BiLSTM+CRF命名实体识别:达观杯败走记(上篇)
一 :今日吐槽
去年7月份入职那会,由达观数据主办的信息抽取大赛正在进行中,那是一个命名实体识别的比赛。
听大佬们说,参加比赛是一种DFS的学习方法,带着问题去学习,比按部就班地看书和听课效果更好。
想起多年前,三天搞定一个题目的数学建模比赛经历,我激动地直拍高铁的座椅:
这比赛给了俩月呢!
在广州到上海的路上我就组好了队。
拿到比赛数据,小群里开始热火朝天:
把IOB格式改为IOBES格式
把词的长度特征,做embedding,再和字向量拼接
模型可以试试IDCNN+CRF,训练更快
NLP中的数据增强不可能不用
地表最强的BERT必须安排一下
两周过去了,自己用keras写好的模型拿了0.66分。
一个月过去了,git clone 的pytorch版 baseline 勉强跑通。
两个月过去了,我把《十强选手方案》搬运到安静的群里,又回到了峡谷。
身体里沉睡的野兽,觉醒了!
战斗,让我忘记疯狂!
球球你阻止我!
二:内容预
上个月写了篇文章,介绍了怎么用双向最大匹配+实体词典进行实体自动标注。
双向最大匹配和实体标注:你以为我只能分词?
如此一来,有了实体词典,实体识别中最繁琐的样本标注问题就解决了。
目前我手头有一份标注好的医疗实体数据集,训练集、验证集和测试集的数量分别为:101218 / 7827 / 16804,医疗实体有15类:
{'PSB', 'SGN', 'PT', 'TES', 'SUR', 'DIS', 'DRU', 'ORG', 'DEG', 'PRE', 'CL', 'SYM', 'REG', 'Dur', 'FW'}数据集不小,实体类别够多,又属于专业领域,适合搞事情。
于是这次整理了一个BILSTM+CRF的模型,经过比较细致地优化,在这份数据的测试集上,F1值可达0.97。
在网上找了条和医疗相关的句子,测试结果如下:
{'entities': [{'end': 7, 'start': 5, 'type': 'ORG', 'word': '心脏'},
{'end': 10, 'start': 8, 'type': 'ORG', 'word': '血管'},
{'end': 40, 'start': 36, 'type': 'DIS', 'word': '心血管病'}],
'string': '循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病。'}BILSTM+CRF尽管是实体识别的一个BaseLine,但是数据预处理、特征构造、损失计算和维特比解码,都有不少需要注意的点。
看了网上的一些代码,你是否和我一样,还有以下疑问:
样本和标签是否需要加
和 标记 怎么把IOB格式转换为IOBES格式
论文源码中的大小写特征(Capitalization feature)怎么借鉴
怎么计算CRF损失
怎么对损失做MASK
这篇文章争取把以上疑问解决,并得到一个F1值达0.97的模型。
完整的数据和代码都已经上传github,这次也有好好写REDME.md。
https://github.com/DengYangyong/medical_entity_recognize
三:预修知识
BILSTM+CRF的模型出自这篇论文:
《Neural Architectures for Named Entity Recognition》
论文介绍了模型结构、损失函数、数据处理格式和参数的配置,是必看的第一手资料。
但是论文对损失函数的介绍,以及如何用动态规划计算损失和解码,不是很详细。
推荐看这两篇文章:
BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数
BiLSTM上的CRF,用命名实体识别任务来解释CRF(3)推理
喂,推荐这两篇文章真不是因为园长就在我背后啊,是因为真的比较清楚啊!
四:数据介绍
代码结构如下:
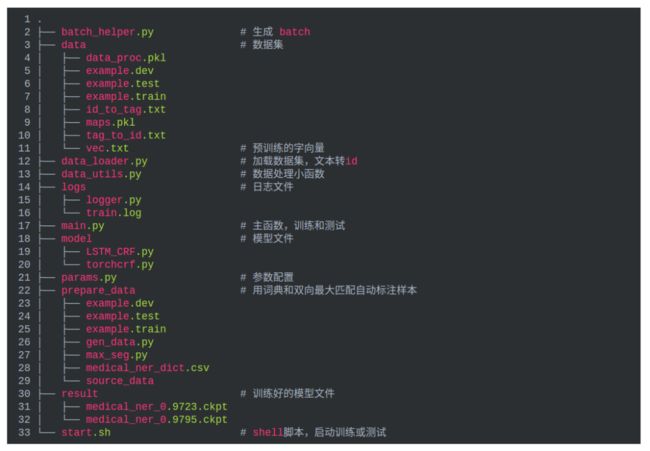
这次的数据集由医疗电子病历标注而成,标注格式为IOB,每个句子是一个样本,句子之间用空格隔开。
O表示这个字不是实体,B表示这个字是实体的开头,实体除开头以外的字,都用I标记。
如下就是两个样本。
入 O
院 O
诊 O
断 O
:O
腰 B-DIS
椎 I-DIS
间 I-DIS
盘 I-DIS
突 I-DIS
出 I-DIS
症 I-DIS
( O
L O
4 O
- O
S O
1 O
) O
。O
诊 O
疗 O
经 O
过 O
:O
完 O
善 O
心 B-TES
电 I-TES
图 I-TES
、 O
胸 B-TES
透 I-TES
、 O
化 B-TES
验 I-TES
等 O
相 O
关 O
检 O
查 O
。O五:数据预处理
数据预处理的代码如下。
一共是六步:
首先将标注好的数据集,整理成样本,每个样本是一个句子。
然后将IOB格式转换成IOBES格式。
接着根据训练集和预训练的字向量,建立字与id的映射,标签与id的映射。
接着加载预训练的字向量。
接着把样本和标签加上
最后保存样本、标签、映射和字向量。
#coding:utf-8
from data_utils import char_mapping,tag_mapping,augment_with_pretrained
from data_utils import zero_digits,iob, iob_iobes, get_seg_features
from logs.logger import logger
from params import params
import os
import pickle
from tqdm import tqdm
import numpy as np
import torch
config = params()
def build_dataset():
train_sentences = load_sentences(
config.train_file, config.lower, config.zero
)
dev_sentences = load_sentences(
config.dev_file, config.lower, config.zero
)
test_sentences = load_sentences(
config.test_file, config.lower, config.zero
)
logger.info("成功读取标注好的数据")
update_tag_scheme(
train_sentences, config.tag_schema
)
update_tag_scheme(
test_sentences, config.tag_schema
)
update_tag_scheme(
dev_sentences, config.tag_schema
)
logger.info("成功将IOB格式转化为IOBES格式")
if not os.path.isfile(config.map_file):
char_to_id, id_to_char, tag_to_id, id_to_tag = create_maps(train_sentences)
logger.info("根据训练集建立字典完毕")
else:
with open(config.map_file, "rb") as f:
char_to_id, id_to_char, tag_to_id, id_to_tag = pickle.load(f)
logger.info("已有字典文件,加载完毕")
emb_matrix = load_emb_matrix(char_to_id)
logger.info("加载预训练的字向量完毕")
train_data = prepare_dataset(
train_sentences, char_to_id, tag_to_id, config.lower
)
dev_data = prepare_dataset(
dev_sentences, char_to_id, tag_to_id, config.lower
)
test_data = prepare_dataset(
test_sentences, char_to_id, tag_to_id, config.lower
)
logger.info("把样本和标签处理为id完毕")
logger.info("%i / %i / %i sentences in train / dev / test." % (
len(train_data), len(dev_data), len(test_data))
)
with open(config.data_proc_file, "wb") as f:
pickle.dump([train_data,dev_data,test_data], f)
pickle.dump([char_to_id,id_to_char,tag_to_id,id_to_tag], f)
pickle.dump(emb_matrix, f)
return train_data,dev_data,test_data, char_to_id, tag_to_id, emb_matrix01
构造样本
由于数据集中,每一行是一个字和对应的标签,而样本是一个句子,那么需要把字添加到句子中,遇到换行符,则表明句子已经结束,下一个字属于另一个句子。
另外,数据处理的一个小技巧是,把数据集中的数字,全部用0替换,然后大写字母转化为小写。当然,这个可以自行选择。
def load_sentences(path, lower, zero):
"""
加载训练样本,一句话就是一个样本。
训练样本中,每一行是这样的:长 B-Dur,即字和对应的标签
句子之间使用空行隔开的
return : sentences: [[[['无', 'O'], ['长', 'B-Dur'], ['期', 'I-Dur'],...]]
"""
sentences = []
sentence = []
for line in open(path, 'r',encoding='utf8'):
""" 如果包含有数字,就把每个数字用0替换 """
line = line.rstrip()
line = zero_digits(line) if zero else line
""" 如果不是句子结束的换行符,就继续添加单词到句子中 """
if line:
word_pair = ["", line[2:]] if line[0] == " " else line.split()
assert len(word_pair) == 2
sentence.append(word_pair)
else:
""" 如果遇到换行符,说明一个句子处理完毕 """
if len(sentence) > 0:
sentences.append(sentence)
sentence = []
""" 最后一个句子没有换行符,处理好后,直接添加到样本集中 """
if len(sentence) > 0:
sentences.append(sentence)
return sentences 处理好后,每个样本的如下:
train_sentences[0]
[['无', 'O'], ['长', 'B-Dur'], ['期', 'I-Dur'], ['0', 'O'], ['0', 'O'], ['0', 'O'], ['年', 'O']02
转换为IOBES格式
论文中作者是将IOB格式转化为了IOBES格式,也就是:
如果实体只有一个字,那就用S标记。
如果实体有两个字或以上,那么开头用B标记,结尾用E标记,中间的字用I标记。
IOBES这种标记方式按道理是更好的,因为提供了更丰富的信息,用特定的符号来标记开头和结尾,便于在预测时提取实体。
比如以下就是预测时,提取实体的格式:
{'entities': [{'end': 7, 'start': 5, 'type': 'ORG', 'word': '心脏'},
{'end': 10, 'start': 8, 'type': 'ORG', 'word': '血管'},
{'end': 40, 'start': 36, 'type': 'DIS', 'word': '心血管病'}],
'string': '循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病。'}实际转换的时候,我们先对IOB格式进行检查,如果有不合理的,则纠正。
比如下面这个就是错误的格式,I不能作为开头,O也不可能为实体的标记。
[O,I-ORG,B-ORG,O,O-ORG,...]纠正之后,再转换为IOBES格式。
具体的纠正和转换函数,直接用就好了,自己写是很难写出来的(-.-)。
def update_tag_scheme(sentences, tag_scheme):
"""
1:检查样本的标签是否为正确的IOB格式,如果不对则纠正。
2:将IOB格式转化为IOBES格式。
"""
for i, s in enumerate(sentences):
tags = [w[-1] for w in s]
if not iob(tags):
s_str = '\n'.join(' '.join(w) for w in s)
print('Sentences should be given in IOB format! \n' +
'Please check sentence %i:\n%s' % (i, s_str))
""" 如果用IOB格式训练,则检查并纠正一遍 """
if tag_scheme == 'iob':
for word, new_tag in zip(s, tags):
word[-1] = new_tag
elif tag_scheme == 'iobes':
""" 将IOB格式转化为IOBES格式 """
new_tags = iob_iobes(tags)
for word, new_tag in zip(s, new_tags):
word[-1] = new_tag转换后的样本格式如下:
[['突', 'B-SYM'], ['发', 'E-SYM'], ['右', 'B-REG'], ['侧', 'I-REG'], ['肢', 'I-REG'], ['体', 'E-REG'],...]03
建立字、标签到id的映射
下面的两个函数分别用来构造字和id的映射、标签和id的映射,在data_utils.py中。
首先create_dico这个函数统计字、标签的频率字典,再按频率降序,构造item到id的映射。
因为要对每个batch中不等长的输入序列做zero pad,让batch中样本长度一致,所以给
又因为这是加了CRF的模型,所以需要在样本和标签的前后加
以下构造字和id的映射:
def char_mapping(sentences, lower):
"""
建立字和id对应的字典,按频率降序排列
由于用了CRF,所以需要在句子前后加和
那么在字典中也加入这两个标记
"""
chars = [[x[0].lower() if lower else x[0] for x in s] for s in sentences]
dico = create_dico(chars)
dico[""] = 100000003
dico[''] = 100000002
dico[""] = 100000001
dico[""] = 100000000
char_to_id, id_to_char = create_mapping(dico)
logger.info("Found %i unique words (%i in total)" % (len(dico), sum(len(x) for x in chars)))
return dico, char_to_id, id_to_char
以下构造标签和id的映射:
def tag_mapping(sentences):
"""
建立标签和id对应的字典,按频率降序排列
由于用了CRF,所以需要在标签前后加和
那么在字典中也加入这两个标记
"""
f = open('data/tag_to_id.txt','w',encoding='utf8')
f1 = open('data/id_to_tag.txt','w',encoding='utf8')
tags = [[x[-1] for x in s] for s in sentences]
dico = create_dico(tags)
dico[""] = 100000002
dico[""] = 100000001
dico[""] = 100000000
tag_to_id, id_to_tag = create_mapping(dico)
logger.info("Found %i unique named entity tags" % len(dico))
for k,v in tag_to_id.items():
f.write(k+":"+str(v)+"\n")
for k,v in id_to_tag.items():
f1.write(str(k)+":"+str(v)+"\n")
return dico, tag_to_id, id_to_tag 为啥要加
以下内容引用自论文。
y(0) and y(n) are the start and end tags of a sentence, that we add to the set of possible tags.
以下内容引用自上面第一篇文章:
为了使transition评分矩阵更健壮,我们将添加另外两个标签,START和END。START是指一个句子的开头,而不是第一个单词。END表示句子的结尾。
ronghuaiyang,公众号:AI公园BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数
以下为转移矩阵的样子,我们可以看到从 START到 I-Person 的概率非常低(0.007),而从START到B-Person的概率非常高(0.8)。
这可以让转移矩阵学习到有用的约束:让一个句子的第一个字标记为I的概率非常低,标记为B的概率非常高,从而提高标注的准确率。

另外,由于使用了预训练的字向量,我们需要把在字向量中但是不在训练集中的字,加入到字与id的映射中。
下面这段代码用到了上面两个函数。
def create_maps(sentences):
"""
建立字和标签的字典
"""
if config.pre_emb:
""" 首先利用训练集建立字典 """
dico_chars_train, _, _ = char_mapping(sentences, config.lower)
""" 预训练字向量中的字,如果不在上面的字典中,则加入 """
dico_chars, char_to_id, id_to_char = augment_with_pretrained(dico_chars_train.copy(),
config.emb_file)
else:
""" 只利用训练集建立字典 """
_, char_to_id, id_to_char = char_mapping(sentences, config.lower)
""" 利用训练集建立标签字典 """
_, tag_to_id, id_to_tag = tag_mapping(sentences)
with open(config.map_file, "wb") as f:
pickle.dump([char_to_id, id_to_char, tag_to_id, id_to_tag], f)
return char_to_id, id_to_char, tag_to_id, id_to_tag建立的字和id的映射、标签和id的映射如下:
char_to_id
{'': 0, '': 1, '': 2, '': 3, '0': 4, ',': 5, ':': 6, '。': 7, '无': 8, '、': 9, '常': 10, ...}
tag_to_id
{'': 0, '': 1, '': 2, 'O': 3, 'I-TES': 4, 'I-DIS': 5, 'I-SGN': 6, 'B-TES': 7, ...} 04
加入
接着在样本(句子)和标签的前后加入
如果模型训练好了,输入一条句子预测,那么句子没有自带标签,所以test=True
时,tags_idx随便搞,只要和句子长度一致即可。
def prepare_dataset(sentences, char_to_id, tag_to_id, lower=False, test=False):
"""
把文本型的样本和标签,转化为index,便于输入模型
需要在每个样本和标签前后加和
"""
def f(x): return x.lower() if lower else x
data = []
for s in sentences:
chars = [w[0] for w in s]
tags = [w[-1] for w in s]
""" 句子转化为index """
chars_idx = [char_to_id[f(c) if f(c) in char_to_id else ''] for c in chars]
""" 对句子分词,构造词的长度特征 """
segs_idx = get_seg_features("".join(chars))
""" 每个样本前后加和 """
chars_idx = [char_to_id[""]] + chars_idx + [char_to_id[""]]
segs_idx = [0] + segs_idx + [0]
""" 把标签转化为index, 标签前后加和 """
tags = [""] + tags + [""]
if not test:
tags_idx = [tag_to_id[t] for t in tags]
else:
tags_idx = [tag_to_id[""] for _ in tags]
assert len(chars_idx) == len(segs_idx) == len(tags_idx)
data.append([chars_idx, segs_idx, tags_idx])
return data 另外注意到有个segs_idx,这是什么?
这是对句子进行分词后,提取的词长度特征,作为字向量特征的补充。
每个字的长度特征为0~3的一个id,后面我们把这个id处理为20维的向量,和100维的字向量进行拼接,得到120维的向量。
具体的解释看下面的代码。
def get_seg_features(string):
"""
对句子分词,构造词的长度特征,为BIES格式,
[对]对应的特征为[0],
[句子]对应的特征为[1,3],
[中华人民]对应的特征为[1,2,2,3]
"""
seg_feature = []
for word in jieba.cut(string):
if len(word) == 1:
seg_feature.append(0)
else:
tmp = [2] * len(word)
tmp[0] = 1
tmp[-1] = 3
seg_feature.extend(tmp)
return seg_feature比如下面这个句子的分词特征为:
句子:
"循环系统由心脏、血管和调节血液循环的神经体液组织构成"
分词结果:
['循环系统', '由', '心脏', '、', '血管', '和', '调节', '血液循环', '的', '神经', '体液', '组织', '构成']
长度特征:
[1, 2, 2, 3, 0, 1, 3, 0, 1, 3, 0, 1, 3, 1, 2, 2, 3, 0, 1, 3, 1, 3, 1, 3, 1, 3]这个是怎么来的?
论文的源码中用到了一个叫做Capitalization feature 的特征,也就是单词的大小写特征,也是作为嵌入,和单词向量进行拼接。
def cap_feature(s):
"""
Capitalization feature:
0 = low caps
1 = all caps
2 = first letter caps
3 = one capital (not first letter)
"""
if s.lower() == s:
return 0
elif s.upper() == s:
return 1
elif s[0].upper() == s[0]:
return 2
else:
return 3所以我们的分词特征借鉴了上面的思路,应该可以提供更丰富的信息。
六:batch 分桶
把数据构造成batch,没有用pytorch的 Dataset 和 DataLoader 这两个函数,因为不方便做 batch 分桶。
啥叫batch分桶?
这个叫法很土,意思是把所有样本先按长度排序,生成batch的时候,长度相近的样本在一个batch内,batch内部按最长的样本长度进行zero pad。
而batch之间的长度不同,最大程度减少了zero pad 的数量,从而加快训练速度。
#coding:utf-8
import math
import random
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class BatchManager(object):
def __init__(self, data, batch_size):
self.batch_data = self.sort_and_pad(data, batch_size)
self.len_data = len(self.batch_data)
def sort_and_pad(self, data, batch_size):
"""
把样本按长度排序,然后分batch,再pad
batch之间的输入长度不同,可以减少zero pad,加速计算
"""
num_batch = int(math.ceil(len(data) / batch_size))
sorted_data = sorted(data, key=lambda x: len(x[0]))
batch_data = list()
for i in range(num_batch):
""" 进行zero pad """
batch_data.append(self.pad_data(
sorted_data[i*int(batch_size): (i+1)*int(batch_size)])
)
return batch_data
@staticmethod
def pad_data(data):
"""
构造一个mask矩阵,对pad进行mask,不参与loss的计算
"""
batch_chars_idx = []
batch_segs_idx = []
batch_tags_idx = []
batch_mask = []
max_length = max([len(sentence[0]) for sentence in data])
for line in data:
chars_idx, segs_idx, tags_idx = line
padding = [0] * (max_length - len(chars_idx))
batch_chars_idx.append(chars_idx + padding)
batch_segs_idx.append(segs_idx + padding)
batch_tags_idx.append(tags_idx + padding)
batch_mask.append([1] * len(chars_idx) + padding)
batch_chars_idx = torch.LongTensor(batch_chars_idx).to(device)
batch_segs_idx = torch.LongTensor(batch_segs_idx).to(device)
batch_tags_idx = torch.LongTensor(batch_tags_idx).to(device)
batch_mask = torch.tensor(batch_mask,dtype=torch.uint8).to(device)
return [batch_chars_idx, batch_segs_idx, batch_tags_idx, batch_mask]
def iter_batch(self, shuffle=True):
if shuffle:
random.shuffle(self.batch_data)
for idx in range(self.len_data):
yield self.batch_data[idx]另外,由于对batch内不够长的样本进行了 zero pad,训练时,模型会预测每个字包括
那么
chars:
["神","经","体","液","组","织","","",""]
mask:
[1,1,1,1,1,1,0,0,0] 好了,上篇就介绍数据预处理和batch的生成,下篇介绍模型和训练。
参考资料:
1:《Neural Architectures for Named Entity Recognition》
2:《BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数》
END
添加个人微信,备注:昵称-学校(公司)-方向,即可获得
1. 快速学习深度学习五件套资料
2. 进入高手如云DL&NLP交流群

记得备注呦
