CDH大数据平台实施经验总结
1. 平台规划注意事项
1.1 业务数据全部存储在datanode上面,所以datanode的存储空间必须足够大,且每个datanode的存储空间尽量保持一致。
1.2 管理节点/namenode对存储空间要求不高,主要存储各计算节点datanode的元数据信息,以3个datanode为例,每个datanode存储2T的数据,namenode才耗费80G的空间。
1.3 由于Hadoop有数据副本机制,默认为3个副本,因此datanode节点,系统盘做raid 1,数据盘做raid 0;namenode做raid 5,不管系统盘还是数据盘,都可以直接更换,保证数据不丢失;
1.4 计算节点datanode依靠的是数量优势,除了存储空间足够大之外,对机器配置要求不高,但是安装Spark和impala的话对内存的要求较高,单节点2T的数据配置64G的单机内存有点吃力。
1.5 但是namenode要跟所有的datanode交互,接收处理各种请求,对机器配置要求较高,以的测试数据来看,namenode存放80G的元数据时,64G的内存已经有点紧张了,开始使用交换内存了。
1.6 namenode和Secondary namenode需要各自独立的两个节点,即相互独立部署,这样即使namenode机器挂了,也可以手动从secondary namenode恢复一下。在hadoop 2高可靠性下可以配置两个namenode,保证一个namenode出现问题可以自动切换至另一个。
1.7 由于secondary namenode的是周期性的合并日志文件,因此单独部署时对机器压力较小,空间使用也只勉强是namenode的一半,因此可以把诸如Hive/Hbase等的服务器端安装在snn所在的服务器上,这样可以使机器资源得到最大化利用。
1.8 hdfs空间不够开始报警,但是df –h命令下查看就会发现其实空间余额还有好几T,这种情况是由于non dfs used空间膨胀导致的,non dfs used和remaining一起构成了hdfs的可用空间容量,两者呈现此消彼长的关系。Non dfs used从字面理解来看是非Hadoop文件占用的空间,实际上是某些文件删除之后,hadoop的组件没有释放对其引用导致的,从的情况来看,单个节点2T的数据运行一个月会产生600G的non dfs used空间,最笨的办法就是重启CDH,一下子占用就到1G以下了。
2. docker中没有CDH运行环境
项目采取docker来发布、运行程序,Docker实例无状态,停止服务即销毁,无法直接安装软件,而程序采用命令行的方式编写,必须依赖CDH环境运行,两者出现矛盾,三种方案解决:
2.1.所有程序基于API来开发,改程序
未采用,一来程序改动量太大,影响里程碑计划;二来CDH的有些组件对命令行的支持比对API的支持要好,比如sqoop。
2.2.制作一个CDH的镜像,不改程序
未采用,需要开发人员重新部署、学习docker技术,测试程序,成本较大;
2.3.用jsch方式远程连接CDH节点来执行命令,改程序
已采用,程序改动量较小,半天即可完成,已测试通过
3. sqoop注意事项
3.1.Oracle中是区分用户的,一般给sqoop提供的账号都是oracle中的查询账号,通过同义词等形式来查询数据,所以sqoop命令中一定要带上用户,此用户跟Oracle提供给sqoop查询权限用户名不同(除非给sqoop提供的是生产库的业务原始账号,生产数据表都在此账号下面),sqoop命令中的账号是源数据表的owner用户,只有这样才能通过查询权限的用户去抽取同义词等模式的生产数据。
3.2.由于一般给sqoop提供的账号都是oracle中的查询账号,如果需要通过访问Oracle的数据字典来获取源数据表结构,请使用dba_开头的系统表,因为源数据表结构的信息是在业务表的owner用户下面的user_开头的系统表中才有,查询用户下面的user_表中没有。需要的dba_开头的表包括:dba_tab_comments,dba_cons_columns,dba_constraints,dba_ind_columns ,dba_tab_columns,dba_col_comments
3.3. sqoop命令中,源数据库为rac集群的情况下,连接数据库某个节点时,命令中Oracle IP、端口号、SID之间一律使用冒号,而不是斜杠,只有在非集群模式或者scan ip的情况下才可以使用斜杠。
3.4.sqoop成功执行需要驱动包,在以下目录添加2个jar包/opt/cloudera/parcels/CDH-5.5.2-1.cdh5.5.2.p0.4/lib/sqoop/lib:
MySQL-connector-Java-5.1.38-bin.jar
ojdbc14-10.2.0.4.jar
3.5.sqoop命令中并发参数 –m 属性,一定要放在table属性之后,否则命令无法识别
3.6.采用jsch远程调用模式时,在sqoop命令没有执行完成之前不能关闭远程连接,否则即使已经提交了yarn也会中断执行。
3.7.sqoop默认会把Oracle中number和date类型转换为double和string类型,需要在sqoop命令中指定一下类型的转换规则。
3.8 sqoop增量抽取时,where条件使用双引号而非单引号,在Java代码远程调用ssh时,尽量使用between and,否则必须得转义<、>才能使用。
3.9 sqoop先创建表,后插入数据时容易跟对应的字段错位,需要设置分隔符参数 –fields-terminated-by “\001”,另外插入数据的顺序一定要与创建表的字段的顺序一致。
5. spark与docker容器结合
5.1.在程序中采用URL方式连接Spark的master节点时必须用别名,IP地址无效。
5.2.应用部署于docker容器中,调用spark组件的时候应用会莫名的重启,后来排查发现是docker里需要维护hosts,不然 new javaSparkContext()会导致应用服务重启。但由于docker机制决定了,即使注册了也无法持久化存在,应用重启之后就还原了,所以直接在Java程序中完成,应用启动的时候注册到docker的hosts中。
5.3.应用部署于docker之中,调用spark组件的时候,spark的master和worker节点需要返回消息给sparkdriver,即需要访问部署应用的docker容器,如下图所示: 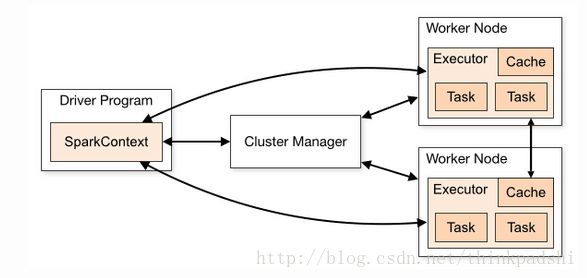
而docker的原有机制决定了,只能由部署于docker中的应用去访问集群中的物理节点,而外面的物理节点无法访问docker中的私网。
此外还有2个限制条件,第一:sparkdriver不支持映射地址和端口,必须是应用程序所在的IP;第二:docker容器的私网地址随着应用重启而在某个网段变化,如果固定为物理IP,将无限制的浪费物理IP地址,客户不会同意;
最终通过开启docker服务器的路由转发功能,在spark的master和worker节点上配置静态的路由信息得以实现由物理IP节点去访问docker容器内部的私网地址的功能,也就是说开启docker服务器的路由转发功能之后,其他机器发往172私网号段的请求,全部发给docker服务器。
命令:ip route add <目标网段>/<掩码> via
6. hive操作注意事项
6.1 hive中sql没有像Oracle那样进行自动优化,sql的优化非常重要,比如:同一业务逻辑,采用join方式一分钟搞定,但是如果采用等值连接的方式,2小时都没出结果。
6.2 Hive中不支持join…on…or的形式,可以转换成union all的方式,此外hive也不支持on后面不相等的条件,只支持相等条件。
6.3 hive的存储方式一般有textfile、sequencefile、rcfile等三种,其中textfile即是文本格式,hive的默认存储格式,数据不做压缩,磁盘开销大,数据解析开销大,查询的效率最低,可以直接存储,但加载数据的效率最高;sequencefile,是Hadoop提供的一种二进制文件格式是Hadoop支持的标准文件格式,可压缩、可切片,查询效率高,但需要通过text文件转化来加载;TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的,而rcfile 是一种行列存储相结合的存储方式,先将数据按行分块再按列式存储,保证同一条记录在一个块上,避免读取多个块,有利于数据压缩和快速进行列存储,具备相当于行存储的数据加载和负载适应能力,扫描表时避免不必要的列读取,而使用列维度的压缩,能有效提升存储空间利用率,因此存储空间最小,查询的效率最高 ,但需要通过text文件转化来加载,加载的速度最低,但是由于hdfs一般都是一次写入多次读取,所以加载的速度较慢可以接受;目前大数据平台中hive的存储格式采用的是普通的textfile,后续还有很大的优化提示空间。
7. CM管理页面操作
7.1 有组件报错或者无法启动时,先查看相应日志,如果error的地方是关于时间的,ntp同步服务器时间,然后重启该组件;如果error的地方是关于客户端连接问题的,重启hostMonitor服务,如果不行就重启agent服务;绝大多数情况下通过上述两步就可成功,极少数情况下,那就删除角色重新添加该服务,必要的时候可以调整一下该服务的各种角色所在的节点位置。
7.2 如果服务器硬盘故障更换硬盘之后,各种组件启动报错,提示无法连接到cm,如果重启hostMonitor服务无效的话,可以先把该节点移除出服务器,然后配置角色模板,再添加进集群中来。
7.3 CM主机页面中会时常显示物理内存还有剩余,但是交换内存却用了好多,导致CDH报警;这个从Linux机制的角度来看,可以忽略不管,linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么需要内存,Linux也会交换出暂时不用的内存页面,这样的可以避免等待交换所需的时间。如果非要消除这个报警,那就调整linux中swappiness参数的值为0即可。