Robotframework之正则表达式的应用实例
须知:本内容仅供学习交流使用,不用于商业用途。
本文如有侵权,请于24小时内联系作者删除。
看小说,请支持正版。
本文例子使用的网址为 http://m.mingchaonaxieshier.com,《明朝那些事儿》
使用工具:
RIDE,pycharm,fiddler,notepad++
python:3.6.8
操作步骤
1.打开fiddler
进入某个章节页 http://m.mingchaonaxieshier.com/hong-wu-da-di-01.html
查看fiddler抓包,可以得到一些头部信息,请求方式,cookie等等
GET http://m.mingchaonaxieshier.com/hong-wu-da-di-01.html HTTP/1.1
Host: m.mingchaonaxieshier.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Referer: http://m.mingchaonaxieshier.com/hong-wu-da-di
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: _ga=GA1.2.1667830759.1584515856; __gads=ID=df38d1a90059c732:T=1584515849:S=ALNI_MarxInN0F6eU2LTqWdJeWSxuyz3ww; _gid=GA1.2.1698684084.1584932469; _gat=1
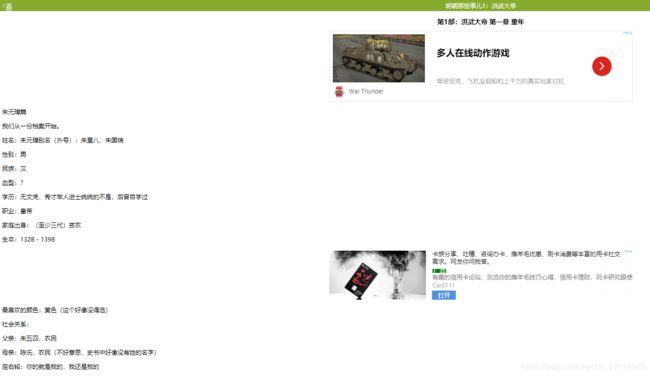
2.查看源代码
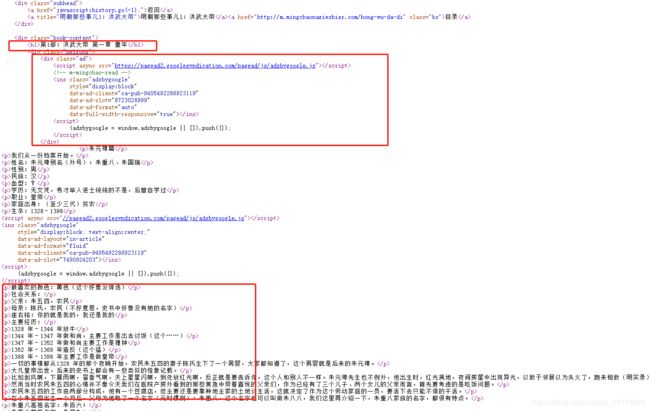
可以把HTML网页分为3部分:标题,内容和广告,以及一些不重要的标签。
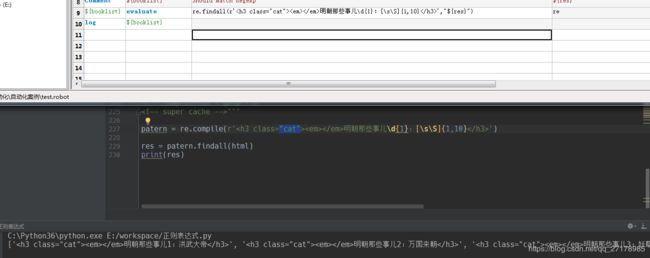
3.编写RIDE脚本
如下:
![]()
说明:
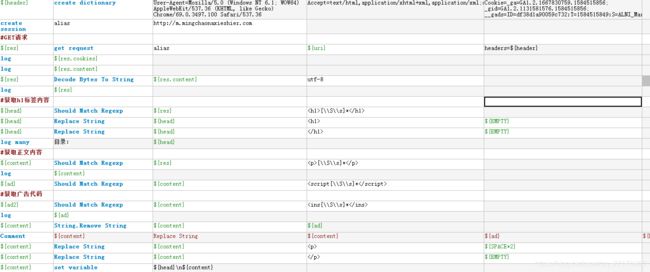
a)使用GET方式发送请求,这里可以不带头部和cookie,因为该网站未进行身份验证;
b)使用Should Match Regexp关键字进行正则表达式的编写,该关键字返回所有匹配的内容,然后对不需要的标签进行删除;
c)正文里面有2个广告标签,用 b) 步骤进行删除;
d)将替换的内容写入txt,这里用python脚本实现并进行引用,如下:
![]()
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
def writeFile(content,filepath):
"""
写入文件
:param content:要写入的内容
:param filepath:带文件名的路径
:return:
"""
#判断是否存在该目录
dirname = os.path.dirname(filepath)
print(dirname)
if os.path.exists(dirname):
print('已存在目录:',dirname)
else:
print("不存在目录:",dirname)
os.makedirs(dirname)
print ("创建目录成功!")
file = os.path.isfile(filepath);
#以读写模式打开文件,在后面追加内容
with open(filepath,'a+') as f:
filename = os.path.basename(filepath)
if file:
print("已存在文件:",filename,)
else:
print("文件不存在!创建文件:",filename)
f.writelines(content)
f.writelines('\n')
print ("写入数据成功!")
f.close()
if __name__=='__main__':
content = "啊啊啊啊啊3"
writeFile(content,'C:\\Users\\Administrator\\Desktop\\1\\2.txt')
4. 封装关键字
将上述代码封装成一个关键字【获取单章接口】,并对其进行进一步封装至【获取单部接口】
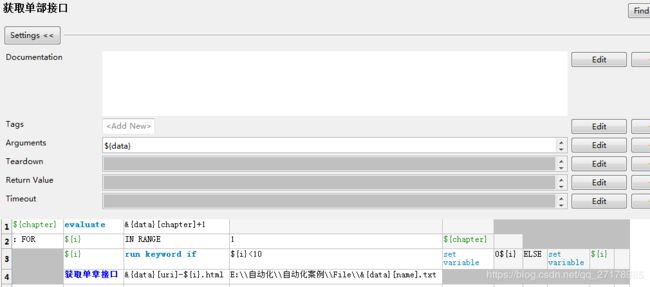
至此,就可以获取全部内容了,如下案例:
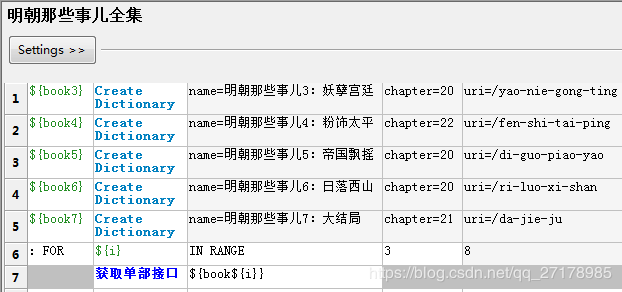
总结:
上述方法虽然已经实现目的,但是实际操作起来还是有些麻烦,如最后的案例里,每一部都需要自己输入名称,章节数及uri。那么接下来就解决这个问题。
扩展
咱们要做的事情有:
1.获取系列小说名称(1-7部)及地址url;
2.获取各章节名称和地址url;
3.将各章节名称和url传给上述关键字【获取单部接口】
实现
见python lxml.etree模块应用 扩展部分 https://blog.csdn.net/qq_27178985/article/details/105124838
说明
由于RIDE上用evaluate方法实现正则表达式不够友好,在pycharm能跑通的正则照搬到ride报错,故而改成lxml.etree模块实现功能。