Centos7 Ceph 存储集群搭建
一、Ceph简介
1.1 Ceph的主要特点:
统一存储
无任何单点故障
数据多份冗余
存储容量可扩展
自动容错及故障自愈
1.2 Ceph三大角色组件及其作用
在Ceph存储集群中,包含了三大角色组件,他们在Ceph存储集群中表现为3个守护进程,分别是Ceph OSD、Monitor、MDS。当然还有其他的功能组件,但是最主要的是这三个。
Ceph OSD:
Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
Monitor:
Ceph的Monitor守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map、PG(Placement Group) map、CRUSH map。 这些映射是Ceph守护进程之间相互协调的关键簇状态。 监视器还负责管理守护进程和客户端之间的身份验证。 通常需要至少三个监视器来实现冗余和高可用性。
MDS:
Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力。
Managers:
Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
Ceph的术语表:http://docs.ceph.com/docs/master/glossary/#term-ceph-storage-cluster
1.3 Ceph的架构及应用场景
文档连接:http://docs.ceph.com/docs/master/architecture/
Ceph的架构主要分成底层数据分布及上层应用接口,下面是官网架构图:
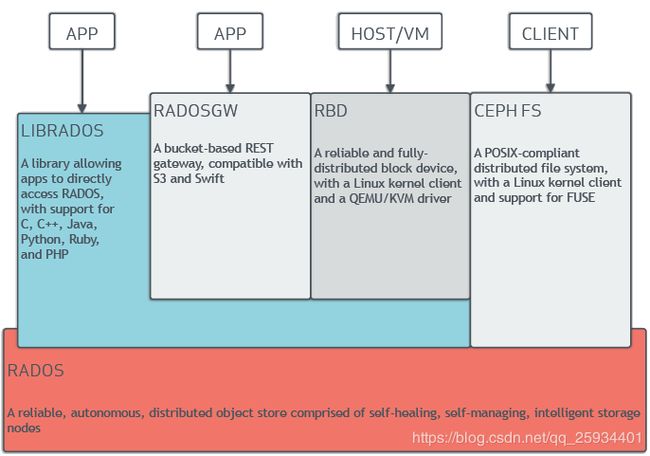
A library…and PHP #LIBRADOS库允许应用程序可以直接访问Ceph底层的对象存储,它支持的有C、C++、Java、Python、Ruby及PHP语言。
A bucket-based…and Swift #一套基于RESTful协议的网关,并兼容S3和Swift。
A reliable…QEMU/KVM driver #通过Linux内核客户端及QEMU/KVM驱动,来提供一个可靠且完全分布的块设备。
A POSIX-compliant…for FUSE #通过Linux内核客户端结合FUSE,来提供一个兼容POSIX文件结构系统。
A reliable,autonomous…storage nodes #以其具备的自愈功能、自管理、智能存储节点特性,来提供一个可靠、自动、分布式的对象存储。
Ceph的底层核心是RADOS(Reliable, Autonomic Distributed Object Store),Ceph的本质是一个对象存储。RADOS由两个组件组成:OSD和Monitor。OSD主要提供存储资源,每一个disk、SSD、RAID group或者一个分区都可以成为一个OSD,而每个OSD还将负责向该对象的复杂节点分发和恢复;Monitor维护Ceph集群并监控Ceph集群的全局状态,提供一致性的决策。
RADOS分发策略依赖于名为CRUSH(Controlled Replication Under Scalable Hashing)的算法(基于可扩展哈希算法的可控复制)
应用场景:
Ceph的应用场景主要由它的架构确定,Ceph提供对象存储、块存储和文件存储,主要由4种应用:
第一类:LIBRADOS应用
通俗的说,Librados提供了应用程序对RADOS的直接访问,目前Librados已经提供了对C、C++、Java、Python、Ruby和PHP的支持。它支持单个单项的原子操作,如同时更新数据和属性、CAS操作,同时有对象粒度的快照操作。它的实现是基于RADOS的插件API,也就是在RADOS上运行的封装库。
第二类:RADOSGW应用
这类应用基于Librados之上,增加了HTTP协议,提供RESTful接口并且兼容S3、Swfit接口。RADOSGW将Ceph集群作为分布式对象存储,对外提供服务。
第三类:RBD应用
这类应用也是基于Librados之上的,细分为下面两种应用场景。
第一种应用场景为虚拟机提供块设备。通过Librbd可以创建一个块设备(Container),然后通过QEMU/KVM附加到VM上。通过Container和VM的解耦,使得块设备可以被绑定到不同的VM上。
第二种应用场景为主机提供块设备。这种场景是传统意义上的理解的块存储。
以上两种方式都是将一个虚拟的块设备分片存储在RADOS中,都会利用数据条带化提高数据并行传输,都支持块设备的快照、COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。
第四类:CephFS(Ceph文件系统)应用
这类应用是基于RADOS实现的PB级分布式文件系统,其中引入MDS(Meta Date Server),它主要为兼容POSIX文件系统提供元数据,比如文件目录和文件元数据。同时MDS会将元数据存储在RADOS中,这样元数据本身也达到了并行化,可以大大加快文件操作的速度。MDS本身不为Client提供数据文件,只为Client提供对元数据的操作。当Client打开一个文件时,会查询并更新MDS相应的元数据(如文件包括的对象信息),然后再根据提供的对象信息直接从RADOS中得到文件数据。**
二、Ceph部署安装
1.环境、软件准备
本次演示环境,我是在虚拟机 Linux Centos7 上操作,通过虚拟机完成存储集群搭建,以下是安装的软件及版本:
Centos:release 7.4.1708 (Core)
Ceph:jewel-10.2.10
Openssh-server:version 7.4
NTP
注意: 这篇文章只涉及 Ceph 存储集群搭建过程,不在详细阐述 Ceph 的体系架构,以及各个组件的详细情况,具体可参考 官方系统结构 中有详细描述文档。Ceph 官方文档 中建议安装一个 ceph-deploy 管理节点和一个三节点的 Ceph 存储集群来研究 Ceph 的基本特性,结构图如下:
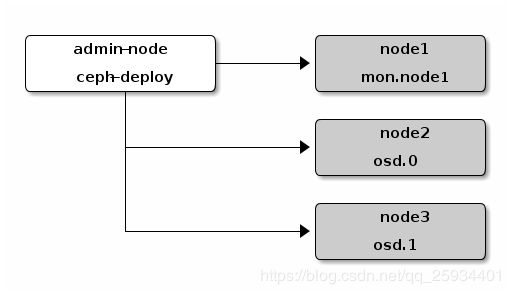
Ceph 分布式存储集群有三大组件组成,分为:Ceph Monitor、Ceph OSD、Ceph MDS,后边使用对象存储和块存储时,MDS 非必须安装,只有当使用 Cephfs 文件存储时,才需要安装。这里我们暂时不安装 MDS。
2.Ceph 预检
2.1 配置节点Host
为了方便后边安装,以及 ssh 方式连接各个节点,我们先修改一下各个节点的 Hostname 以及配置 Hosts 如下:
admin-node节点 (10.100.101.193) 主机名为master01
[cephd@node01 ceph-cluster]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.100.101.190 node01
10.100.101.191 node02
10.100.101.192 node03
10.100.101.193 master01
node节点(10.100.101.190)主机名为node01
[cephd@node02 root]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.100.101.190 node01
10.100.101.191 node02
10.100.101.192 node03
10.100.101.193 master01
node节点(10.100.101.191)主机名为node02
[cephd@node02 root]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.100.101.190 node01
10.100.101.191 node02
10.100.101.192 node03
10.100.101.193 master01
node节点(10.100.101.193)主机名为node03
[cephd@node02 root]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.100.101.190 node01
10.100.101.191 node02
10.100.101.192 node03
10.100.101.193 master01
2.2 安装部署工具 ceph-deploy
Ceph 提供了部署工具 ceph-deploy 来方便安装 Ceph 集群,我们只需要在 ceph-deploy 节点上安装即可,这里对应的就是 admin-node 节点。把 Ceph 仓库添加到 ceph-deploy 管理节点,然后安装 ceph-deploy。因为系统是 Centos7 版本,所以配置如下:
ceph-deploy (admin-node) 上执行
# yum 配置其他依赖包
$ sudo yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && rm /etc/yum.repos.d/dl.fedoraproject.org*
# 添加 Ceph 源
$ vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://download.ceph.com/rpm-jewel/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-jewel/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-jewel/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
安装 ceph-deploy
$ sudo yum update && sudo yum install ceph-deploy
2.3 安装 NTP 和 Openssh(all node install)
官方建议在所有 Ceph 节点上安装 NTP 服务(特别是 Ceph Monitor 节点),以免因时钟漂移导致故障
# yum 安装 ntp
yum install ntp ntpdate ntp-doc
# 校对系统时钟
ntpdate 0.cn.pool.ntp.org
后续操作,ceph-deploy 节点需要使用 ssh 方式登录各个节点完成 ceph 安装配置工作,所以要确保各个节点上有可用 SSH 服务。
2.4 创建 Ceph 部署用户
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。官方建议所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,而且不要使用 ceph 这个名字。这里为了方便,我们使用 cephd 这个账户作为特定的用户,而且每个节点上(admin-node、node0、node1)上都需要创建该账户,并且拥有 sudo 权限。
在 Ceph 集群各节点进行如下操作
# 创建 ceph 特定用户
# useradd -d /home/cephd -m cephd
# echo cephd | passwd cephd --stdin
# 添加 sudo 权限
# echo "cephd ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephd
# chmod 0440 /etc/sudoers.d/cephd
接下来在 ceph-deploy 节点(admin-node)上,切换到 cephd 用户,生成 SSH 密钥并把其公钥分发到各 Ceph 节点上,注意使用 cephd 账户生成,且提示输入密码时,直接回车,因为它需要免密码登录到各个节点。
ceph-deploy (master01) 上执行
# 生成 ssh 密钥
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/cephd/.ssh/id_rsa):
Created directory '/home/cephd/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/cephd/.ssh/id_rsa.
Your public key has been saved in /home/cephd/.ssh/id_rsa.pub.
The key fingerprint is:
...
# 将公钥复制到 node01 节点
$ ssh-copy-id node01
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cephd/.ssh/id_rsa.pub"
The authenticity of host 'node0 ()' can't be established.
ECDSA key fingerprint is MD5:3c:e0:a7:a0:e6:3c:dc:c0:df:28:dc:87:16:2d:0f:c6.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
cephd@node0's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'cephd@node01'"
and check to make sure that only the key(s) you wanted were added.
# 将公钥复制到 node02 节点
$ ssh-copy-id node02
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cephd/.ssh/id_rsa.pub"
The authenticity of host 'node1 ()' can't be established.
ECDSA key fingerprint is MD5:3c:e0:a7:a0:e6:3c:dc:c0:df:28:dc:87:16:2d:0f:c6.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
cephd@node1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'cephd@node02'"
and check to make sure that only the key(s) you wanted were added.
# 将公钥复制到 node03 节点
$ ssh-copy-id node03
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cephd/.ssh/id_rsa.pub"
The authenticity of host 'node03 ' can't be established.
ECDSA key fingerprint is MD5:3c:e0:a7:a0:e6:3c:dc:c0:df:28:dc:87:16:2d:0f:c6.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
cephd@node0's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'cephd@node03'"
and check to make sure that only the key(s) you wanted were added.
复制完毕,测试一下在 ceph-deploy 管理节点免密码登录各个节点。
$ ssh node01
Last login: Fri Dec 8 15:50:08 2017 from admin
$ ssh node02
Last login: Fri Dec 8 15:49:27 2017 from admin
测试没有问题,接下来,修改 ceph-deploy 管理节点上的 ~/.ssh/config 文件,这样无需每次执行 ceph-deploy 都要指定 –username cephd 。这样做同时也简化了 ssh 和 scp 的用法
[cephd@master01 ceph-cluster]$ cat ~/.ssh/config
Host master01
Hostname master01
User root
Host node01
Hostname node01
User root
Host node02
Hostname node02
User root
Host node03
Hostname node03
User root
注意,此时再执行 ssh node0 会提示报错 Bad owner or permissions on /home/cephd/.ssh/config。原因是 config 文件权限问题,修改权限 sudo chmod 600 config 即可解决。
2.5 其他网络配置
官网文档中指定 Ceph 的各 OSD 进程通过网络互联并向 Monitors 上报自己的状态,所以要保证网络为开启状态,不过某些发行版(如 CentOS )默认关闭网络接口。所以我们需要保证集群各个节点系统网络接口是开启的。
在 Ceph 集群各节点进行如下操作
$ sudo cat /etc/sysconfig/network-scripts/ifcfg-enp0s3
TYPE="Ethernet"
BOOTPROTO="dhcp"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp0s3"
UUID="3e68d5a3-f9a6-4c83-9969-706f7e3b0bc2"
DEVICE="enp0s3"
ONBOOT="yes" # 这里要设置为 yes
注意:这里因为在我安装的虚拟机集群中网卡为 enp0s3,所以需要修改 /etc/sysconfig/network-scripts/ifcfg-enp0s3文件,请根据自己系统网卡名去修改对应配置文件。
SELINUX 设置,在 CentOS 系统上, SELinux 默认为 Enforcing 开启状态,为了方便安装,建议把 SELinux 设置为Permissive或者 disabled。
在 Ceph 集群各节点进行如下操作
# 临时生效设置
# setenforce 0
# 永久生效设置
# cat /etc/selinux/config
SELINUX=disabled # 这里设置为 Permissive | disabled
SELINUXTYPE=targeted
开放所需端口设置,Ceph Monitors 之间默认使用 6789 端口通信, OSD 之间默认用 6800:7300 这个范围内的端口通信,所以我们需要调整防火墙设置,开放所需端口,允许相应的入站请求。
# 防火墙设置
# firewall-cmd --zone=public --add-port=6789/tcp --permanent
# 当然我们也可以关闭防火墙
#停止 firewall
# systemctl disable firewalld.service #禁止 firewall 开机启动
3、Ceph 存储集群搭建
好了,经过上边一系列的预检设置后,我们就可以开始 Ceph 存储集群搭建了,集群结构为 node01 (ceph-deploy、Monitor)、node01(osd.0)、node02(osd.1)。首先要提一下的是,如果我们在安装过程中出现了问题,需要重新操作的时候,例如想清理我搭建的这个集群的话,可以使用以下命令。
ceph-deploy (master01) 上执行
清理配置
ceph-deploy purgedata master01 node01 node02 node03
ceph-deploy forgetkeys
# 清理 Ceph 安装包
ceph-deploy purge master01 node01 node02 node03
好了,现在开始搭建。首先 Cephd 用户创建一个目录 ceph-cluster 并进入到该目录执行一系列操作。因为我们设计的 monitor 节点在 admin-node 节点上,所以,执行如下命令。
# 创建执行目录
# su - cephd
# mkdir /home/cephd/ceph-cluster && cd /home/cephd/ceph-cluster
# 创建集群 mon节点
# ceph-deploy new node01 node02 node03 #多个mon节点 集群方式
遇到的问题:
CentOS 7 quick start fails with RuntimeError: NoSectionError: No section: ‘ceph’
解决:sudo mv /etc/yum.repos.d/ceph.repo /etc/yum.repos.d/ceph-deploy.repo
RuntimeError: connecting to host: node03 resulted in errors: IOError cannot send (already closed?)
解决:
sudo:抱歉,您必须拥有一个终端来执行 sudo
sed -i ‘s/Defaults\ requiretty/#Defaults\ requiretty/g’ /etc/sudoers
此时,我们会发现 ceph-deploy 会在 ceph-cluster 目录下生成几个文件,ceph.conf 为 ceph 配置文件,ceph-deploy-ceph.log 为 ceph-deploy 日志文件,ceph.mon.keyring 为 ceph monitor 的密钥环。
$ ll ceph-cluster
-rw-rw-r--. 1 cephd cephd 196 12月 7 14:46 ceph.conf
-rw-rw-r--. 1 cephd cephd 3694 12月 7 14:46 ceph-deploy-ceph.log
-rw-------. 1 cephd cephd 73 12月 7 14:46 ceph.mon.keyring
$ cat ceph.conf
[global]
fsid = 38698671-7f74-4182-a5be-142dfe0e4461
mon_initial_members = node01, node02, node03
mon_host = 10.100.101.190,10.100.101.191,10.100.101.192
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
接下来,我们需要修改下 ceph.conf 配置文件,增加副本数为 2,因为我们有两个 osd 节点。
[cephd@master01 ceph-cluster]$ cat ceph.conf
[global]
fsid = 38698671-7f74-4182-a5be-142dfe0e4461
mon_initial_members = node01, node02, node03
mon_host = 10.100.10.190,10.100.10.191,10.100.10.192
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2 #增加默认副本数为 2
osd max object name len = 256
osd max object namespace len = 64
osd max object name len 和 osd max object namespace len 使用ext4格式时使用,详情 -->Ceph osd启动报错osd init failed (36) File name too long
然后,我们需要通过 ceph-deploy 在各个节点安装 ceph。
ceph-deploy install master01 node01 node02 node03
此过程需要等待一段时间,因为 ceph-deploy 会 SSH 登录到各 node 上去,依次执行安装 ceph 依赖的组件包。
漫长的等待安装完毕之后,接下来需要初始化 monitor 节点并收集所有密钥。
# ceph-deploy mon create-initial
...
ceph_deploy.mon][ERROR ] RuntimeError: config file /etc/ceph/ceph.conf exists with different content; use --overwrite-conf to overwrite
[ceph_deploy][ERROR ] GenericError: Failed to create 1 monitors
...
执行过程中报错了。查看原因应该是已经存在了 /etc/ceph/ceph.conf 配置文件了,解决方案就是加上 --overwrite-conf 参数,覆盖已存在的配置。
# ceph-deploy --overwrite-conf mon create-initial
执行完毕后,会在当前目录下生成一系列的密钥环,应该是各组件之间访问所需要的认证信息吧。
$ ll ~/ceph-cluster
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-mds.keyring
-rw-------. 1 cephd cephd 71 12月 7 15:13 ceph.bootstrap-mgr.keyring
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-osd.keyring
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-rgw.keyring
-rw-------. 1 cephd cephd 129 12月 7 15:13 ceph.client.admin.keyring
-rw-rw-r--. 1 cephd cephd 222 12月 7 14:47 ceph.conf
-rw-rw-r--. 1 cephd cephd 120207 12月 7 15:13 ceph-deploy-ceph.log
-rw-------. 1 cephd cephd 73 12月 7 14:46 ceph.mon.keyring
到此,ceph monitor 已经成功启动了。接下来需要创建 OSD 了,OSD 是最终数据存储的地方,这里我们准备了两个 OSD 节点,分别为 osd.0 和 osd.1。官方建议为 OSD 及其日志使用独立硬盘或分区作为存储空间,也可以使用目录的方式创建
给node01,node02,node03 分别添加一块硬盘40G,创建分区/dev/sdb1,格式化为ext4 文件系统
root@node03:~# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0xe5f14ca9.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
Command (m for help): p
Disk /dev/sdb: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders, total 16777216 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xe5f14ca9
Device Boot Start End Blocks Id System
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
Using default value 1
First sector (2048-16777215, default 2048): 2048
Last sector, +sectors or +size{K,M,G} (2048-16777215, default 16777215): 16000000
Command (m for help): p
Disk /dev/sdb: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders, total 16777216 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xe5f14ca9
Device Boot Start End Blocks Id System
/dev/sdb1 2048 16000000 7998976+ 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
root@node03:~# mkfs.xfs /dev/sdb1
meta-data=/dev/sdb1 isize=256 agcount=4, agsize=499936 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=1999744, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
OSD节点执行:
chown -R ceph:ceph /dev/sdb1
注意:这里执行了 chown -R ceph:ceph操作,将 osd0 和 osd1 目录的权限赋予 ceph:ceph,否则,接下来执行ceph-deploy osd activate… 时会报权限错误。
接下来,我们需要 ceph-deploy 节点执行 prepare OSD 操作,目的是分别在各个 OSD 节点上创建一些后边激活 OSD 需要的信息。
sudo ceph-deploy --overwrite-conf osd prepare node01:/osd node02:/osd node03:/osd
OK 接下来,我们需要激活 activate OSD
sudo ceph-deploy osd activate node01:/osd node02:/osd node03:/osd
看日志,激活也没有问题,最后一步,通过 ceph-deploy admin 将配置文件和 admin 密钥同步到各个节点,以便在各个 Node 上使用 ceph 命令时,无需指定 monitor 地址和 ceph.client.admin.keyring 密钥。
$ ceph-deploy admin node01 node02 node03
同时为了确保对 ceph.client.admin.keyring 有正确的操作权限,所以还需要增加权限设置。
$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
至此,Ceph 存储集群已经搭建完毕了,我们可以查看那一下集群是否启动成功!
[root@node01 data]# ceph -s
cluster 38698671-7f74-4182-a5be-142dfe0e4461
health HEALTH_OK
monmap e1: 3 mons at {node01=10.100.10.190:6789/0,node02=10.100.10.191:6789/0,node03=10.100.10.192:6789/0}
election epoch 6, quorum 0,1,2 node01,node02,node03
osdmap e14: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v26: 64 pgs, 1 pools, 0 bytes data, 0 objects
15815 MB used, 2787 GB / 2952 GB avail
64 active+clean
#集群健康监测
$ ceph health
HEALTH_OK
# 查看集群 OSD 信息
$ ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.06400 root default
-2 0.03200 host node0
0 0.03200 osd.0 up 1.00000 1.00000
-3 0.03200 host node1
1 0.03200 osd.1 up 1.00000 1.00000
解决HEALTH_WARN
[root@ceph6 ceph]# ceph osd pool set rbd pg_num 128
[root@ceph6 ceph]# ceph -s
cluster 8ea4fa79-3b6b-4de3-8cfb-a0922d6827c5
health HEALTH_OK
monmap e1: 1 mons at {ceph6=192.168.103.139:6789/0}
election epoch 3, quorum 0 ceph6
osdmap e48: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v130: 128 pgs, 1 pools, 0 bytes data, 0 objects
309 MB used, 134 GB / 134 GB avail
128 active+clean