5.所有Task完成后,SparkContext向Master注销,释放资源
Spark的容错处理
请注意这里使用的是容错而不是容灾,因为这俩不是一个概念。
容灾是洪水、火灾、地震等导致的灾难性的毁灭性的故障,是非常小概率的事件,需要做数据级别甚至应用级别的异地备份;而容错是解决由于网络阻塞、磁盘损坏、内存溢出、机器掉电等引起的单点故障或者模块化的故障,是每时每刻都有可能发生的大概率事件。
所以说容错和容灾不是一个级别的,我们对架构拓扑稍作优化通过很小的成本就可以达到容错的效果;但是要想达到容灾那将是巨大的开销而且很难存在一个100%容灾的设计,例如地球被炸了难道还要将数据在外太空做定期备份么~~
前面介绍模式的时候我们一再强调,Master是核心部件,是心脏和大脑,所以Master的故障是我们不能接受的,所以需要通过Zookeeper来做高可用性(虽然也有fileSystem模式但是自从我做过的一个产品真的出现磁盘损坏导致单点故障然后连续加班了40多小时候以后我再也不相信硬件了)。一旦Leader的Master挂掉,其它Master会自主推优出新的Leader。新的Leader会从ZooKeeper中读取所有元数据并通知到大家(Worker、Client)自己登基上位。
Worker节点众多,出现故障的概率最高,workers定时的向Master上报心跳,一旦超时Master将对它进行卸磨杀驴。Master会将worker上所有Executor设置为失效并通知给Client,Client会通知SchedulerBackend如果有该worker上的executor正在执行你的task请重新调度。Master通知完以后会尝试kill掉该坏掉的worker。
Worker节点上运行着很多executor进程,如果worker心跳没问题但是某个executor进程出线了问题怎么办?这个概率比worker出现异常的概率更大!其实worker节点除了明着干活的executor,还有监督executor的executorRunner,它会将executor退出的信息告知自己所在的worker,worker在通知自己的master,剩下的就是跟上面一样的套路了。
Executor详解:
Executor干了两件事情:运行Task和将结果反馈给Driver。。
Master在给Application分配Worker时有两种方式:尽量打散和尽量集中。
尽量打散适用于内存密集型,尽量集中适用于CPU密集型。
1个物理节点可以部署多个Worker,但是一个Worker中对于1个Application只能有1个Executor。
关于Executor的内存设置:
Executor是执行Task的真正苦力,内存设置的过小,会导致内存溢出或者频繁GC影响效率;内存设置过大会导致占用过多资源(内存资源从价格上和槽道数量上来讲还是比较珍贵的)。所以合理的设置Executor内存是Spark处理任务的关键。Executor支持的任务的数量取决于持有的CPU的核数,所以一种思路是如果集群普遍的CPU核数够多但是内存紧张,可以采用更多的分区来增加Task的个数减少单个Task执行对内存的要求。
Executor最终将Task的执行结果反馈给Driver,会根据大小采用不同的策略:
1 如果大于MaxResultSize,默认1G,直接丢弃;
2 如果“较大”,大于配置的frameSize(默认10M),以taksId为key存入BlockManager
3 else,全部吐给Driver。
Shuffle详解:
Hash Base Shuffle(spark1.2以前默认):
下图是将4个Partition洗牌成3个Partition的案例,假设当前是StageA,下一个是StageB
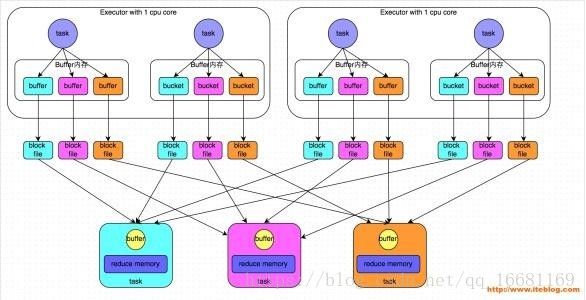
在洗牌过程中StageA每个当前的Task会把自己的Partition按照stageB中Partition的要求做Hash产生stageB中task数量的Partition(这里特别强调是每个stageA的task),这样就会有len(stageA.task)*len(stageB.task)这么多的小file在中间过程产生,如果要缓存RDD结果还需要维护到内存,下个stageB需要merge这些file又涉及到网络的开销和离散文件的读取,所以说超过一定规模的任务用Hash Base模式是非常吃硬件的。
尽管后来Spark版本推出了Consolidate对基于Hash的模式做了优化,但是只能在一定程度上减少block file的数量,没有根本解决上面的缺陷。
Sort Base Shuffle(spark1.2开始默认):
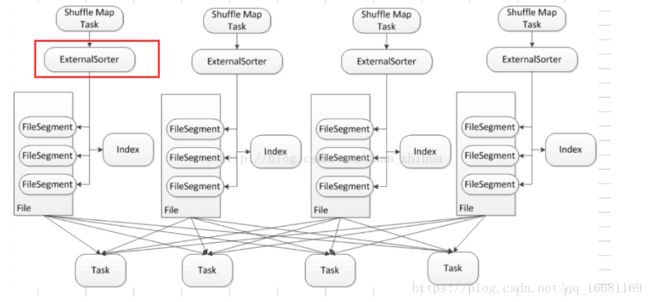
Sort模式下StageA每个Task会产生2个文件:内容文件和索引文件。内容文件是根据StageB中Partition的要求自己先sort好并生成一个大文件;索引文件是对内容文件的辅助说明,里面维护了不同的子partition之间的分界,配合StageB的Task来提取信息。这样中间过程产生文件的数量由len(stageA.task)*len(stageB.task)减少到2* len(stageB.task),StageB对内容文件的读取也是顺序的。Sort带来的另一个好处是,一个大文件对比与分散的小文件更方便压缩和解压,通过压缩可以减少网络IO的消耗。(PS:但是压缩和解压的过程吃CPU,所以要合理评估)
Sort和Hash模式通过spark.shuffle.manager来配置的。
Storage模块:
存储介质:内存、磁盘、Tachyon(这货是个分布式内存文件,与Redis不一样,Redis是分布式内存数据库),存储级别就是它们单独或者相互组合,再配合一些容错、序列化等策略。例如内存+磁盘。
负责存储的组件是BlockManager,在Master(Dirver)端和Slaver(Executor)端都有BlockManager,分工不同。Slaver端的将自己的BlockManager注册给Master,负责真正block;Master端的只负责管理和调度。
Storage模块运行时内存默认占Executor分配内存的60%,所以合理的分配Executor内存和选择合适的存储级别需要平衡下Spark的性能和稳定。
RDD(Resilient Distributed Datasets) 弹性分布式数据集
RDD支持两种操作:转换(transiformation)和动作(action)
转换就是将现有的数据集创建出新的数据集,像Map;动作就是对数据集进行计算并将结果返回给Driver,像Reduce。
RDD中转换是惰性的,只有当动作出现时才会做真正运行。这样设计可以让Spark更见有效的运行,因为我们只需要把动作要的结果送给Driver就可以了而不是整个巨大的中间数据集。
缓存技术(不仅限内存,还可以是磁盘、分布式组件等)是Spark构建迭代式算法和快速交互式查询的关键,当持久化一个RDD后每个节点都会把计算分片结果保存在缓存中,并对此数据集进行的其它动作(action)中重用,这就会使后续的动作(action)变得跟迅速(经验值10倍)。例如RDD0àRDD1àRDD2,执行结束后RDD1和RDD2的结果已经在内存中了,此时如果又来RDD0àRDD1àRDD3,就可以只计算最后一步了。
RDD之间的宽依赖和窄依赖:
窄依赖:父RDD的每个Partition只被子RDD的一个Partition使用。
宽依赖:父RDD的每个Partition会被子RDD的多个Partition使用。
宽和窄可以理解为裤腰带,裤腰带扎的紧下半身管的严所以只有一个儿子;裤腰带帮的比较宽松下半身管的不禁会搞出一堆私生子,这样就记住了。
对于窄依赖的RDD,可以用一个计算单元来处理父子partition的,并且这些Partition相互独立可以并行执行;对于宽依赖完全相反。
在故障回复时窄依赖表现的效率更高,儿子坏了可以通过重算爹来得到儿子,反正就这一个儿子当爹的恢复效率就是100%。但是对于宽依赖效率就很低了,如下图:
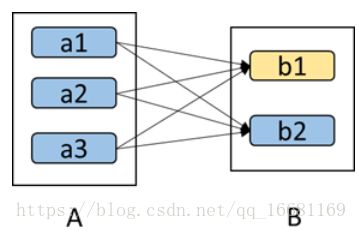
如果儿子b1坏了a1、a2、a3三个当爹的都运算了一次恢复了b1,但是其实它们的运算同时也会覆盖一遍b2这个无辜的儿子,有效率只有50%。
代码实现上窄依赖NarrowDependency有2种:OneToOneDependency和RangeDependency
宽依赖只有1种ShuffleDependency,但是内部参数ShuffleManager有Hash和Sort两种,后面会详细介绍Hash和Sork的区别。
有了以上RDD宽窄依赖和父子之间的血缘关系,我们就可以绘制DAG:
绘制原则就是由于宽依赖的“断点”效应,根据宽依赖将整个DAG分为不同的阶段(Stage),每个Stage之间有先后关系从前向后进行,在每个Stage内部窄依赖RDD是并行执行的。
Stage的划分是从最后一个RDD从后往前进行的。
注意:转化和动作只是决定惰性执行的时机,宽窄依赖才是划分Stage的唯一标准。ReduceByKey是转化,但它包含ShuffleDependency,所以转化和动作与宽窄依赖没关,不要混淆。
RDD的计算:
Spark的Task有两种:ShuffleMapTask和ResultTask,其中后者在DAG最后一个阶段推送给Executor,其余所有阶段推送的都是ShuffleMapTask。
Executor在准备好Task运行环境后会调用scheduler.Task#run,scheduler.Task#run会调用ShuffleMapTask或ResultTask的runTask,runTask会调用RDD的#iterator,每个RDD真正的计算逻辑实现在RDD的computer方法中。用户创建SparkContext时会创建SparkEnv负责管理所有运行环境的信息,最核心的是cacheManager。
CheckPoint:
CheckPoint是对RDD缓存不足被擦写等中间block断丢失导致重新计算这一缺点的弥补,CheckPoint会启动一个job来计算并将计算结果写入磁盘中,最后修改原始RDD的依赖为当前CheckPoint。当缓存没有命中时先来看CheckPoint中有没有记录,再决定是否重新计算。CheckPoint是RDD磁盘缓存的一种表现,稳定性更高,但是IO更慢。
Spark与hadoop:
- Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
- spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS
- Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富
- 关系图如下: