【目标检测】目标检测问题综述 目标检测算法盘点
问题描述
目标检测的任务是, 找出图像中的感兴趣对象,即给出它们的类别以及具体位置 (以bounding box,包围盒的形式给出),是计算机视觉领域的核心问题之一。
目标检测和图像分类的直观比较如图所示:

目标检测的难点
- 图像中 物体的数量不确定(可能有多个,也可能没有)
- 物体本身有 不同的外观、形状、姿态
- 物体成像时会有 可视大小、视角差异、光照条件、遮挡情况 等因素的干扰
- 背景干扰等等
这些都给检测算法带来了很大的 不确定性。
目标检测常见应用
人脸检测、文本检测、交通检测、通用物体识别等
预备知识
目标检测算法常用评价指标
① 基础知识:交并比(intersection over union, IoU)
在介绍评价指标之前,我们需要先了解一下IoU的概念,即模型预测的包围盒(bounding box) 和 真实包围盒 的重合率(= 交集的面积/并集的面积 x 100%),取值为[0, 1]。
交并比度量了模型预测的包围盒和真实包围盒的接近程度(大小和位置两个方面都考虑在内),交并比越大,两个包围盒的接近程度越高。


② mAP (mean average precision)
目标检测算法“好坏”的评估和一般二元分类的评估有所不同,我们即需要判断出正确的类别,又需要给出目标准确的位置【分类+定位两个层面】。
mAP解释起来比较复杂,网上关于mAP的介绍很多都是错误的,这边给出个人认为讲的比较好理解的一篇:详解object detection中的mAP
③ fps
目标检测算法的检测速度也是需要考虑的重要因素【有些应用对检测的低延迟有着比较高的要求,比如自动驾驶,机器人这些】。

目标检测常用数据集
PASCAL VOC 包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。Pascal Voc数据集详细分析
MS COCO COCO比VOC更困难。COCO包含80k训练图像、40k验证图像、和20k没有公开标记的测试图像(test-dev),80个类别,平均每张图7.2个目标。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试。Microsoft COCO 数据集介绍
目标检测算法的基本技术
非极大值抑制算法(non maximum suppression, NMS)
非极大值抑制(non maximum suppression, NMS),主要解决的是一个目标被多次检测的问题,在所有的检测算法中都会用到。
打个比方,如下图中的人脸检测,可以看到人脸被多次检测,我们希望最后只输出其中最好的那个预测框,比如对于ROSE,只想要红色那个检测结果,那么我们可以采用NMS对重叠框进行剔除。
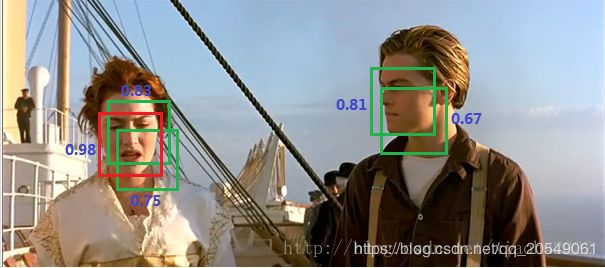
NMS算法的具体操作步骤【一般多类别检测场景下,对每个类别分别进行】:
- 对所有检测到的框按照得分进行排序,选出得分最高的检测框
- 然后挨个计算其与剩余框的IOU,如果值大于一定阈值(重合度过高),那么就将该框剔除(也就是所谓的非极大值抑制)
- 对剩余的检测框重复上述过程,直到所有检测框都被处理后我们输出最终的检测框。
深度目标检测算法简介
进入深度学习时代以来,目标检测算法主要可分为两种思路:
- two stage 算法,以
Faster R-CNN为代表 - one stage 算法,以
SSD、YOLOv3为代表。
两者的主要区别在于,
- two stage算法需要先生成regions proposal (建议框,或者叫候选区域,即图像上可能包含目标的区域),然后对候选区域进行分类和校正 。
- one stage算法直接对输入图片预测出物体的类别和位置【端到端】。
P.S. 国外有大牛对近年来的目标检测算法论文进行了整理和汇总:Github 地址。下图中用红色字体标出的是他认为必读的,重要的论文。

Two stage算法
前身:滑动窗口检测器
基于滑动窗口进行目标检测,也就是穷举搜索【暴力法】,即采用 不同大小和宽高比 的窗口在整张图片上以 一定的步长 进行滑动,然后对这些窗口区域做图像分类【将目标检测问题转化为图像分类问题】。

下面是伪代码。
for window in windows patch = get_patch(image, window):
results = detector(patch)
这种方法的致命的缺点 ,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和宽高比的窗口去滑动,而且还要选取合适的步长,结果会导致 产生很多的子区域,而且 其中的大多数是不包含任何目标的背景区域,这些区域都要输入分类网络进行分类,将 导致大量的无用计算。
要提升性能,一个显而易见的方法就是减少窗口的数量。比如提取可能包含目标的候选区域(Region Proposal),这也正是two stage算法的初衷。
Two-Stage 基本流程
也叫作 基于候选区域的目标检测算法,上面也讲了,该类算法分两步来解决问题:
- step1. 通过特定的方式提取regions proposal (候选区域,即图像上可能包含目标的区域)
- step2. 对候选区域进行分类和位置校正。
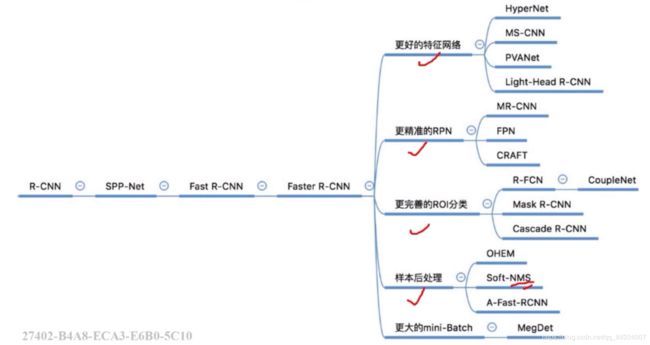
Two-stage的发展历程如下图所示:
R-CNN
【目标检测框架】Two-Stage框架:R-CNN详细解读
R-CNN在2014年被提出,是 第一个基于深度学习的目标检测器。它的思路很简单:
- 给定一张输入图像,使用
selective search提取约2k个建议框 (region proposal) - 将每个建议框变形至固定size【227x227】,输入到预训练的ImageNet网络
AlexNet中,提取出4096维的特征。 - 用
线性SVM分类器来对特征分类 - 用
回归器 (regressor)对建议框进行校正精修。
R-CNN 的检测流程如图所示:

Fast R-CNN
【目标检测框架】Two-Stage框架:Fast R-CNN 详细解读
R-CNN存在以下几个问题:
- 训练、测试过程繁琐。CNN网络预训练+fine-tuning训练+SVM分类器训练+bounding box 回归器训练。
- 需要将 region proposal 变形至固定大小,再输入网络提取特征
- 每张图片的每个region proposal都需要进行一次CNN提取特征。2000个建议框存在大量的重叠,故会导致许多重复冗余的卷积计算。
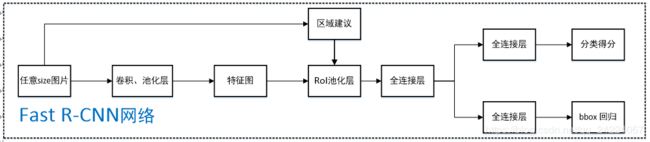
Fast RCNN针对上述问题进行了改进,在保证效果的同时提高效率:
- 特征提取部分,使用 CNN 先提取整个图像的特征图 (feature map),再将建议框从原图映射到特征图上从而得到建议框的特征
- 使用
ROI pooling实现从 不同大小的建议框的特征 到 相同大小特征 的转换 - 网络最后改用两个并行的全连接层分支,同时产生分类和bounding box回归两个输出
Fast R-CNN的检测流程如下图所示:
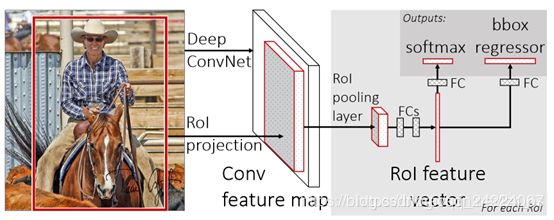
ROI pooling
ROI Pooling的作用是 对 不同大小 的特征框,提取 固定大小 的特征,以满足全连接层的输入要求,具体步骤为:
- 将一个特征框分割成H×W个网格
- 计算每个网格里的最大值(Max Pooling)作为该网格的输出。
Faster R-CNN
【目标检测】Two-Stage目标检测框架之 Faster R-CNN
Fast R-CNN进行预测时,每张图像的网络前向传播计算只需0.2秒,但建议框的生成却需要2秒。
Faster R-CNN最大的突破在于提出了候选区域网络 (Region Proposal Networks, RPN),利用CNN来代替先前的Selective Search、EdgeBoxes等方法生成建议框,使得建议框的生成几乎不耗费时间。
Faster R-CNN的结构如下图所示【可以理解成RPN+Fast R-CNN】:

候选区域网络(region proposal networks, RPN)
RPN的结构如下图所示:
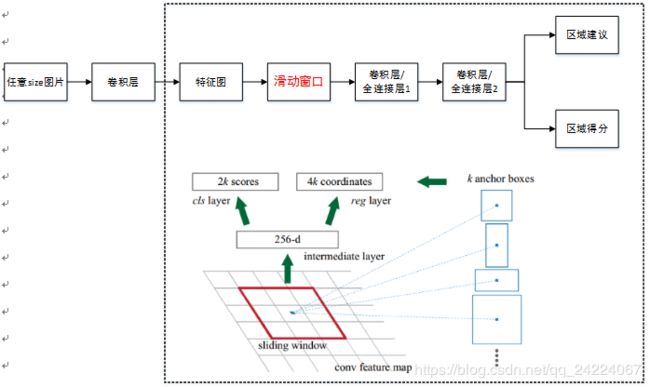
- RPN延续了基于滑动窗口进行目标定位的思路,不同之处在于RPN是在feature map上而不是在原图上进行滑窗
- feature map上 n × n n×n n×n大小的滑动窗口和一个小的中间层(intermediate layer)完全连接,映射至一个低维向量(ZF为256-d, VGG为512-d)。然后该向量被输入到两个分支层产生两个网络输出,一个是 box-regression层(reg-layer,产生建议框的bounding box),另一个是 box-classification层(cls-layer,预测建议框是前景还是背景的概率。)
- 对每个滑动窗口,同时给出在原图上所对应的k个不同的建议框的预测(这k个建议框只是RPN初步给出的,还要经过RPN进一步筛选,再提供给后面的检测网络)。即reg层有4k的输出编码,对应k个建议框bounding box坐标。cls层输出2k的分数,用于估计每个建议框的目标/非目标概率【对于一幅 W×H 的feature map,对应 W×H 个滑动窗口,对应 W×H×k 个建议框】。
- 这k个region proposal是以k个事先手工(人为)定义的reference boxes(称作anchors,锚盒)为参照 得到的。这k个锚盒是以滑动窗口为中心,由 不同面积大小(scale),不同长宽比(aspect_ratio) 所确定的。
锚盒(anchor box)
Faster R-CNN使用了3组面积(128×128、256×256、512×512)、3组长宽比(1:1、1:2、2:1),共计 k=9 种anchor【① anchor的size是针对原图而言的;② 算法允许使用比感受域更大的锚框,参照于人类通过物体的部分区域粗略地推断出一个物体的整体范围】
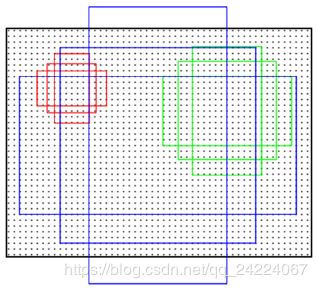
为什么每个滑动窗口要基于锚盒而非直接预测建议框?而且为什么要用k个?
- 图像中的候选区域大小和长宽比不同,直接回归比对锚盒坐标修正训练起来更困难。
- 使用锚盒也可以认为这是向神经网络引入先验知识的一种方式。我们可以根据数据中包围盒通常出现的形状和大小设定一组锚盒【比如高瘦的锚盒对应于人,而矮胖的锚盒对应于车辆】。
- conv5特征感受野很大,很可能该感受野内包含了不止一个目标,使用多个锚盒可以同时对感受野内出现的多个目标进行预测。
FPN
- 待后续整理补充
在FPN被提出之前,大多的检测器只对主干网络的最后一层进行检测。尽管层数越深的特征图包含的语义信息越丰富,但其不利于对目标的定位。为此,在FPN中开发了具有横向连接的自上而下的体系结构,用于构建各种规模的高级语义。

上图为目标检测中常用的主干网络结构,其中(d)为FPN的结构。可以看到FPN中每一层的特征图都是由上一层的特征图的上采样与对原始图像的同一层进行1×1卷积而成。这使得整个网络能获得不同尺度上的语义信息而不用对原图像进行多次采样(比如a)。自从在主干网络上采用了金字塔结构,FPN展现了其在尺度变化较大的目标中的优势。现在,FPN已经成为了许多最新检测器的基本模块。
小结:提高图像级别计算,降低区域级别计算
上面说过,基于候选区域的目标检测算法分两步:第一步是从图像中提取深度特征,第二步是对每个候选区域进行分类+定位。其中,第一步是图像级(image-level)计算,一张图像只需要计算一次,而第二步是区域级(region-level)计算,每个候选区域需要分别计算一次,占用了整体主要的计算开销。
R-CNN, Fast R-CNN, Faster R-CNN, R-FCN这些算法的演进思路是逐渐提高网络中图像级别计算的比例,同时降低区域级别计算的比例【即尽可能地共用CNN运算的结果】,来加快网络的计算速度【R-CNN中几乎所有的计算都是区域级别计算,而R-FCN中几乎所有的计算都是图像级别计算】。
One stage算法
one stage算法的发展历程如下图所示:
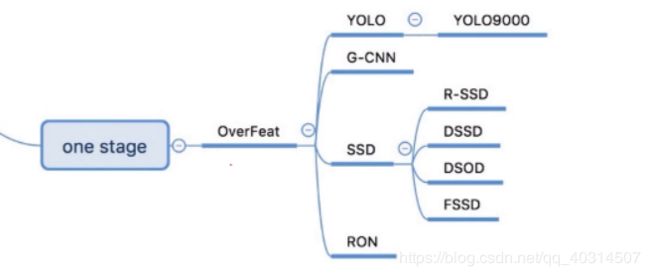
也叫作 基于直接回归的目标检测算法。
基于候选区域的方法由于有两步操作,虽然检测准确率比较高,但速度离实时仍有一些差距。基于直接回归的方法不需要基于候选区域,直接输出分类+定位结果。这类方法只需前馈网络一次,速度更快,可以满足实时检测的需求
YOLO系列
【目标检测框架】One-Stage框架:YOLO (You Only Look Once) 入门 详细解读
YOLO(You Only Look Once),由R.Joseph等人在2015提出,是 深度学习领域第一个one-stage detector。
作为一个one-stage检测方法,Yolo使用一个单独的CNN网络实现端到端 (end-to-end) 的目标检测任务【即一个网络直接同时预测bounding box和类别】,而且Yolo的训练过程也是端到端的。
yolo系列采用了 分而治之(即大分小,分别解决) 的思想。如下图所示,输入图片被划分为 S×S 个网格(grid),每个网格分别对 中心点落入当中的目标(object) 进行检测,输出k个bounding box【每个bounding box对应4维坐标 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)+置信度(confidence score)】,以及各类别的条件类别概率(conditional class probabilities)。

此后,作者又提出了YOLO的v2和v3版本,在检测精度和速度实现了飞跃性的进步。目前,YOLOv3得到了极为广泛的应用。
YOLO系列之yolo v2
yolo系列之yolo v3【深度解析】
SSD
- 待后续整理补充
SSD由W. Liu在2015年提出。它是深度学习时代的第二个一级检测器。 SS的主要贡献是引入了多参考和多分辨率检测技术(将在2.3.2节中介绍),从而显着提高了一级检测器的检测精度,尤其是对于某些小物体。SSD的优点是检测速度和准确性均达到了中间水平(VOC07 mAP = 76.8%)。,VOC12 mAP = 74.9%,COCO mAP @ .5 = 46.5%,快速版本的运行速度为59fps)。 SSD与以前的探测器之间的主要区别在于,前者可探测在网络的不同层上具有不同的规模的物体,而后者仅在其顶层上运行检测。
Two stage vs One stage
概述文章:
[1] 从RCNN到SSD,这应该是最全的一份目标检测算法盘点
[2] 目标检测综述
[3] 【目标检测 深度学习】1.目标检测算法基础介绍(对传统目标检测方法感兴趣的可以看一看)
最新进展:
[1] 基于深度学习的目标检测算法综述 (一) (二) (三)(对2013以来,除SSD,YOLO和R-CNN系列之外的,所有引用率相对较高或是笔者认为具有实际应用价值的论文的分类概括。)
[2] 目标检测-2019年4篇目标检测算法最佳综述