神经网络结构在命名实体识别(NER)中的应用
from: http://www.cnblogs.com/robert-dlut/p/6847401.html
近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展。作为NLP领域的基础任务—命名实体识别(Named Entity Recognition,NER)也不例外,神经网络结构在NER中也取得了不错的效果。最近,我也阅读学习了一系列使用神经网络结构进行NER的相关论文,在此进行一下总结,和大家一起分享学习。
1 引言
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图。它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的基础。

NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
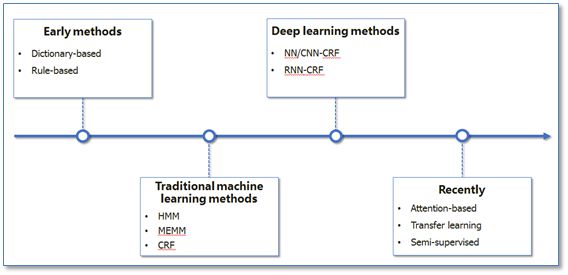
在基于机器学习的方法中,NER被当作是序列标注问题。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列之间是有强相互依赖关系的。例如,使用BIO标签策略进行NER时,正确的标签序列中标签O后面是不会接标签I的。
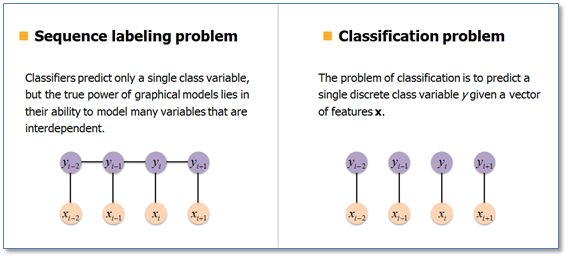
在传统机器学习中,条件随机场(Conditional Random Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用维特比算法进行解码。

在传统机器学习方法中,常用的特征如下:

接下里我们重点看看如何使用神经网络结构来进行NER 。
2 NER中主流的神经网络结构
2.1 NN/CNN-CRF模型
《Natural language processing (almost) from scratch》是较早使用神经网络进行NER的代表工作之一。在这篇论文中,作者提出了窗口方法与句子方法两种网络结构来进行NER。这两种结构的主要区别就在于窗口方法仅使用当前预测词的上下文窗口进行输入,然后使用传统的NN结构;而句子方法是以整个句子作为当前预测词的输入,加入了句子中相对位置特征来区分句子中的每个词,然后使用了一层卷积神经网络CNN结构。
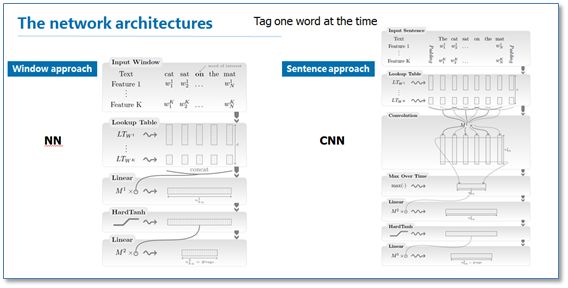
在训练阶段,作者也给出了两种目标函数:一种是词级别的对数似然,即使用softmax来预测标签概率,当成是一个传统分类问题;另一种是句子级别的对数似然,其实就是考虑到CRF模型在序列标注问题中的优势,将标签转移得分加入到了目标函数中。后来许多相关工作把这个思想称为结合了一层CRF层,所以我这里称为NN/CNN-CRF模型。

在作者的实验中,上述提到的NN和CNN结构效果基本一致,但是句子级别似然函数即加入CRF层在NER的效果上有明显提高。
2.2 RNN-CRF模型
借鉴上面的CRF思路,在2015年左右出现了一系列使用RNN结构并结合CRF层进行NER的工作。代表工作主要有:

将这些工作总结起来就是一个RNN-CRF模型,模型结构如下图:
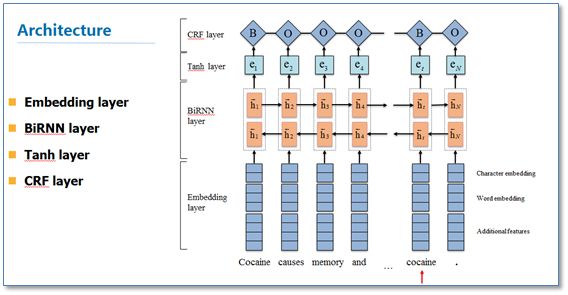
它主要有Embedding层(主要有词向量,字符向量以及一些额外特征),双向RNN层,tanh隐层以及最后的CRF层构成。它与之前NN/CNN-CRF的主要区别就是他使用的是双向RNN代替了NN/CNN。这里RNN常用LSTM或者GRU。实验结果表明RNN-CRF获得了更好的效果,已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
3 最近的一些工作
最近的一年在基于神经网络结构的NER研究上,主要集中在两个方面:一是使用流行的注意力机制来提高模型效果(Attention Mechanism),二是针对少量标注训练数据进行的一些研究。
3.1 Attention-based
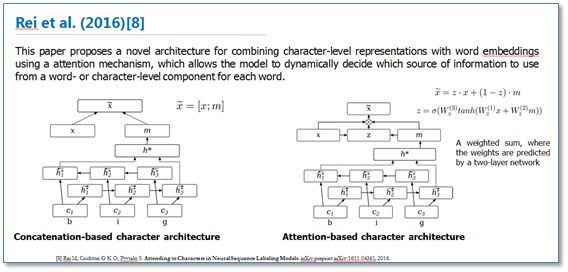
《Attending to Characters in Neural Sequence Labeling Models》该论文还是在RNN-CRF模型结构基础上,重点改进了词向量与字符向量的拼接。使用attention机制将原始的字符向量和词向量拼接改进为了权重求和,使用两层传统神经网络隐层来学习attention的权值,这样就使得模型可以动态地利用词向量和字符向量信息。实验结果表明比原始的拼接方法效果更好。
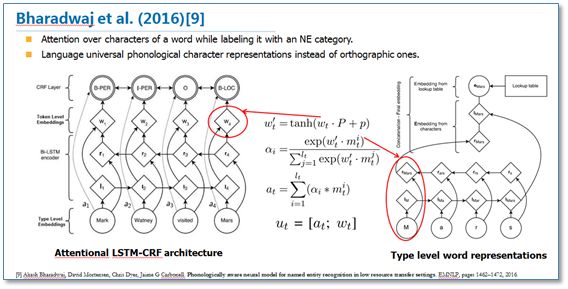
另一篇论文《Phonologically aware neural model for named entity recognition in low resource transfer settings》,在原始BiLSTM-CRF模型上,加入了音韵特征,并在字符向量上使用attention机制来学习关注更有效的字符,主要改进如下图。
3.2 少量标注数据
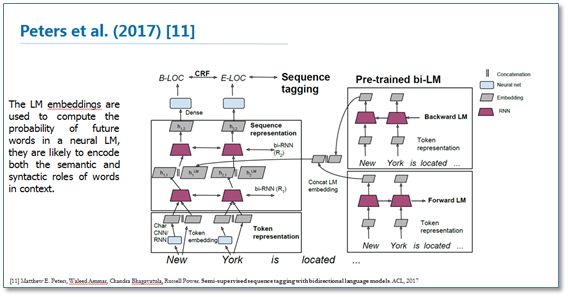
对于深度学习方法,一般需要大量标注数据,但是在一些领域并没有海量的标注数据。所以在基于神经网络结构方法中如何使用少量标注数据进行NER也是最近研究的重点。其中包括了迁移学习《Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks》和半监督学习。这里我提一下最近ACL2017刚录用的一篇论文《Semi-supervised sequence tagging with bidirectional language models》。该论文使用海量无标注语料库训练了一个双向神经网络语言模型,然后使用这个训练好的语言模型来获取当前要标注词的语言模型向量(LM embedding),然后将该向量作为特征加入到原始的双向RNN-CRF模型中。实验结果表明,在少量标注数据上,加入这个语言模型向量能够大幅度提高NER效果,即使在大量的标注训练数据上,加入这个语言模型向量仍能提供原始RNN-CRF模型的效果。整体模型结构如下图:
4 总结
最后进行一下总结,目前将神经网络与CRF模型相结合的NN/CNN/RNN-CRF模型成为了目前NER的主流模型。我认为对于CNN与RNN,并没有谁占据绝对的优势,各自有相应的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字符向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。

参考文献
[1] Lafferty J, McCallum A, Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
[2] Sutton C, McCallum A. An introduction to conditional random fields. Foundations and Trends® in Machine Learning, 2012, 4(4): 267-373.
[3] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 2011, 12(Aug): 2493-2537.
[4] Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition. Proceedings of NAACL-HLT. 2016: 260-270.
[5] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv:1508.01991, 2015.
[6] Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354, 2016.
[7] Chiu J P C, Nichols E. Named entity recognition with bidirectional LSTM-CNNs. arXiv preprint arXiv:1511.08308, 2015.
[8] Rei M, Crichton G K O, Pyysalo S. Attending to Characters in Neural Sequence Labeling Models. arXiv preprint arXiv:1611.04361, 2016.
[9] Akash Bharadwaj, David Mortensen, Chris Dyer, Jaime G Carbonell. Phonologically aware neural model for named entity recognition in low resource transfer settings. EMNLP, pages 1462–1472, 2016.
[10] Yang Z, Salakhutdinov R, Cohen W W. Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks. ICLR, 2017.
[11] Matthew E. Peters, Waleed Ammar, Chandra Bhagavatula, Russell Power. Semi-supervised sequence tagging with bidirectional language models. ACL, 2017.
作者:陈海斌
链接:https://zhuanlan.zhihu.com/p/46864074
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
目录
•A Survey on Recent Advances in Named Entity Recognition from Deep Learning models(2018 COLING)
•A FOFE-based Local Detection Approach for Named Entity Recognition and Mention Detection(2017 ACL)
•Attending to Characters in Neural Sequence Labeling Models(2016 COLING)
•Neural Architectures for Fine-grained Entity Type Classification (2017 ACL)
•Improving Neural Fine-Grained Entity Typing with Knowledge Attention(2018 AAAI)
•Chinese NER Using Lattice LSTM(2018 ACL)
•Semi-supervised sequence tagging with bidirectional language models(2017 ACL)
•Deep Active Learning for Named Entity Recognition(2018 ICLR)
•GAN…(2018 AAAI 2018 ACL)
1.A Survey on Recent Advances in Named Entity Recognition from Deep Learning models(2018COLING)
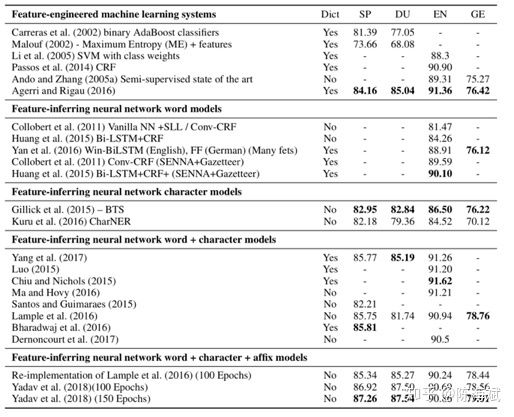
这篇文章是今年的综述,表中数据为经典数据COLING2003的F1值。以EN为例,第一部分为CRF+特征工程,在各种特征工程怼到了90左右,二三部分分别为只以词和只以字符做为嵌入向量,F1值大概为85。第四部分为词向量和字符向量进行拼接后效果有了很大的提升。最后为加入CNN等模型进一步提取前后缀特征。
2.A FOFE-based Local Detection Approach for Named Entity Recognition and Mention Detection(2017ACL)
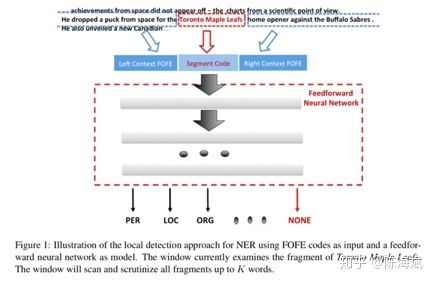
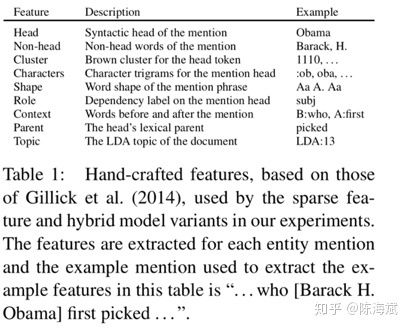
1.FOFE编码方法:对于所有长度 α为从左到右编码的遗忘因子,et为one-hot向量,zt为该部分编码,维度为整个词典大小 由原论文证明该编码是唯一的且不会损失信息 例子:ABCBC编码为 [α4,α+α3,1+α2] 过程:A [1,0,0] B[0,1,0] C[0,0,1]。 从左到右编码:[1,0,0] [α,1,0] [α2,α,1] [α3,α2+1,α] [α4,α3+α,1+α2] 总结:从左到右带有遗忘因子的单向解码 2.类似CBOW用2个矩阵映射到低维向量 3.低维向量维度确定,通过3层神经网络softmax输出分类 训练过程对模型的补充: 1.加入字符级特征:把已知实体的逐个字符进行双向FOFE编码,用矩阵映射到低维,加入神经网络(应该是只有训练时才用到) 2.softmax输出分类为正确的标签和NONE(忽略部分匹配) 3.若不想出现实体嵌套或重叠,可直接选择出现分数更高或长度更长的,也可保留嵌套特征,这在序列标注模型是难以做到的(优点1) 4.保留大小写...下采样平衡实体和非实体数量… 对模型的解释和其他优点 1.类似人类寻找实体的过程,关注NER整体和周围上下文特征,实体内部的关联相对较少,实体和实体间序列上的依赖也相对较少 2.无特征工程,未完全标注的训练集也可以(序列标注未完全标注的话效果会很差) 3.训练使用3层神经网络简单快速 效果:接近state of art gaz为地名索引、cap为大小写特征、pos序列标注特征 未来工作:句法分析等其他层面的应用 总结:暴力穷举句子的所有窗口、编码、映射、softmax 输出的软匹配(没有用到上下文的“硬”输出信息) 只有窗口居然做到了比较好的效果,这与传统序列标注的逐个词输出思路完全不同 并且跳过了分词,中文序列标注问题也受分词很大的影响 这篇相对比较简单,查字符和词向量拼接时注意到的 模型上半部分:经典模型 作者的解释是lstm隐层输出后再进行d层映射的效果更好,可以捕捉到“更高层”特征且压缩维度 embedding部分 h1和ht进行拼接作为字符向量,与词向量进行拼接/attention Attention部分: 这里的attention为经典attention模型的第三种公式,x和m之间是没有交互的,添加了三个W矩阵而已,交互放在了损失函数。E为softmax输出的交叉熵。 对于out-of-vocabulary的词来说,通过cos值使得字符向量和词向量更加接近。作者在这里解释是对于训练语料未出现的词,词向量的结果还是值得字符向量去接近的,反之则效果不佳 作者的其他解释: 1.优点在于处理OOV词时可以平衡词向量和字符向量的权重,也可以提取部分前后缀特征 2.参数量少了,相对于concat,attention部分的z维度更小 背景:对文本句子中的特定实体(实体已知种类未知)给出基于上下文文本信息的精细的分类信息 关注点:实体特征提取 和CRF的特征工程差不多 合并入模型的方式:拼接进去(vf) 特征调整方式: 重新编码、剪枝、某些特征重新分类 最后编码出只包含0、1的vf向量 实体向量:特征提取拼接词向量 Attention:两边的全局selfattention 这是本文提到的第一种人工特征加入方式:单独训练其他特征,拼接入模型 加入方式二:知识库、知识图谱引 改进点:避免分词按字符输入,用预训练实体库(建立字索引)显性地利用词和词序信息,通过门控单元从词典中自动找到可能的词 以“南京市”绿色LSTM为例:b为开始位置,e为结束位置 这里和传统LSTM相同,只是砍掉了输出层 每个都是长度为3的LSTM,南、南京市的字典索引、两个字长度后的市字,保留的是记忆信息(南+南京市) 对于市字的隐层单元:原本的双向LSTM输入+所有索引词的LSTM隐层输入 效果:部分语料state of art 疑问:引入的实体库信息只是训练时后还要存下来测试用啊...每个语料都有自己做一个字典? 第三个特征引入方式:建立词字典 以及..再次跳过了分词 背景:通用的半监督方法,通过双向语言模型从未标记文本中学习词嵌入添加到NLP系统,并将其应用于序列标记任务。语料库再利用/小语料集 也有dense层,只关注右侧: 单项编码: 即计算序列的出现的概率:从句首和句尾两个方向预测序列下一个词是什么,丢进LSTM,将语言模型最后一层softmax去掉(实验表明),得到LM embedding。 双层LM是独立的 和左方LSTM第一层隐层一起拼接 或 未来工作:attention 对比实验: LM用什么模型影响还挺大(双向) 若只有LM层,F1值为88,做为bilstm+crf的辅助 对领域特定的预训练是不必要的 LM层信息的Concat在哪儿 对比: word2vec 一定窗口内的上下文语义信息 LM embedding 序列上下文信息(类似马尔科夫链) 结果:state of art 主动学习:通过“选择策略”主动从未标注的样本集中挑选部分(1个或N个)样本让相关领域的专家进行标注;然后将标注过的样本增加到训练数据集给“学习模块”进行训练;当“学习模块”满足终止条件时即可结束程序,否则不断重复上述步骤获得更多的标注样本进行训练。 开始:1%初始数据集 结束:单词库20000个单词 效果:25%的训练集即可接近state of art 体现在采样方法: MNLP:由句子编码(长度归一化)寻找最难(信息量最大)分类类别进行参数更新 BALD:inference 时的dropout 等价于来计算模型的不确定性的。每次在M种结果中取和现模型最不一致的。(我自己也不是很明白,整理下其他博客的解释) 使用对抗网络减少众包标记的不良影响/针对专家集有限的语料 词向量、字符向量加入噪声信息(特别是小语料) 出处为知乎问题 AAAI 2018 有什么值得关注的亮点?www.zhihu.com LSTM+CRF依旧是主流 1.attention:哪里都有(这里没看到那么多) 2.特征引入:难以学习的特征的补充 3.主动学习/半监督学习:小语料、训练集不同利用方式 4.对抗方法的引入 (5.迁移学习/联合学习..:多任务、参数共享..) 
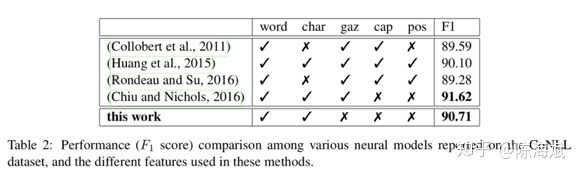
3.Attending to Characters in Neural Sequence Labeling Models(2016COLING)


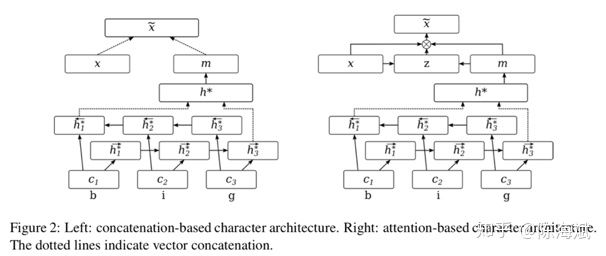

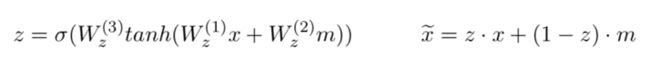
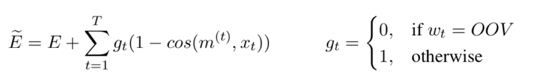
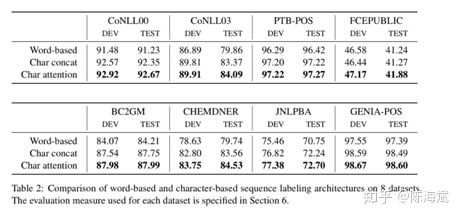
4.Neural Architectures for Fine-grained Entity Type Classification (2017ACL)


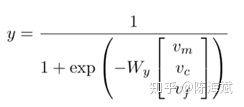

5.Improving Neural Fine-Grained Entity Typing with Knowledge Attention(2018 AAAI)
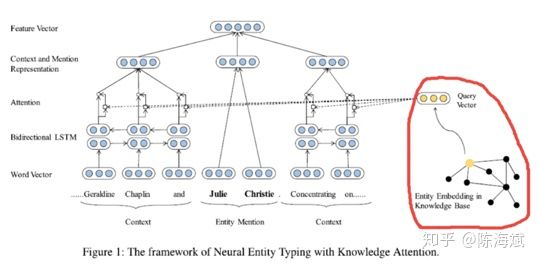
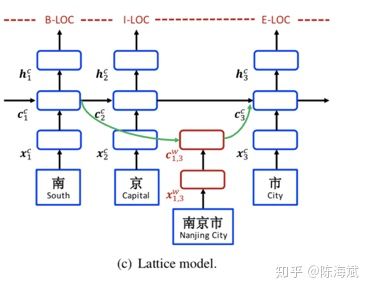
6.Chinese NER Using Lattice LSTM(2018ACL)

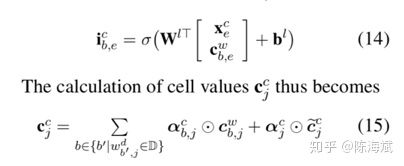
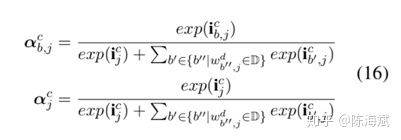
7.Semi-supervised sequence tagging with bidirectional language models(2017ACL)
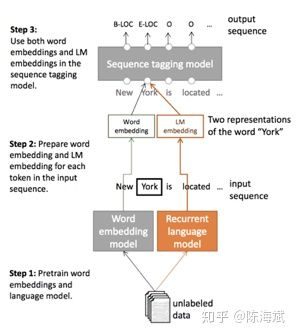
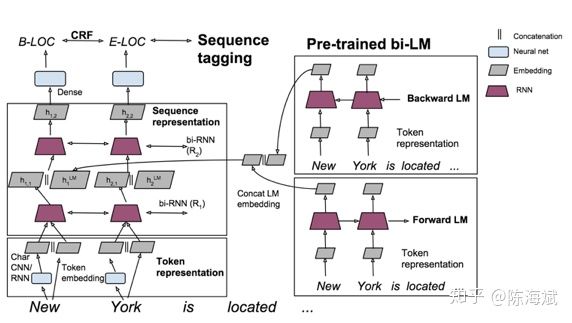

![]()
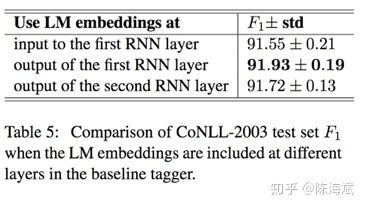
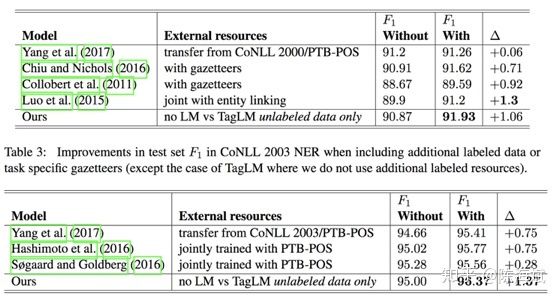
8.Deep Active Learning for Named Entity Recognition(2018ICLR)

9.类似“GAN”对抗
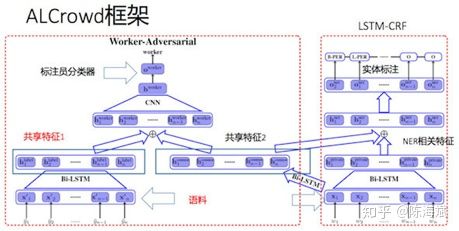


总结: