用pandas进行数据分析实战
转载自http://mp.weixin.qq.com/s?__biz=MjM5NjEyMDI2MQ==&mid=2455947430&idx=1&sn=11da6ff57dbaeae9343e822ac8a2f3a7&chksm=b1787b0c860ff21a2568234ea1b5a1bf86c91c2b96ef876863f5dc11ad7de27510107a94c549&scene=21#wechat_redirect
主要内容是进行数据读取,数据概述,数据清洗和整理,分析和可视化。按照本教程,相信大家的Pandas会上到一个新台阶,遇到文中没有提及的错误,通过搜索引擎解决吧。
首先载入我们的练习数据。
在pandas中,常用的载入函数是read_csv。除此之外还有read_excel和read_table,table可以读取txt。若是服务器相关的部署,则还会用到read_sql,直接访问数据库,但它必须配合mysql相关包。
read_csv拥有诸多的参数,encoding是最常用的参数之一,它用来读取csv格式的编码。这里使用了gb2312,该编码常见于windows,如果报错,可以尝试utf-8。
sep参数是分割符,有些csv文件用逗号分割列,有些是分号,有些是\t,这些都需要具体设置。header参数为是否使用表头作为列名。
names参数可以为列设置额外的名字,比如csv中的表头是中文,但是在pandas中最好转换成英文。
上述是主要的参数,其他参数有兴趣可以学习。一般来说,csv的数据都是干净的,excel文件则有合并单元格这种恶心的玩意,尽量避免。

现在有了数据df,首先对数据进行快速的浏览。

这里列举出了数据集拥有的各类字段,一共有6876个,其中companyLabelList,businessZones,secondType,positionLables都存在为空的情况。
公司id和职位id为数字,其他都是字符串。
因为数据集的数据比较多,如果我们只想浏览部分的话,可以使用head函数,显示头部的数据,默认5,也可以自由设置参数,如果是尾部数据则是tail。
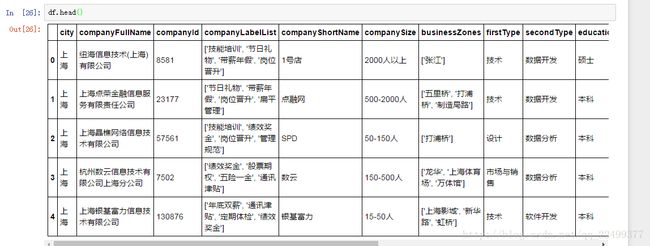
数据集中,最主要的脏数据是薪资这块,后续我们要拆成单独的两列。
看一下是否有重复的数据。

unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一。配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
使用drop_duplicates清洗掉。
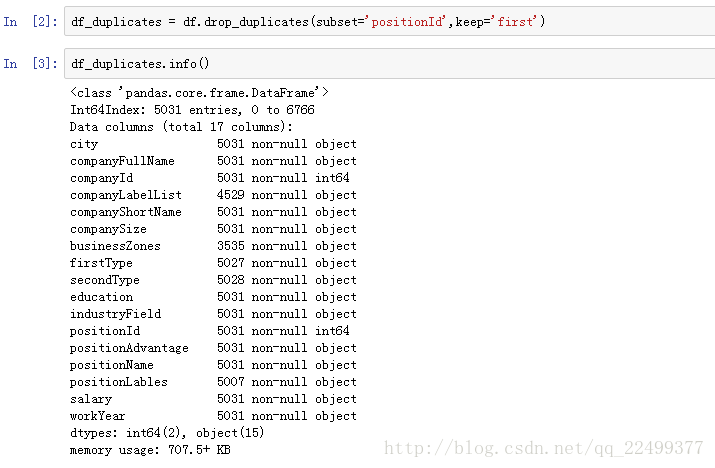
drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last还是删除前面,保留最后一个。
duplicated函数功能类似,但它返回的是布尔值。
接下来加工salary薪资字段。目的是计算出薪资下限以及薪资上限。
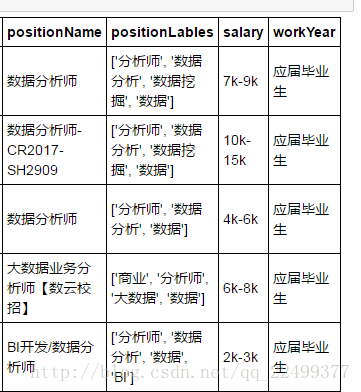
薪资内容没有特殊的规律,既有小写k,也有大小K,还有「k以上」这种蛋疼的用法,k以上只能上下限默认相同。
这里需要用到pandas中的apply。它可以针对DataFrame中的一行或者一行数据进行操作,允许使用自定义函数。

我们定义了个cut_word函数,它查找「-」符号所在的位置,并且截取薪资范围开头至K之间的数字,也就是我们想要的薪资上限。
apply将cut_word函数应用在salary列的所有行。
「k以上」这类脏数据怎么办呢?find函数会返回-1,如果按照原来的方式截取,是word[:-2],不是我们想要的结果,所以需要加一个if判断。
因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。这里不建议用「以上」,因为有部分脏数据不包含这两字。
在word_cout函数增加了新的参数用以判断返回bottom还是top。apply中,参数是添加在函数后面,而不是里面的。这点需要注意。

把topSalary和bottomSalary都改成int类型的。
接下来求解平均薪资。
![]()
数据类型转换为数字,这里引入新的知识点,匿名函数lambda。很多时候我们并不需要复杂地使用def定义函数,而用lamdba作为一次性函数。
lambda x: * ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。word_cut的apply是针对Series,现在则是DataFrame。
axis是apply中的参数,axis=0表示将函数用在行,axis=1则是列。
这里的lambda可以用(df_duplicates.bottomSalary + df_duplicates.topSalary)/2替代。
到此,数据清洗的部分完成。切选出我们想要的内容进行后续分析(大家可以选择更多数据)。

先对数据进行几个描述统计。
value_counts是计数,统计所有非零元素的个数,以降序的方式输出Series。数据中可以看到北京招募的数据分析师一骑绝尘。
我们可以依次分析数据分析师的学历要求,工作年限要求等。
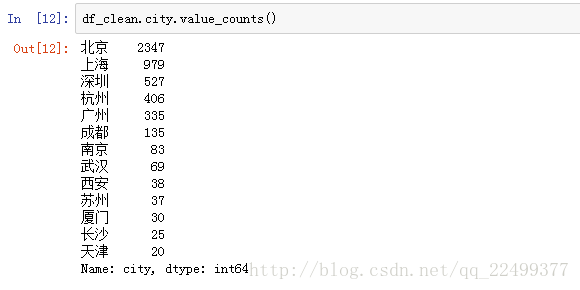
针对数据分析师的薪资,我们用describe函数。
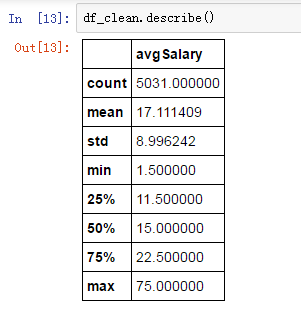
它能快速生成各类统计指标。数据分析师的薪资的平均数是17k,中位数是15k,两者相差不大,最大薪资在75k,应该是数据科学家或者数据分析总监档位的水平。
标准差在8.99k,有一定的波动性,大部分分析师薪资在17+-9k之间。
一般分类数据用value_counts,数值数据用describe,这是最常用的两个统计函数。
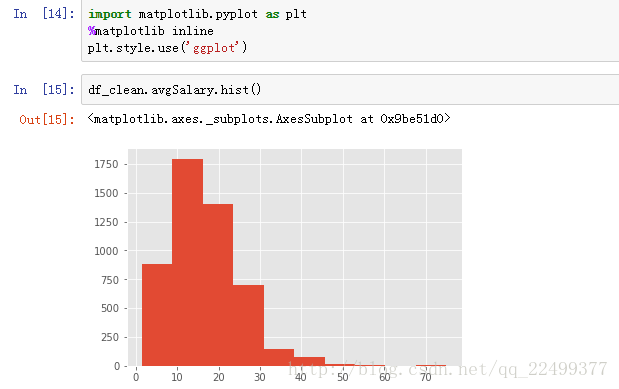
说了这么多文字,还是不够直观,我们用图表说话。
pandas自带绘图函数,它是以matplotlib包为基础封装,所以两者能够结合使用。

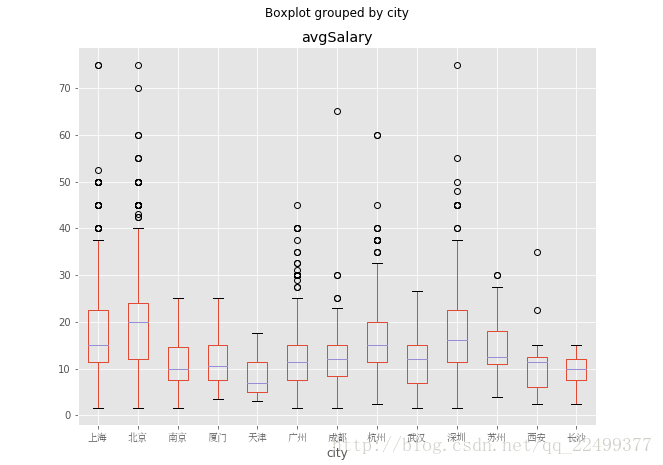
首先加载字体管理包,设置一个载入中文字体的变量,不同系统的路径不一样。boxplot是我们调用的箱线图函数,column选择箱线图的数值,by是选择分类变量,figsize是尺寸。
ax.get_xticklabels获取坐标轴刻度,即无法正确显示城市名的白框,利用set_fontpeoperties更改字体。于是获得了我们想要的箱线图。改变字体还有其他方法,
大家可以网上搜索关键字「matplotlib 中文字体」,都有相应教程。
从图上我们看到,北京的数据分析师薪资高于其他城市,尤其是中位数。上海和深圳稍次,广州甚至不如杭州。
现在来处理标签数据。

现在的目的是统计数据分析师的标签。它只是看上去干净的数据,元素中的[]是无意义的,它是字符串的一部分,和数组没有关系。
你可能会想到用replace这类函数。但是它并不能直接使用。df_clean.positionLables.replace会报错,为什么呢?因为df_clean.positionLables是Series,并不能直接套用replace。apply是一个好方法,但是比较麻烦。
这里需要str方法。
dropna()将所有含有NaN项的行删除,dropna()经常用来清理无效数据。
str方法允许我们针对列中的元素,进行字符串相关的处理,这里的[1:-1]不再是DataFrame和Series的切片,而是对字符串截取,这里把[]都截取掉了。
如果漏了str,就变成选取Series第二行至最后一行的数据,切记。
使用完str后,它返回的仍旧是Series,当我们想要再次用replace去除空格。还是需要添加str的。现在的数据已经干净不少。
positionLables本身有空值,所以要删除,不然容易报错。再次用str.split方法,把元素中的标签按「,」拆分成列表。
这里是重点,通过apply和value_counts函数统计标签数。因为各行元素已经转换成了列表,所以value_counts会逐行计算列表中的标签,apply的灵活性就在于此,它将value_counts应用在行上,最后将结果组成一张新表。
这里的运算速度会有点慢,别担心。
用unstack完成行列转换,看上去有点怪,因为它是统计所有标签在各个职位的出现次数,绝大多数肯定是NaN。
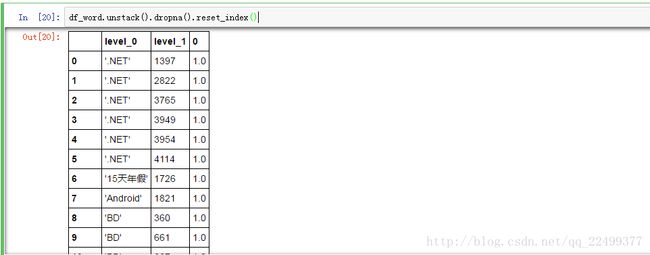
将空值删除,并且重置为DataFrame,此时level_0为标签名,level_1为df_index的索引,也可以认为它对应着一个职位,0是该标签在职位中出现的次数,之前我没有命名,所以才会显示0。部分职位的标签可能出现多次,这里忽略它。reset_index可以还原索引,重新变为默认的整型索引。
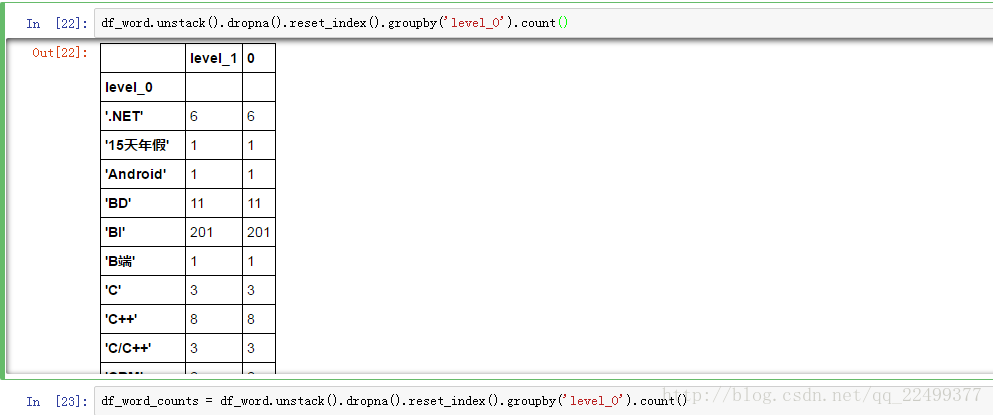
最后用groupby计算出标签出现的次数。到这里,已经计算出我们想要的结果。除了这种方法,也可以使用for循环,大家可以试着练习一下,效率会慢不少。
这种写法的缺点是占用内存较大,拿空间换时间,具体取舍看大家了。

加载wordcloud,anaconda没有,自行下载吧。清洗掉引号,设置词云相关的参数。因为我是在jupyter中显示图片,所以需要额外的配置figsize,不然wide和height的配置无效。wordcloud也兼容pandas,所以直接将结果传入,然后显示图片,去除坐标。大功告成。
