shell学习笔记整理
Shell编程学习笔记
第一章基础知识
1.脚本格式:
1.1“#!”
这个符号的名称,叫做”Shebang”或者”Sha-bang” “解释伴随行”的简称
1.2执行脚本方式:
./ bash sh source(不开启子进程)
1.3脚本可执行权限:
chmod +x
1.4查看子进程:
pstree 注:挂载yum源安装 yum -y install psmisc
1.5补充
1.51yum相关命令
yum repolist 看有多少包
yum clean all 清理缓存
yum list 列表展示
yum info 显示详细信息
yum search 查找
yum install 安装
remove | erase 卸载
1.5.2挂载阿里源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
将yum下载的安装包保存到本地
修改yum的配置文件,它的位置:/etc/yum.conf该文件有两个重要参数
keepcache=1 改为真(1)将网络yum源使用过的软件包保存下来
cachedir=/var/cache/yum/$basearch/$releasever 保存在这个位置根据系统版本和包的源可能有所不同
1.5.3 wget
1.命令格式:
wget [参数] [URL地址]
2.命令参数
2.1启动参数
-V, –version 显示wget的版本后退出
-b, –background 启动后转入后台执行
-e, –execute=COMMAND 执行`.wgetrc’格式的命令,wgetrc格式参见/etc/wgetrc或~/.wgetrc
2.2记录和输入文件参数
-o, –output-file=FILE 把记录写到FILE文件中
-a, –append-output=FILE 把记录追加到FILE文件中
-d, –debug 打印调试输出
-q, –quiet 安静模式(没有输出)
-i, –input-file=FILE 下载在FILE文件中出现的URLs
2.3下载参数
–bind-address=ADDRESS 指定本地使用地址(主机名或IP,当本地有多个IP或名字时使用)
-c, –continue 接着下载没下载完的文件
-N, –timestamping 不要重新下载文件除非比本地文件新
-Q, –quota=NUMBER 设置下载的容量限制
–limit-rate=RATE 限定下载输率
2.4目录参数
-nd –no-directories 不创建目录
-x, –force-directories 强制创建目录
-nH, –no-host-directories 不创建主机目录
-P, –directory-prefix=PREFIX 将文件保存到目录 PREFIX/…
–cut-dirs=NUMBER 忽略 NUMBER层远程目录
2.5实例
1.使用wget -O下载并以不同的文件名保存
命令:
wget -O wordpress.zip URL
2.使用wget –limit -rate限速下载
wget --limit-rate=300k URL
3.使用wget -c断点续传
4. 使用wget -b后台下载
使用以下命令来察看下载进度:
tail -f wget-log
5. 使用wget -i下载多个文件
wget -i filelist.txt
首先,保存一份下载链接文件
cat > filelist.txt
url1
url2
接着使用这个文件和参数-i下载
1.5.4tput
tput命令参数介绍:
用户可以使用shell的tput命令创建交互性的、专业性强的屏幕输出,如移动或更改光标、更改文本属性,以及清除终端屏幕的特定区域。
系统上需要一个彩色监视器和tput命令。tput使用文件/etc/terminfo或/etc/termcap,这样就可以在脚本中使用终端支持的大部分命令了。
在使用tput前需要使用tput命令初始化终端:
$ tput init
tput产生三种不同的输出:字符型、数字型和布尔型(真/假)。
tput civis :用来隐藏光标
tput cols :显示当前所在的列
tput lines :显示当前所在的行
tput cup lines cols : 将光标移动到第lines行,第cols列
tput setb no :设置终端背景色。 no的取值稍后介绍
tput setf no : 设置文本的颜色。no的取值稍后介绍
tput ed :删除当前光标到行尾的内容
no的取值:0:黑色、1:蓝色、2:绿色、3:青色、4:红色、5:洋红色、6:黄色、7:白色
tput clear # 清屏
tput sc # 保存当前光标位置
tput cup 10 13 # 将光标移动到 row col
tput civis # 光标不可见
tput cnorm # 光标可见
tput rc # 显示输出
常用参数:
(1)字符串输出参数设置
bel 警铃
blink 闪烁模式
bold 粗体
civis 隐藏光标
clear 清屏
cnorm 不隐藏光标
cup 移动光标到屏幕位置(x,y)
el 清除到行尾
ell 清除到行首
smso 启动突出模式
rmso 停止突出模式
smul 开始下划线模式
rmul 结束下划线模式
sc 保存当前光标位置
rc 恢复光标到最后保存位置
sgr0 正常屏幕
rev 逆转视图
(2)数字输出参数设置
cols 列数目
ittab 设置宽度
lines 屏幕行数
(3)布尔输出参数设置
chts 光标不可见
hs 具有状态行
1.5.5date
%H :小时(0..23)%I : 小时(01..12)
%M : 分钟(0..59)
%p : 显示本地时段“上午”或 “下午”
%r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数
%S : 秒(00..61)
%X : 相当于 %H:%M:%S
%a : 星期几 (Mon..Sun) %A : 星期几 (Monday..Sunday)
%b : 月份 (Jan..Dec) %B : 月份 (January..December)
%c : 直接显示日期与时间
%d : 日 (01..31) %D : 直接显示日期 (mm/dd/yy)
%j : 一年中的第几天 (001..366)
%m : 月份 (01..12)
%x : 直接显示日期 (mm/dd/yy)
%y : 年份的最后两位数字 (00.99) %Y : 完整年份 (0000..9999)
2.数据的输入输出print、echo、read
2.1 echo
echo -e 定义字体颜色,背景颜色,定位光标等
echo -n 不换行输出
echo -en \\033[91m 设置背景色并换行
表1-1 常见的转义符
| 符号 |
功能描述 |
| \b |
退格 |
| \f |
换行但光标停留在原来的位置 |
| \n |
换行且光标移至首位 |
| \r |
光标移至行首但不换行 |
| \t |
TAB键 |
| \\ |
打印\ |
| \033或\e |
设置字体颜色,背景颜色,定位光标等 |
•\e[0m 将颜色重新置回
文字色颜色码:重置=0,黑色=30,红色=31,绿色=32,黄色=33,蓝色=34,洋红=35,青色=36,白色=37
echo -e "\e[1;31mThis is red text\e[0m"
背景色颜色码:重置=0,黑色=40,红色=41,绿色=42,黄色=43,蓝色=44,洋红=45,青色=46,白色=47
echo -e "\e[1;42mGreed Background\e[0m"
文字闪动:0 关闭所有属性、1 设置高亮度(加粗)、4 下划线、5 闪烁、7 反显、8 消隐
echo -e "\033[32;5mMySQL Server Stop...\033[32;0m"
2.2 print
| 格式字符 |
功能描述 |
| %d |
十进制的整数 |
| %u |
无符号整数 |
| %ld |
长整数 |
| %s |
字符串 |
| %c |
字符 |
| %g |
不包含0的浮点 |
| %f |
浮点数 |
| %x |
十六进制的整数 |
| %o |
八进制的整数 |
printf "%x\n" 12 输出12的16进制
2.3 read
read [选项] [变量名]
-p 提示语句,后面接输入提示信息,这里为'Enter Password: ' 若需要从管道取数据作为密码需要 --stdin
-n 参数个数,有时候要限制密码长度,或者其他输入长度限制,比如[Y/N],只输入输入一位,-n1
-s 屏蔽回显,屏幕上不显示输入内容,一般用于密码输入
-t 等待时间,这里设置30秒,30秒内未输入或者输入不全,终止
-d 输入界限,这里是$,输入到$,自然终止输入
-r 屏蔽特殊字符\的转译功能,加了之后作为普通字符处理
who 查看用户登录信息
wc 统计行 who| wc –l
ss 查看系统中所有服务监听的端口 ss –nutpl
2.4输出的重定向
标准输出文件描述为1(1可以不写默认为1),标准错误输出描述为2,标准输入文件描述为0
>>或>符号将输出信息重定向到文件中.如果文件不存在,默认创建,使用>如果存在会覆盖,>>会在文件尾添加。
&>符号可以同时将标准输出和错误都重定向到一个文件(&>>追加)。
2>&1将错误输出重定向到标准正确输出
1>&2将标准正确输出重定向到错误输出
/dev/null特殊设备,无论写入多少都会被系统丢弃
2.5输入重定向
<< EOF EOF 输入重定向
自动分区脚本
fdisk /dev/vdb << EOF
n
p
1
wq
EOF
mkfs.xfs /dev/vdb1
[ ! –d /data] && mkdir /data
cat >> /etc/fstab << EOF
/dev/vdb1 /data xfs defaults 0 0
EOF
mount –a
<<- 可以忽略TAB键
3.各种引号
3.1单引号和双引号
touch a b c 创建3个文件 touch “a b c ”一个文件空格是文件的一部分,双引号是引用一个整体,单引号也可以引用一个整体,同时单引号还可以屏蔽特殊字符(echo ‘\#$’)
echo # 输出空白行echo$$显示当前进程号 echo & 后台进程 echo *当前目录下所以文件
3.2 反引号是一个命令替换符号
tar –czf /root/log-`date+%Y+%m+%d`,tar.gz /var/log/ 按日期备份
tar –czf x.tar.gz `ls /etc/*.conf` 将/etc/下以conf结尾的文件压缩为一个文件
反引号不支持嵌套
$()组合符号支持嵌套
4变量
4.1系统预设变量
| 变量名 |
描述 |
|
变量名 |
描述 |
| UID |
当前账户ID |
|
$! |
最后一个后台进程的进程号 |
| USER |
当前账户名称 |
|
$0 |
当前命令名称($1,$0等位置变量) |
| HISTSIZE |
当前终端最大历史记录条数 |
|
$n |
位置参数$1第一个位置数字大于9使用${n} |
| HOME |
当前用户根目录 |
|
$# |
命令参数个数 |
| LANG |
当前语言环境 |
|
$* |
命令行所有参数,作为一个整体 |
| PATH |
命令搜索路径 |
|
$@ |
命令行所有参数,作为独立个体 |
| PWD |
返回当前工作目录 |
|
$? |
上一条命令退出状态(0正确,非零失败) |
| RANGOM |
随机返回0-32767整数 |
|
$$ |
当前进程进程号 |
4.2 自定义变量
变量名=变量值 变量名仅使用字母,数字和下划线组合且不能数字开头
读取变量名时使用$,当变量名与非变量名混在一起使用{}分隔
取消变量定义使用unset删除变量名
4.2.1 tr命令
echo ”aa bb” | tr -c “a” 2 “aa222”2 替换,要求字符集为ASCII
echo ”aa bb” | tr -d “a” “bb” 删除
echo ”aa bb” | tr –s “a” “a bb” 去重
cat file | tr [a-z] [A-Z] > new_file 小写转大写
cat file | tr [A-Z] [a-z] > new_file 大写转小写
cat file | tr [0-9] [a-j] > new_file 把文件中的数字0-9替换为a-j
cat file | tr “abc” “xyz” > new_file 将文件file中出现的”abc”替换为”xyz” 【注意】这里,凡是在file中出现的”a”字母,都替换成”x”字母
cat file | tr -d “\n\t” > new_file 删除文件file中出现的换行’\n’、制表’\t’字符
cat file | tr -s “\n” > new_file 删除空行
echo $PATH | tr -s “:” “\n” 把路径变量中的冒号”:”,替换成换行符”\n”
4.2.2 cut命令
不支持正则表达式
截取第三个字符: cut -c3
截取第三到第六之间的字符: cut -c3-6
截取前三个字符: cut -c-3
提取第三个及其后面的所有字符 cut -c3-
提取第三到第六和第八到第十间的字符 cut -c3-6,8-10
对于-d选项需要配合着-f选项使用,-d是用来指定分隔符,-f用来指定提取第几个域的内容
5.数据过滤与正则表达式
5.1 grep
grep [选项] 匹配模式 [文件]
编号 参数 解释
1 --version or -V grep的版本
2 -A 数字N 找到所有的匹配行,并显示匹配行后N行
3 -B 数字N 找到所有的匹配行,并显示匹配行前面N行
4 -b 显示匹配到的字符在文件中的偏移地址
5 -c 显示有多少行被匹配到
6 --color 把匹配到的字符用颜色显示出来
7 -e 可以使用多个正则表达式
8 -f FILEA FILEB FILEA在FILEAB中的匹配
9 -i 不区分大小写针对单个字符
10 -m 数字N 最多匹配N个后停止
11 -n 打印行号
12 -o 只打印出匹配到的字符
13 -R 搜索子目录
14 -v 取反匹配
15 -q 静默匹配结果不在屏幕上显示
16 -w 匹配单词
| 代码/语法 |
说明 |
| * |
重复零次或更多次 |
| + |
重复一次或更多次 |
| ? |
重复零次或一次 |
| {n} |
重复n次 |
| {n,} |
重复n次或更多次 |
| {n,m} |
重复n到m次 |
5.2基本正则表达式与扩展正则表达式
常用元字符
| 代码 |
说明 |
| . |
匹配除换行符以外的任意字符 |
| \w |
匹配字母或数字或下划线 |
| \s |
匹配任意的空白符 |
| \d |
匹配数字 |
| \b |
匹配单词的开始或结束 |
| ^ |
匹配字符串的开始 |
| $ |
匹配字符串的结束 |
常用反义词 GNU规范
| 代码/语法 |
说明 |
| \W |
匹配任意不是字母,数字,下划线,汉字的字符 |
| \S |
匹配任意不是空白符的字符 |
| \D |
匹配任意非数字的字符 |
| \B |
匹配不是单词开头或结束的位置 |
| [^x] |
匹配除了x以外的任意字符 |
| [^aeiou] |
匹配除了aeiou这几个字母以外的任意字符 |
grep ":..0:" 查找:与0:之间包含2个字符的字符串
grep "00:" 查找至少含一个0的字符串
grep "o[os]t" 查找包含oot或ost
grep "^root" 以root开头 grep "bash$"以bash结束
grep "sbin/[^n]" sbin/后面不跟n的行
grep " ^$" 过滤空白行 grep –v "^$" 过滤非空白行
grep "\(root\).*\1" 查找2个root间任意字符行
grep " i\b" i结尾的单词
grep默认不支持扩展,需要使用grep –E或egrep
POSIX字符类
| 正则表达式 |
描述 |
| [:alnum:] |
字母与数字字符 |
| [:alpha:] |
字母字符(包括大写字母与小写字母) |
| [:blank:] |
空格与制表符(TAB) |
| [:digit:] |
数字字符 |
| [:lower:] |
小写字母 |
| [:upper:] |
大写字母 |
| [:punct:] |
标点符号 |
| [:space:] |
包括换行符、回车等在内的所有空白字符 |
| [:graph:] |
非空格字符 |
| [:print:] |
任意可以显示的字符 |
| [:xdigit:] |
十六进制数字字符 |
6.算术运算
6.1运算符号
$((表达式)) $[表达式] let表达式 无法执行小数运算, bc命令执行小数运算
| 运算符号 |
意义(*标示常用) |
| +,- |
加法,减法 |
| *,/,% |
乘法,除法,取余 |
| ** |
幂运算 |
| ++,– |
自增加,自减少 |
| <,<=,>,>= |
比较符号 |
| =,+=,-=,*=,/=,%= |
赋值运算,例如a+=1相当于a=a+1 |
| 运算操作与运算命令 |
含义 |
| (()) |
用与整数运算 |
| let |
用与整数运算,与(())类似 |
| expr |
用于整数运算,功能相对较多 |
| bc |
linux下的计算器,适合整数及小数运算 |
| $[] |
用户整数运算 |
6.2案例
案例1
for ((i=1;i<10;i++))
do
((j+=i)) #j执行10次自加一
echo $j
done
案例2
bc < 7.7+4.2 EOF 案例3 倒计时 #!/bin/bash read -p "请输入倒计时分钟数和秒数: " m s for ((A=60*${m}+${s};A>0;A--)) do M=$[A/60] S=$[A%60] echo -n "倒计时$M分$S秒" echo -ne "\r" sleep 1 done 案例4 echo % [x>y?2:3] 如果x大于y,返回3 第二章智能脚本 1.1 基础测试 ; 按顺序执行,退出码以最后命令为准 && 仅当前一条命令成功才执行&&后的命令 || A命令||B命令 A命令一定执行,A成功不执行B,A失败执行B,有任何一个返回码为0,整个命令返回码都为0 1.2 字符串的判断与比较 test a == b ; echo $? test a != b ; echo $? 退出码0为正确,非0为错误 [ $USER == root ] && echo Y || echo N -z 测试字符串是否为空 [ -z "$Test" ] && echo Y || echo N 为空输出Y -n测试字符串是否不为空 [ -n "$Test" ] && echo Y || echo N 为空输出N 1.3 整数的判断与比较 符号 含义 -eq 等于(equal) -ne 不等于(not equal) -gt 大于(greater than) -ge 大于等于(greater or equal) -lt 小于(less than) -le 小于等于(less or eaual) [ $UID -eq 0] && echo Y || echo N 判断用户是否为root grep Available /proc/meminfo | egrep -0 "[0-9]+" 当前系统内存剩余可以容量 1.4文件属性判断与比较 操作符 功能描述 -e 判断目录或文件是否存在,存在返回为真 -f 判断目录是否为普通文件 -d 判断存在且为目录 -b 判断存在且为块目录(磁盘,u盘等) -c 判断存在且字符设备(键盘,鼠标等) -L 判断是否为软连接 -p 判断存在且为命名管道 -r/-w/-x 判断当前用户对该文件具有可读/可写/可执行权限 -s 判断存在且大小非空 file1 –ef file2 2文件使用相同设备,相同设备号则返回真 file –nt file2 文件1比文件2新,或者文件1存在而文件2不存在返回真 File –ot file2 文件1比文件2旧,或者文件2存在而文件1不存在返回真 [ -b /dev/sda ] && echo 存在 || echo 不存在 软连接:源文件被删除,软连接无法使用,可以跨分区和磁盘创建 ln –s /源文件 /软连接地址 硬链接:源文件不影响硬链接,单不可以跨分区与磁盘创建 ln /源文件 /软连接地址 1.5[[]]与[]的区别 多数情况下是通用的,test和[]是符合POSIX标准的,兼容性更强几乎可以运行在所有的shell解释器中,而[[]]仅仅运行在特定的几个解释器(Bash,Zsh等) 区别:[[]]使用符号<和>时,是进行排序操作且支持表达式使用&&和||,==模式匹配 test和[]不允许使用,=可以使用 –a表示&& -o表示||,不支持正则,==字符匹配 ASCII码顺序:小写字母>大写字母>数字顺序码 Bash常用通配符:* ? […] 1.6案例 1.6.1系统性能监控 local_time=$( date +"%Y%m%d %H:%M:%S") #网卡ens33的IP local_ip=$(ifconfig ens33 | grep netmask | tr -s " " | cut -d " " -f3) #剩余内存大小 free_mem=$(free -hl | grep Mem | tr -s " " | cut -d " " -f 7) free_disk=$(df -h | grep "/$" | tr -s " " | cut -d " " -f4) #cpu15min平均负载 cpu_load=$(cat /proc/loadavg | cut -d " " -f3) login_user=$(who | wc -l) user_name=$(whoani) procs=$(ps aux | wc -l) #vmstat命令查看系统中CPU中断数 #中断 irq=$(vmstat 1 2 | tail -n +4 | tr -s ' ' | cut -d " " -f12) #上下文切换 cs=$(vmstat 1 2 | tail -n +4 | tr -s ' ' | cut -d " " -f13) #用户态 usertime=$(vmstat 1 2 | tail -n +4 | tr -s ' ' | cut -d " " -f14) #系统态 systime=$(vmstat 1 2 | tail -n +4 | tr -s ' ' | cut -d " " -f15) #i/o等待时 iowait=$(vmstat 1 2 | tail -n +4 | tr -s ' ' | cut -d " " -f17) tail -n +2 删除标题。从第二行还是显示 1.6.2vmstat简介 如果vmstat和iostat命令在你的系统中不可用,请安装sysstat软件包 vmstat,sar和iostat命令都包含在sysstat(系统监控工具)软件包中。iostat命令生成CPU和所有设备的统计信息。 procs --------------------memory---------- ---------swap-- -----------io--------- -system-- ----------cpu----- r b swpd free inact active si so bi bo in cs us sy id wa st 0 0 0 124748 1302916 251104 0 0 0 5 14 12 0 0 100 0 0 proc: r:可运行进程的数量(正在运行或等待运行时)。 b:不间断睡眠中的进程数。 memory: swpd:使用的虚拟内存量。 free:空闲内存量。 buff:用作缓冲区的内存量。 cache:用作缓存的内存量。 inact:非活动内存量。 (-a选项) active:活动内存量。 (-a选项) io: bi:从块设备接收的块(块/ s)。 bo:发送到块设备的块(块/ s)。 system: in:每秒的中断数,包括时钟。 cs:每秒上下文切换次数。 CPU上下文切换:现在linux是大多基于抢占式,CPU给每个任务一定的服务时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这个过程叫做上下文切换。时间片轮转的方式,使得多个任务利用一个CPU执行成为可能,但是保存现场和加载现场,也带来了性能消耗 CPU: us:运行非内核代码所花费的时间。 (用户时间,包括美好时光) sy:运行内核代码所花费的时间。 (系统时间) id:空闲时间。 在Linux 2.5.41之前,这包括IO等待时间。 wa:等待IO的时间。 在Linux 2.5.41之前,包含在空闲状态。 st:从虚拟机中窃取的时间。 在Linux 2.6.11之前,未知。 1.6.3单分支if语句 语法: if 条件测试 ;then 命令 fi yum groupinstall "X Window System" 安装图形界面 init 5 1.6.4双分支if语句 语法: if 条件测试 ;then 命令 else 命令 fi [ $? –eq 0 ] 判断上条命令返回结果 [[ $UID -ne 0 ]] 判断是否是root登录 命令 &>/dev/null 命令的输出结果重定向到/dev/null 1.6.5监控HTTP服务状态 1.namp:网络探测和端口扫描工具 语法: namp 选项 扫描目标列表 支持以主机和网段扫描 namp常用选项 选项 功能描述 -sP 执行ping扫描, -sT TCP扫描,不安全,慢 -sS TCP半开扫描,使用最频繁,安全,快 -sU UDP扫描,可得到有价值的服务器程序 -n 禁止DNS反向扫描(默认会对扫描对象进行反向扫描) -p 指定需要扫描的特定端口号 -Pn 目标机禁用ping,绕过ping扫描 -sA 检测哪些端口被屏蔽 nmap *.*.*.1/24 对整个网段的主机进行扫描 nmap *.*.*.* -oX myscan.xml 对扫描结果另存在myscan.xml -f 使用小数据包发送,避免被识别出 --source-port 针对防火墙只允许的源端口 1.1扩展:SYN扫描也称半开连接 发送带有SYN标志位的数据包进行端口检测,如果主机回复SYN/ACK包,表示该端口处于开放状态,若回复RST/ACK包,表示该端口处于关闭状态,如果未响应或发送了ICMP unreachable信息则表明这个端口被屏蔽了。 SYN/ACK————————>开放 RST/ACK————————>关闭 ICMP unreachable————>屏蔽 优点:由于没有进行TCP三次握手连接,所以安全性(隐蔽性)高,扫描速度快,(注在有权限的情况下nmap默认使用的是该选项进行扫描(-sS))。 1.6.6 RANGOM 变量值范围:0~31767 对10求模运算:0~9 生产随机10以内数:num=$[RANDOM%10+1] 1.6.7磁盘分区 1. Linux主分区、扩展分区、逻辑分区 磁盘的分区大致可以分为三类,分别为主分区、扩展分区和逻辑分区等等 Linux系统中,每个磁盘中有一部分叫做MBR主引导记录 MBR: 大小512字节,分为三部分 主引导程序:446字节 硬盘分区表:64字节 分区结束标记(硬盘有效位):2字节 分区表DPT需要特别注意 DPT的大小是64字节,每个主分区要占用16字节,扩展分区也要占用16个字节的主分区空间,所以每个磁盘上最多只能建立四个主分区 为了突破这最多四个主分区的限制,Linux系统引入了扩展分区的概念。即管理员可以把其中一个主分区设置为扩展分区(注意只能够使用一个扩展分区)来进行扩充。而在扩充分区下,又可以建立多个逻辑分区。也就是说,扩展分区是无法直接使用的,必须在细分成逻辑分区才可以用来存储数据。通常情况下,逻辑分区的起始位置及结束位置记录在每个逻辑分区的第一个扇区,这也叫做扩展分区表。在扩展分区下,系统管理员可以根据实际情况建立多个逻辑分区,将一个扩展分区划割成多个区域来使用 在上图中,四个主分区记录区仅使用其中两个,P2通过扩展分区,分配出五个逻辑分区。 扩展分配的目的是使用额外的磁区来记录分割信息,扩展分配本身并不能被拿来格式化。 其在Linux系统中文件名如下: P1: /dev/hda1 P2: /dev/hda2 L1: /dev/hda5 L2: /dev/hda6 L3: /dev/hda7 L4: /dev/hda8 L5: /dev/hda9 其中没有出现/dev/hda3与/dev/hda4,是因为前面四个数字保留给主分区/扩展分区使用。 2.磁盘分区工具fdisk和parted 区别 1、fdisk (1)fdisk命令只支持msdos,分区的时候只支持小容量硬盘(<=2T),但是如果不需要分区的话,那么整块sdb硬盘,类型为msdos,那么他的大小是可以大于2T的。 (2)fdisk命令不支持gpt,所以当使用fdisk命令给gpt类型硬盘分区是会出现告警 (3)当使用parted命令给一个5T的硬盘分好三个分区之后,在使用fdisk命令查看,会不兼容(parted打印的分区有三个,而fdisk命令打印的分区只有一个) 2、parted: (1)支持msdos和gpt,可以支持大硬盘,也支持小硬盘。 (2)区分parted命令给msdos类型和gpt类型硬盘分区的不同: 与支持最大卷为2TB并且每个磁盘最多有4个主分区(或3个主分区,1个扩展分区)的MBR磁盘分区样式相比,GPT磁盘分区样式支持最大卷128EB并且每磁盘的分区数没有上限,只受到操作系统限制。另外,GPT分区磁盘有备份分区表来提高分区数据结构的完整性。 下面是parted给msdos类型硬盘分区 下面是parted给gpt类型硬盘分区: 3、msdos 支持小于2T的硬盘,不支持大于2T的硬盘 有主分区,扩展分区,逻辑分区 如果使用fdisk命令给一个大于2T的msdos类型硬盘分区,只能给2T的部分分区,超过2T的部分不能使用,也就浪费了。 4、gpt 支持大小容量的硬盘 不区分主分区,扩展分区,逻辑分区,也没有4个分区数量的限制 1.6.8显示前10个占用空间最大的文件或目录 du -sh * | sort -nr | head 查找大于100M的文件 find . -type f -size +1000000k 当前目录的大小: du -sh . 当前目录下个文件或目录的大小: du -sh * 1、查找根目录下,文件大小大于1G的文件,并显示大小。 find / -size +1G | xargs du -sh 2、查找当前路径下,文件名包含“Hello”的所有文件。 find ./ -name "*Hello*" 3、查找当前路径下,文件内容中包含“Hello”字段的所有文件名,并输出行号。 grep -rn "Hello" ./ 4、grep pattern1|pattern2 files:显示匹配 pattern1 或 pattern2 的行; 5、grep pattern1 files|grep pattern2:显示既匹配 pattern1 又匹配 pattern2 的行; 6、find命令的时间参数: -mtime -n +n :按照文件的更改时间来查找文件,-n表示文件更改时间距现在n天以内,+n表示文件更改时间距现在n天以前。 find命令还有-atime(读取时间)和-ctime(权限和属性更改的时间)选项,但它们都和-mtime 选项用法相同。 例如:查找当前路径下,文件大小大于100M,并且2天内更新过的文件,显示出来 find ./ -size +10M -and -mtime -2 例如:查找当前路径下,文件大小大于100M,并且2天前更新过的文件,显示出来 ? 匹配当个字符 *匹配任意字符 […]匹配括号中单个字符,使用-可以表示连续的字符;还支持POSIX localetcl status 查看字符集 localetcl list-locales | grep en 查看字符集列表 localectl set-locale "LANG=zh_CN.UTF-8" 设置语言字符集 localectl set-locale "LANG=en_US.utf-8" 设置语言字符集 执行 locale -a | grep zh_CN* 查看当前系统是否有中文语言包 若没有 zh_CN.utf-8,就安装下: 查看所有控制变量 -s 变量名 激活指定的控制变量 -u 变量名 禁用 extglob 变量开启可以支持扩展通配符 ? 匹配0次或1次 + 匹配至少一次 * 匹配0次或多次 @ 仅匹配1次 ! 匹配指定模式之外的所有内容 第三章 循环与中断 for 语法: for name [ in [word…]] do 命令 done 1. seq与{}自动生成数字序列 1.1 {} echo {1..5} 生成1~5 echo {5..1} 生成5~1 echo {1..10..2} 生成1 3 5 7 9 echo {a..z} 生成字母 echo {x,y{I,j}{1,2,3},z} 生成 x yI1 yI2 yI3 yj1 yj2 yj3 z 1.2seq 可以调用其他命令,但是不支持生成字母。默认分隔符为\n,可以使用-s自定义 seq 1 5 生成1~5 seq -s '' 1 5 空格为分隔符 seq -s ' ' 2 2 10 2 4 6 8 10 不指定开始,默认从1开始 i=5 j=6 seq –s ' ' $i $j 2.ping ping 命令发送一个因特网控制报文协议 (ICMP) ECHO_REQUEST 去从主机或网关那里获得 ICMP ECHO_RESPONSE 信号 主要参数 -c Count 指定要被发送(或接收)的回送信号请求的数目,由 Count 变量指出。 -w timeout 这个选项仅和 -c 选项一起才能起作用。以最长时间等待应答 -i Wait 在每个信息包发送之间等待被 Wait 变量指定的时间(秒数) 使用Ping检查连通性有六个步骤: •1.使用ifconfig观察本地网络设置是否正确; •2.Ping127.0.0.1,127.0.0.1回送地址Ping回送地址是为了检查本地的TCP/IP协议有没有设置好; •3.Ping本机IP地址,这样是为了检查本机的IP地址是否设置有误; •4.Ping本网网关或本网IP地址,这样的是为了检查硬件设备是否有问题,也可以检查本机与本地网络连接是否正常;(在非局域网中这一步骤可以忽略) •5.Ping本地DNS地址,这样做是为了检查DNS是否能够将IP正确解析。 •6.Ping远程IP地址,这主要是检查本网或本机与外部的连接是否正常。 Ping的错误回应 A,Request Timed Out "Request Timed Out"这提示除了对方可能装有防火墙或已关机以外,还有就是本机的IP不正确和网关设置错误。 ①、IP不正确: IP不正确主要是IP地址设置错误或IP地址冲突,这可以利用ipconfig /all这命令来检查。在WIN2000下IP冲突的情况很少发生,因为系统会自动检测在网络中是否有相同的IP地址并提醒你是否设置正确。在NT中不但会出现"request time out"这提示而且会出现"Hardware error"这提示信息比较特殊不要给它的提示所迷惑。 ②、网关设置错误:这个错误可能会在第四个步骤出现。网关设置错误主要是网关地址设置不正确或网关没有帮你转发数据,还有就是可能远程网关失效。这里主要是在你Ping外部网络地址时出错。错误表现为无法Ping外部主机返回信息"Request time out"。 ["Request Timed Out"这个信息表示对方主机可以到达到TIME OUT,这种情况通常是为对方拒绝接收你发给它的数据包造成数据包丢失。大多数的原因可能是对方装有防火墙或已下线。] ------但Windows下面,对方主机联不上时(比如网络连接有故障),都是Request Timed Out,而在Linux下面则都是"、"Destination Host Unreachable" B, Destination host unreachable 目的主机无法到达! 当你在开始PING网络计算机时如果网络设备出错它返回信息会提示"destination host unreachable"。如果局域网中使用DHCP分配IP时,而碰巧DHCP失效,这时使用 PING命令就会产生此错误。因为在DHCP失效时客户机无法分配到IP系统只有自设IP,它往往会设为不同子网的IP。所以会出现"Destination Host Unreachable"。另外子网掩码设置错误也会出现这错误。 当然,网络线未接好,也是重要的产生原因. 还有一个比较特殊就是路由返回错误信息,它一般都会在"Destination Host Unreachable"前加上IP地址说明哪个路由不能到达目标主机。这说明你的机器与外部网络连接没有问题,但与某台主机连接存在问题。 如:From 192.168.148.226 icmp_seq=50 Destination Host Unreachable ["Destination Net Unreachable"这个信息表示对方主机不存在或者没有跟对方建立连接。这里要说明一下"destination host unreachable"和"time out"的区别,如果所经过的路由器的路由表中具有到达目标的路由,而目标因为其它原因不可到达,这时候会出现"time out",如果路由表中连到达目标的路由都没有,那就会出现"destination host unreachable"。] C,"Bad IP address" 这个信息表示你可能没有连接到DNS服务器所以无法解析这个IP地址,也可能是IP地址不存在。 D,"Source quench received" 信息比较特殊,它出现的机率很少。它表示对方或中途的服务器繁忙无法回应。 3.for还支持c语言风格的算术表达式 语法: for ((expr1; expr2; expr3 )) do 命令 done for ((i=1; i<4; i++ )) 4.IFS Shell 的环境变量分为 set, env 两种,其中 set 变量可以通过 export 工具导入到 env 变量中。其中,set 是显示设置shell变量,仅在本 shell 中有效;env 是显示设置用户环境变量 ,仅在当前会话中有效。换句话说,set 变量里包含了 env 变量,但 set 变量不一定都是 env 变量。这两种变量不同之处在于变量的作用域不同。显然,env 变量的作用域要大些,它可以在 subshell 中使用。 而 IFS 是一种 set 变量,当 shell 处理"命令替换"和"参数替换"时,shell 根据 IFS 的值,默认是 space, tab, newline 来拆解读入的变量,然后对特殊字符进行处理,最后重新组合赋值给该变量。 1、查看变量 IFS 的值。 echo "$IFS" | od –b 直接输出IFS是看不到的,把它转化为二进制就可以看到了,"040"是空格,"011"是Tab,"012"是换行符"\n" 。最后一个 012 是因为 echo 默认是会换行的。 IFS=$' \t\n' 设置IFS为默认值 2、$* 和 $@ 的细微差别 如果是用冒号引起来,表示这个变量不用IFS替换!!所以可以看到这个变量的"原始值"。反之,如果不加引号,输出时会根据IFS的值来分割后合并输出! $* 是按照IFS中的第一个值来确定的! $ IFS=:; $ set x y z $ echo $* x y z $ echo "$*" x:y:z $ echo $@ x y z $ echo "$@" x y z 3. linux中在某个目录下多个文件中搜索关键字 有四种方法: find 文件目录 -name ‘*.*' -exec grep 'xxx' {} + -n 或是 find 文件目录 -name '*.*' | xargs grep 'xxx' -n 或是 grep 'XXX' 文件目录 -Rn 或是 grep 'XXX' `find 文件目录 -name '*.*'` while 语法: while 条件判断 do 命令 done 常见用法 1.无限循环。 while中的无限循环使用((1))或者[ 1 ]来实现. 1.1示例:时间打印 while ((1)); do echo `date '+%Y-%m-%d %H:%M:%S'` sleep 1 done 1.2示例:计算1到10的和 i=1 sum=0 while ((i<=10));do let sum+=i let ++i done echo $sum 2.读取文件 经典的用法是搭配重定向输入,读取文件的内容。 示例:打印出使用bash的用户 while read line;do bashuser=`echo $line | awk -F: '{print $1,$NF}' | grep 'bash' | awk '{print $1}'` #jugement Bashuser is null or not and print the user who use bash shell if [ ! -z $bashuser ];then echo "$bashuser" fi done < "/etc/passwd" 3. 通过管道传递给{} 通过管道把命令组丢给{} 示例:打印出使用bash的用户 cat /etc/passwd | { while read line;do #use if statement jugement bash shell user and print it if [ "`echo $line | awk -F: '{print $NF}'`" == "/bin/bash" ];then bashuser=`echo $line | awk -F: '{print $1}'` echo "$bashuser" fi done } read 参数: -a :将内容读入到数值中 echo -n "Input muliple values into an array:" read -a array echo "get ${#array[@]} values in array" -d : 表示delimiter,即定界符,一般情况下是以IFS为参数的间隔,但是通过-d,我们可以定义一直读到出现执行的字符位置。例如read –d madfds value,读到有m的字符的时候就不在继续向后读,例如输入为 hello m,有效值为“hello”,请注意m前面的空格等会被删除。这种方式可以输入多个字符串,例如定义“.”作为结符号等等。 -e :只用于互相交互的脚本,它将readline用于收集输入行 -n : 用于限定最多可以有多少字符可以作为有效读入。例如echo –n 4 value1 value2,如果我们试图输入12 34,则只有前面有效的12 3,作为输入,实际上在你输入第4个字符‘3’后,就自动结束输入。这里结果是value为12,value2为3。 -p :用于给出提示符 -r :在参数输入中,我们可以使用’/’表示没有输入完,换行继续输入,如果我们需要行最后的’/’作为有效的字符,可以通过-r来进行。此外在输入字符中,我们希望/n这类特殊字符生效,也应采用-r选项 -s : 对于一些特殊的符号,例如箭头号,不将他们在terminal上打印,例如read –s key,我们按光标,在回车之后,如果我们要求显示,即echo,光标向上,如果不使用-s,在输入的时候,输入处显示^[[A,即在terminal上 打印,之后如果要求echo,光标会上移。 -t :用于表示等待输入的时间,单位为秒,等待时间超过,将继续执行后面的脚本,注意不作为null输入,参数将保留原有的值 until和select循环 1.until 和while相反,当条件为真退出循环 2.select 方便创建菜单 中断与退出循环 continue 结束单次循环 break 结束所有循环 exit 退出脚本 第四章数组Subshell与函数 数组 数组:一组数据的集合,数组中每一个数据被称作一个数组元素。目前bash仅支持一维数组,对数组大小没有限制 语法: 数组名 [索引 n]=值n *提取所有元素时把是所有元素看做一个整体 @提取所有元素时把是所有元素看做若干个体 可以使用$()将命令结果赋值给数组变量 echo ${!数组名[*]} 获取数组所有索引 关联数组 语法: declare –A 数组名 数组名[key1]=值1 数组名[key2]=值2 普通的索引数组无法转换为关联数组 删除数组 unset 变量名 删除数组某个变量 unset 变量名[元素值] subshell 通过当前shell启动的新进程被称为subshell(子shell):subshell会继承变量、工作目录等 Linux执行Scripts有两种方式,主要区别在于是否建立subshell 1. source filename or . filename 不创建subshell,在当前shell环境下读取并执行filename中的命令,相当于顺序执行filename里面的命令 2. bash filename or ./filename 创建subshell,在当前bash环境下再新建一个子shell执行filename中的命令 子shell继承父shell的变量,但子shell不能使用父shell的变量,除非使用export 【备注:这和命名空间是相似的道理,甚至和c中的函数也有些类似】 子Shell从父Shell继承得来的属性如下: 当前工作目录 环境变量 标准输入、标准输出和标准错误输出 所有已打开的文件标识符 忽略的信号 子Shell不能从父Shell继承的属性,归纳如下: 除环境变量和.bashrc文件中定义变量之外的Shell变量 未被忽略的信号处理 3. $ (commond) 它的作用是让命令在子shell中执行 4. `commond` 和$(commond)差不多。 【这里的“ ` ”符号是撇(反单引号),不是单引号,是键盘上Esc按键下面的那个键。】 5. exec commond 替换当前的shell却没有创建一个新的进程。进程的pid保持不变 作用: shell的内建命令exec将并不启动新的shell,而是用要被执行命令替换当前的shell进程,并且将老进程的环境清理掉,而且exec命令后的其它命令将不再执行。 当在一个shell里面执行exec ls后,会列出了当前目录,然后这个shell就自己退出了。(后续命令不再执行) 因为这个shell已被替换为仅执行ls命令的进程,执行结束自然也就退出了。 需要的时候可以用sub shell 避免这个影响,一般将exec命令放到一个shell脚本里面,用主脚本调用这个脚本,调用点处可以用bash a.sh(a.sh就是存放该命令的脚本),这样会为a.sh建立一个sub shell去执行,当执行到exec后,该子脚本进程就被替换成了相应的exec的命令。 文件描述符与命令管道 文件描述符:一个非负整数。 在Linux通用I/O模型中,I/O操作系列函数(系统调用)都是围绕一个叫做文件描述符的整数展开。 I/O操作系统调用都以文件描述符(一个非负整数),指代打开的文件。每个进程都有一个打开文件表,可以理解成一个数组,文件描述符可以理解成数组的下标。 相关I/O操作系统调用以文件描述符为参数,便可以通过数组访问定位到指定的文件对象,进而进行I/O操作。 当某个程序打开文件时,操作系统返回相应的文件描述符,程序为了处理该文件必须引用此描述符。所谓的文件描述符是一个低级的正整数。最前面的三个文件描述符(0,1,2)分别与标准输入(stdin),标准输出(stdout)和标准错误(stderr)对应 linux系统中通常会对每个进程所能打开的文件数据有一个限制,当进程中已打开的文件描述符超过这个限制时,open()等获取文件描述符的系统调用都会返回失败。 linux下最大文件描述符的限制有两个方面,一个是用户级的限制,另外一个则是系统级限制。 用户级限制:ulimit命令看到的是用户级的最大文件描述符限制,也就是说每一个用户登录后执行的程序占用文件描述符的总数不能超过这个限制 系统级限制:sysctl命令和proc文件系统中查看到的数值是一样的,这属于系统级限制,它是限制所有用户打开文件描述符的总和 查看限制数量 查看用户级限制:ulimit -n 系统级限制: sysctl -a cat /proc/sys/fs/file-max 修改限制数量 修改用户级限制 临时修改,只对当前shell有效:ulimit -HSn 65536 永久修改:编辑/etc/security/limits.conf -> % ulimit -SHn 2048 yao@yao-virtual-machine [10时49分18秒] [~/work/util] -> % ulimit -n 2048vi /etc/security/limits.conf * hard nofile 65536 * soft nofile 65536 修改系统级限制 通过sysctl命令修改/etc/sysctl.conf文件:sysctl -w fs.file-max=2048,完成后执行sysctl -p即可 1.查看文件描述符 ps –ao user,pid,comm | grep 命令 ls –l /proc/命令的进程号/fd 2.创建,调用,关闭 创建 exec 文件描述符 <> 文件名 调用 &文件描述符 关闭 exec 文件描述符 <&-或exec 文件描述符 >&- 文件描述符: 12 仅可以重定向输出 13 仅可以重定向输入 14 既可以重定向输入又可以重定向输出 read -u可以通过文件描述符读取文件内容,但每次仅读取一行 read -u –n1 读取任意字符的数据 3.命名管道 FIFO本质上和匿名管道的功能一样,只不过它有一些特点: 1)在文件系统中,FIFO拥有名称,并且是以设备特俗文件的形式存在的; 2)任何进程都可以通过FIFO共享数据; 3)除非FIFO两端同时有读与写的进程,否则FIFO的数据流通将会阻塞; 4)匿名管道是由shell自动创建的,存在于内核中;而FIFO则是由程序创建的(比如mkfifo命令),存在于文件系统中; 5)匿名管道是单向的字节流,而FIFO则是双向的字节流; 排序算法 基础 0.1 排序的定义 对一序列对象根据某个关键字进行排序。 0.2 术语说明 稳定 : 如果a原本在b前面,而a=b,排序之后a仍然在b的前面; 不稳定 :如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面; 内排序 :所有排序操作都在内存中完成; 外排序 :由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行; 时间复杂度 : 一个算法执行所耗费的时间。 空间复杂度 :运行完一个程序所需内存的大小。 0.3 算法总结 图片名词解释: n: 数据规模 k: “桶”的个数 In-place: 占用常数内存,不占用额外内存 Out-place: 占用额外内存 0.4 算法分类 0.5 比较和非比较的区别 常见的快速排序、归并排序、堆排序、冒泡排序 等属于比较排序 。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置 。 计数排序、基数排序、桶排序则属于非比较排序 。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置 。 1.冒泡排序(Bubble Sort) 冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 1.1 算法描述 步骤1: 比较相邻的元素。如果第一个比第二个大,就交换它们两个; 步骤2: 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数; 步骤3: 针对所有的元素重复以上的步骤,除了最后一个; 步骤4: 重复步骤1~3,直到排序完成。 echo "please input a number list:" read -a arrs for((i=0;i<${#arrs[@]};i++)) { for((j=0;j<${#arrs[@]}-1;j++)) { if [[ ${arrs[j]} -gt ${arrs[j+1]} ]];then tmp=${arrs[j]} arrs[j]=${arrs[j+1]} arrs[j+1]=$tmp fi } } echo "result:" echo ${arrs[@]} 2.选择排序(Selection Sort) 选择排序 是表现最稳定的排序算法之一 ,因为无论什么数据进去都是O(n2)的时间复杂度 ,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。 选择排序(Selection-sort) 是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 2.1算法描述 n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下: 步骤1:初始状态:无序区为R[1…n],有序区为空; 步骤2:第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区; 步骤3:n-1趟结束,数组有序化了。 echo "please input a number list:" read -a arrs for((i=0;i<${#arrs[@]};i++)) { mindex=i; for((j=i+1;j<${#arrs[@]};j++)) { if [[ ${arrs[j]} -lt ${arrs[mindex]} ]];then mindex=j; fi } tmp=${arrs[i]} arrs[i]=${arrs[mindex]} arrs[mindex]=$tmp } echo "result:" echo ${arrs[@]} 3.快速排序(Quick Sort) 快速排序 的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 3.1 算法描述 快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下: 步骤1:从数列中挑出一个元素,称为 “基准”(pivot ); 步骤2:重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作; 步骤3:递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。 #初始化数组 num=(5 3 8 2 2 4 435 465 23) #定义一个快速排序的函数 quick_sort(){ #先判断个数。$1是数组最左边的坐标,$2是数组最右边的坐标 if [ $1 -gt $2 ];then return fi #定义局部变量,base为基准数字,此函数选择最左边的函数num{$1}为基准数字 #left表示左边的坐标,right表示右边的坐标 local base=${num[$1]} local left=$1 local right=$2 #在排序的数字序列中,比基数大的放右边,比基数小的放左边 while [ $left -lt $right ] do #right 向左移动,找到比base小的元素 while [[ ${num[right]} -ge $base && $left -lt $right ]] do let right-- done #left 向右移动,找到比base大的元素 while [[ ${num[left]} -le $base && $left -lt $right ]] do let left++ done #将left坐标元素和right坐标元素交换 if [ $left -lt $right ];then local tmp=${num[left]} num[$left]=${num[right]} num[$right]=$tmp fi done #将base和left坐标元素交换 num[$1]=${num[left]} num[left]=$base #递归调用函数,对左边的元素快排 quick_sort $1 $[left-1] #递归调用函数,对右边的元素快排 quick_sort $[left+1] $2 } #调用函数对数组进行排序 quick_sort 0 ${#num[@]} echo "排序后的数组" echo ${num[*]} 4.插入排序 插入排序(Insertion-Sort) 的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。 4.1 算法描述 一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下: 步骤1: 从第一个元素开始,该元素可以认为已经被排序; 步骤2: 取出下一个元素,在已经排序的元素序列中从后向前扫描; 步骤3: 如果该元素(已排序)大于新元素,将该元素移到下一位置; 步骤4: 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置; 步骤5: 将新元素插入到该位置后; 步骤6: 重复步骤2~5。 二分法 适用范围为一个已经排好序的数组(升序、降序) 升序数组)步骤: 左端点(l) 右端点(r) 查找的值(key) 中间(m) 数组(arr) 1.找到数组 l 与 r 2.让需 key 与 arr[m] 作比较 3.如果 key > arr[m] 4.让 l = m + 1 , 继续循环 5.如果 key < arr[m] 6.让 r = m - 1 , 继续循环 7.如果 key = arr[m] 则找到该值,跳出循环 8.结束循环后判断 l 是否大于 r ,来判断是否找到该值 程序代码: # !/bin/bash array=(1 2 3 4 5 6 7 8 9 10 11 12) #shell脚本中定义数组 read -p "num: " key #提示输入查找的值 key l=0 #左端点 l r=`expr ${#array[@]} - 1 ` #右端点 r for (( ;l<=r; )) #当 l>r 时没有交集,结束循环 do m=`expr $l + $r ` m=`expr $m / 2 ` #获取中间端点 m if test ${array[$m]} -eq $key #若中间值(array[m])= 查找值(key)跳出循环 then echo "$key查找成功" break else if test ${array[$m]} -gt $key #若中间值(array[m])> 查找值(key) then r=`expr $m - 1 ` #让右端点(r) = 中间端点(m)- 1 else #若中间值(array[m])< 查找值(key) l=`expr $m + 1 ` #让左端点(l) = 中间端点(m)- 1 fi fi done if test $l -gt $r #循环结束判断是否找到需要查找的值 then #判断条件为 l>r echo "$key 查找失败" fi 八个扩展功能 1.花括号{} 1.1对字符串扩展 echo {a..z} 输出a到z echo {1..9..3} 输出1 4 7 3为步长.间隔 echo t{o,e{a.m}}p 输出 top teap temp cp /top/at.txt{,.bak} 备份 at.txt.bak mv /top/bt.txt{,.sh} 重命名 bt.sh 1.2代码块 又被称为内部组,格式为{ cmd1;cmd2;},这个结构事实上创建了一个匿名函数 。 {}与()都可以执行一连串命令,区别如下: 1.()会新开一个子进程,括号内命令与括号外无关。{}内的命令不会新开一个子进程运行,即脚本余下部分仍可使用括号内变量。 2.两者括号内的命令间都要用;隔开,但()最后一个命令的分号可有可无,但{}最后一个也必须有分号。 3.{}的第一个命令和左括号{之间必须要有一个空格(右括号}无此要求),而()两个括号的空格均可有可无。 1.3特殊替换结构 有4种特殊的替换结构:${var:-string},${var:+string},${var:=string},${var:?string} (1) (2) (3) (4)${var:?string}表示若变量var不为空,则等于var的值,否则把string输出到标准错误中,并从脚本中退出。 我们可利用此特性来检查是否设置了变量的值 1.4模式匹配截断 有4种模式:${var%pattern},${var%%pattern},${var#pattern},${var##pattern} (1) (2) (3) (4) 1.5长度截断 有2种模式:${var:num},${var:num1:num2} (1)${var:num}表示提取var中第num个字符到末尾的所有字符。若num为正数,从左边0处开始;若num为负数,从右边开始提取字串,但必须使用在冒号后面加空格或一个数字或整个num加上括号,如${var: -2}、${var:1-3}或${var:(-2)}。 (2)${var:num1:num2}表示从var中第num1个位置开始提取长度为num2的子串。num1从0开始。 2.波浪号~ 默认代表当前用户的家目录 echo ~Leo 显示Leo的家目录 echo ~+ 当前工作目录 echo~- 前一个目录 3.变量替换$ 如果变量大于1,${2} ${21} 3.1变量 (1)在Shell中,通常情况下用户可以直接使用变量,而毋需先进行定义,当用户第一次使用某个变量名时,实际上就同时定义了这个变量,在变量的作用域内,用户都可以使用该变量。 (2)通过declare命令声明变量 -p:显示所有变量的值。 -i:将变量定义为整数。在之后就可以直接对表达式求值,结果只能是整数。如果求值失败或者不是整数,就设置为0。declare -i t,把t设置为整型 -r:将变量声明为只读变量。只读变量不允许修改,也不允许删除。readonly, -a:变量声明为数组变量。但这没有必要。所有变量都不必显式定义就可以用作数组。事实上,在某种意义上,似乎所有变量都是数组,而且赋值给没有下标的变量与赋值给下标为0的数组元素相同. array,矩阵,变长数组 -f:显示所有自定义函数,包括名称和函数体。function -x:将变量设置成环境变量,这样在随后的脚本和程序中可以使用 3.2变量的间接引用 player=”leo” mvp=player echo ${mvp} 输出player echo ${!mvp} 输出 leo other=mvp echo ${!other}输出player 4.变量的空值测试 语法格式 描述 ${变量:-关键字} 如果未定义或为空,返回关键字,否则返回变量值 ${变量:=关键字} 如果未定义或为空,则将关键字赋值给变量,并返回结果,否则返回变量值 ${变量:?关键字} 如果未定义或为空,通过标准错误显示包含关键字的错误信息,否则返回变量值 ${变量:+关键字} 如果未定义或为空,直接返回空,否则返回关键字 5.变量的替换 语法格式 描述 ${变量:偏移量} 从变量的偏移量(起始值为0)位置开始截取变量的值到结尾 ${变量:偏移量:长度} 从变量的偏移量(起始值为0)位置开始截取特定长度 ${变量#关键字} 使用关键字进行匹配,从左往右删除匹配到的内容,关键字可以使用*,使用#匹配时为最短匹配(最短匹配掐头) ${变量##关键字} 使用关键字进行匹配,从左往右删除匹配到的内容,关键字可以使用*,使用##匹配时为最长匹配(最长匹配掐头) ${变量%关键字} 使用关键字进行匹配,从右往左删除匹配到的内容,关键字可以使用*,使用%匹配时为最短匹配(最短匹配去尾) ${变量%%关键字} 使用关键字进行匹配,从右往左删除匹配到的内容,关键字可以使用*,使用%%匹配时为最短匹配(最长匹配去尾)
 正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消
正在上传…重新上传取消正在上传…重新上传取消正在上传…重新上传取消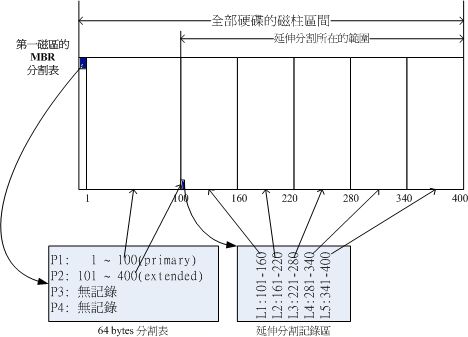 正在上传…重新上传取消
正在上传…重新上传取消 正在上传…重新上传取消正在上传…重新上传取消
正在上传…重新上传取消正在上传…重新上传取消1.6.9通配符
yum install kde-l10n-Chinese1.6.10 shopt
shell算法
转存失败重新上传取消转存失败重新上传取消正在上传…重新上传取消第五章脚本技巧
${var:-string}表示若变量var不为空,则等于var的值,否则等于string的值。${var:=string}的替换规则与${var:-string}相同,不过多了一步操作:若var为空时,还会把string的值赋给var${var:+string}的替换规则和上面的相反,表示若变量var不为空,则等于string的值,否则等于var的值(即空值)${var%pattern}表示看var是否以模式pattern结尾,如果是,就把var中的内容去掉右边最短的匹配模式${var%%pattern}表示看var是否以模式pattern结尾,如果是,就把var中的内容去掉右边最长的匹配模式。${var#pattern}表示看var是否以模式pattern开始,如果是,就把var中的内容去掉左边最短的匹配模式。${var##pattern}表示看var是否以模式pattern开始,如果是,就把var中的内容去掉左边最长的匹配模式。