自己常用的Python正则表达式
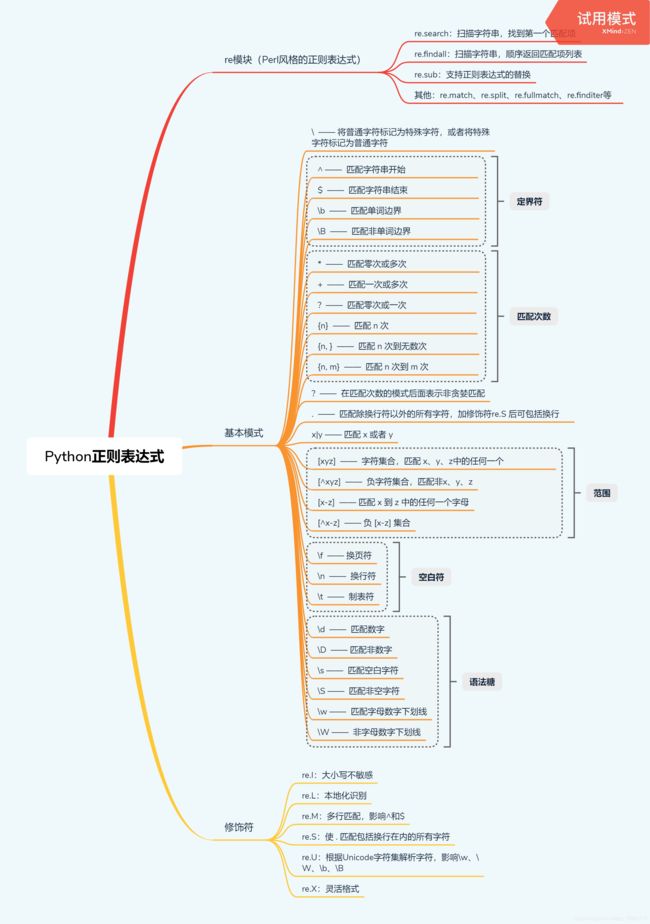
修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
import re
str = 'xH\nhow are you'
y0 = re.search(r'xh.*', str) # 匹配不到任何字符串
y1 = re.search(r'xh.*', str, re.I) # 匹配到 'xH'
y2 = re.search(r'xh.*', str, re.I|re.S) # 匹配到整个 str
贪婪匹配与非贪婪匹配
正则表达式默认匹配所有可能中最长的那一个,即所谓的贪婪匹配,非贪婪匹配则是匹配最短的那一个。
在表匹配次数的模式后面加一个’?’,就变成非贪婪匹配。
import re
str = 'xyz'
y0 = re.search(r'\w+', str) # +代表匹配一个或多个,这里str长3,匹配到最长的字符串 'xyz'
y1 = re.search(r'\w+?', str) # 非贪婪模式,匹配到符合要求的最短的字符串 'x'
re.search及分组匹配
匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re
str = 'xyz'
y0 = re.search(r'\w+', str).group() # y0 = 'xyz'
y1 = re.search(r'(\w)(\w)(\w)', str) # 加上特殊字符---括号:分组匹配
# y1.group() = y1.group(0) = 'xyz'
# y1.group(1) = 'x'
# y1.group(2) = 'y'
# y1.group(3) = 'z'
# y1.span() = (0, 3)
# y1.span(1) = (0, 1)
# y1.span(2) = (1, 2)
# y1.span(3) = (2, 3)
re.sub替换
re.sub允许使用函数对匹配项的替换进行复杂的处理。
import re
str = 'x1234z' # 要替换 str 中前后的字母为 a 和 b ,但保留中间的数字
y = re.sub(r'(\w)(\d+)(\w)', lambda m: 'a' + m.group(2) + 'b', str)
print(y) # 'a1234b'
链接
1. Python re模块
2. 菜鸟教程正则表达式
3. 博客Python re模块
4. 网易云课堂:看文档学爬虫——Python正则表达式
.
.
.
.
.
.
.