自然语言处理 典型场景分析
情感分析
又称倾向性分析,意见抽取,情感挖掘。是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
主要流程:
输入数据 -> tokenization -> stop word filtering -> NegationHanding -> stemming -> classification -> sentimentclass

tokenization:对输入的数据进行规整化
stopwordfiltering:停用词过滤,去掉一些没啥用的词语以及符号,比如说:and、or、了、?等
NegationHanding:对否定的特殊情况进行处理,比如说,我不是很开心 就不能忽略“不”字
Stemming:词干提取,抽取词的词干或词根形式
classification:分类
sentimentclass:更进一步的情感分类
类别:
社交网络分析,各类的评论,新闻报道,博客,微博,产品或顾客的评价等主观情感
方法:
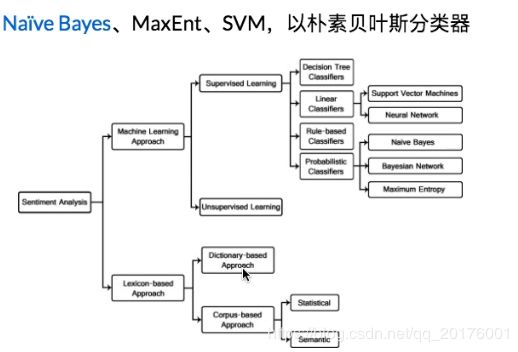
machineLearning:
监督学习:SupervisedLearning
贝叶斯、朴素贝叶斯、支持向量机等
无监督学习:Unsupervisedlearning
传统方法:
采用譬如 词袋模型(Bag of Words (BOW))表示会忽略其词顺序、语法和句法,并不能充分表示文本的语义信息
深度学习方法:
用于文本分类的多层感知机网络
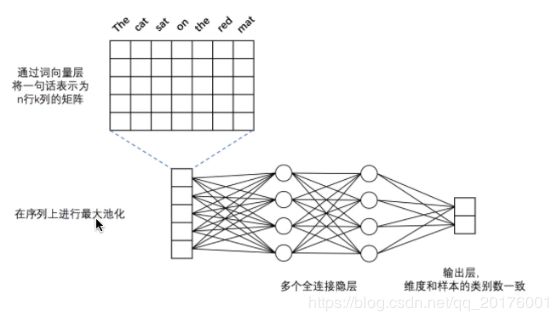
卷积神经网络 VS 循环神经网络
卷积神经网络:不仅可以用在计算机视觉,也可以通过变化用于文本分类的任务上
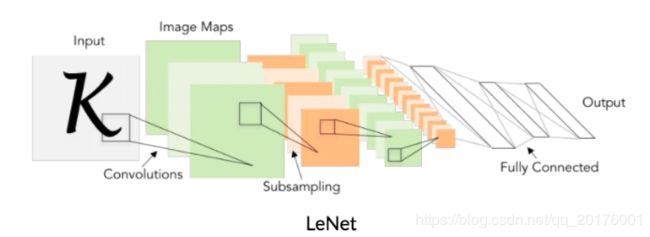
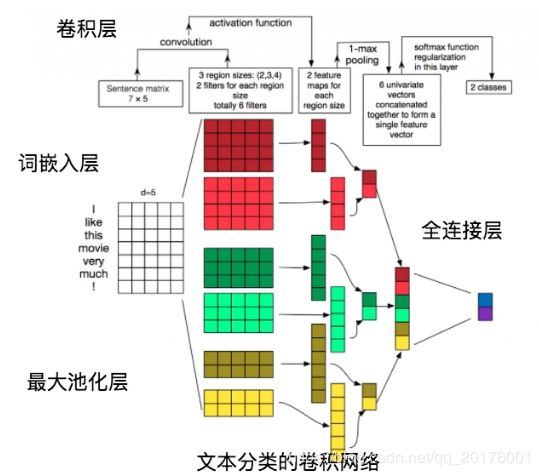
卷积层:文本分类中的卷积在时间序列上进行,即卷积核的宽度和词向量层产生出的矩阵一致,卷积沿着矩阵 的高度方向进行。卷积后得到的结果被称为特征图(feature map)
最大池化层:对卷积得到的各个特征图分别进行最大池化操作。特征图已经是向量了,所以最大池化就是简单 地选出各个向量中的最大元素,然后将每个特征图的最大元素拼接成新的向量。
全连接层:将最大池化的结果通过全连接层输出,最后输出层的神经元个数与样本的类别数量一致,且输出之 和为1
相关的 CNN(卷积神经网络)详解 或者 详解CNN卷积神经网络
词嵌入层:将词语转换成固定维度的向量,利用向量之间的距离来表示词之间的语义相关程度(又称词向量)
循环神经网络:用于文本分类
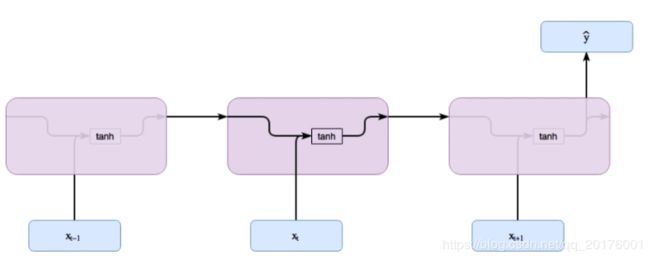
X是每个单词对应的输入值,即 一个单词输入之后会与前一个单词输入时的隐藏层共同作用来产生结果
也就是说,前一个单词的输入会对后一个单词的结果产生影响,也就有了时序性
此处的h(t-1)是上一个词语输入的隐藏层状态,X(t)是当前的输入,h(t)是当前输入x(t)之后的隐藏层状态
栈式LSTM网络模型:(又称Deep LSTM)即包含多个LSTM层的LSTM模型
由Graves等人在语音识别任务中尝试,超过了当时的最好方法
网络深度比一个给定层的神经元个数更加重要,通过叠加多层,使得网络模型性能提高
是序列预测问题的首选结构
LSTM层会给一个序列作为输出而不是单个的值,每个时间步都有一个输出
双向循环神经网络结构:
对于一些特定的场景,可以发现正向和反向的输入能够使用过去和未来的信息
通过添加额外的一层,这一层会接受完全相反的副本作为输入,更好利用手上的数据
举个例子(我是天下最帅的男人,反向输入 男人 最帅的 天下 是 我)就将未来的信息放到前面去了
双向LSTM网络结构:相比单向网络能够达到更好的效果
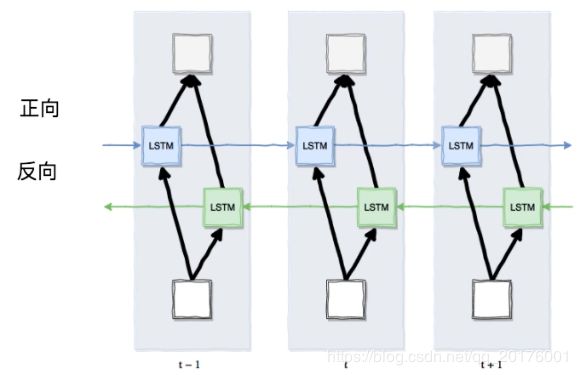
分别正向和逆向输入Input
双向的传播将前后信息进行汇聚
将正常的LSTM的神经元分成两个部分:正时间方向和负时间方向
栈式双向LSTM网络:
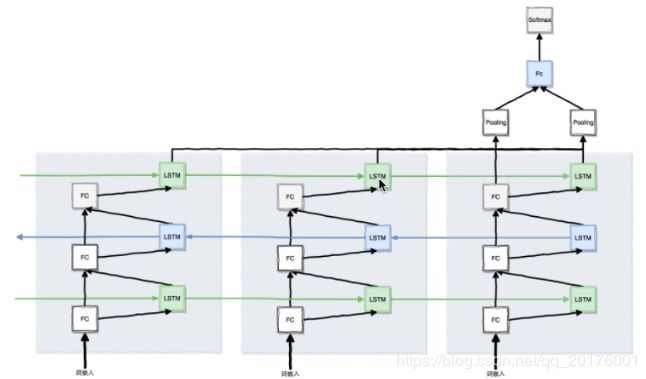
每个时间步接受一个词输入(词向量)
词输入通过两步去流动,一步是传给LSTM(顺序),一步是进入下一个全连接层
接着继续两步流动,一步是传给下一个LSTM(逆向),一步是进入下一个全连接层,这里体现了双向
接着继续下一步,此处采用比较简单的三层LSTM模型(可继续增加层数的深度)