论文阅读|SMPL2015
摘要:
我们提出了一个学习过的人体形状和姿势相关的形状变化模型,该模型比以前更准确建模并与现有的图形管线兼容。我们的蒙皮多人线性模型(SMPL)是基于蒙皮顶点的模型,可以准确地表示各种各样的人体姿态。模型的参数是从数据中学习得的,包括静止姿势模板,混合权重,姿势相关的混合形状,身份相关的混合形状以及从顶点到关节位置的回归器。与以前的模型不同,姿势相关的混合形状是姿势旋转矩阵的元素的线性函数。这个简单的公式可以从相对大量的模型中训练得出,训练数据是不同姿势的不同人的3D网格对齐。我们使用线性或双四元数定量评估SMPL的变体混合蒙皮,并显示两者比在相同数据上训练的Blend SCAPE模型更准确。我们还将SMPL扩展到逼真的模拟动态软组织变形。因为它是基于混合蒙皮的,SMPL与现有的渲染引擎兼容,我们将其用于研究目的。
1 介绍
我们的目标是创建逼真的动画人体,该人体可以表现出不同的身体形状,通过姿势自然变形,并像真实人类一样表现出柔软的组织运动。我们想要这样模型渲染得尽量快,易于部署并与现有的渲染引擎兼容。商业方法通常涉及手工装配网格并手动雕刻混合形状来纠正传统蒙皮方法产生的问题。许多融合通常需要形状,并且需要人工来建造他们所需的成本很大。作为替代方案,研究委员会已着重从示例扫描中学习统计身体模型。不同的身体,构成各种姿势。虽然有前途,这些方法与现有的图形软件不兼容,也与使用标准蒙皮方法的引擎不兼容。
我们的目标是自动学习出一个身体模型,即真实又能与现有的图形软件兼容。为了达到目标,我们描述了“肤色多人线性”(SMPL)模型,这个模型可以真实地代表各种各样的人体形状,可以摆出与姿势有关的自然变形,表现出软组织的动力学,可以有效地进行动画处理,并与现有的渲染引擎兼容(图1)。
传统方法模拟顶点如何与基础骨架结构相关。基本线性混合蒙皮(LBS)模型是使用最广泛的,被所有的游戏引擎支持,并且能高效渲染。不幸的是,它们在包括著名的“太妃糖”和“领结”在内的关节处产生了不切实际的变形效果(见图2)。改善这些效果的剥皮方法已经进行了大量工作。从数据中学习高度真实的身体模型也有很多工作。这些方法可以捕捉身体形态以及由于姿势引起的非刚性变形。最现实的方法可以说是基于三角形变形。尽管进行了上述研究,但现有模型要么缺乏现实性,要么不与现有软件包一起使用,要么不能代表各种各样的身体形状,或者不与标准图形管线兼容,或需要大量的体力劳动。
与以前的方法相比,我们工作的主要目标是使身体模型尽可能简单和标准,以便可以广泛使用,同时保持从数据中学到的基于变形的模型的真实感。具体来说,我们学习混合形状,以纠正标准skinning的局限性。用于身份,姿势和软组织动力学的不同混合形状在与其他模板进行累加组合,再通过混合蒙皮进行转换。我们方法的关键组成部分是我们将姿势混合形状公式化为部分旋转矩阵元素的线性方程。该配方与以前的方法不同,使混合形状的训练和动画变得更加简单。因为旋转矩阵的元素有界,因此产生的变形也有界,有助于我们的模型泛化性更好。
我们的公式允许一个目标函数,该函数可以惩罚已生成的网格和我们的模型之间的每个顶点差异,从而能够进行数据练。要了解人们如何随着姿势变形,我们使用1786个高分辨率3D扫描不同对象的各种姿势。我们将模板网格与每次扫描对齐以创建训练集。我们优化混合权重,取决于姿势混合形状,平均模板形状(静止姿势),还有从形状到关节位置的回归变量,以最小化训练集上模型的顶点误差。这个关节回归器预测关节的位置与身体形状的关系,这对于为任何身体形状设置逼真的姿势相关的变形至关重要。所有参数均从对齐的扫描中自动估算。
我们从CAESAR数据集的男性和女性的身体中使用主成分分析学习到一个线性模型。 我们首先为每次扫描记录一个模板网格,并对数据进行归一化,这在学习基于顶点的形状模型时非常重要。所得的主要成分变为身体形状的混合形状。
我们以各种形式训练SMPL模型,并将其与BlendSCAPE模型在完全相同的数据下进行定量比较。 我们用动画定性评估模型,并使用未用于训练的网格定量评估模型。我们将SMPL和BlendSCAPE拟合到这些网格,然后比较顶点误差。 探索了SMPL的两个主要变体,一个使用线性混合蒙皮(LBS),另一个使用双四元数混合蒙皮(DQBS), 参见图2。令人惊奇的是,基于顶点的蒙皮模型(例如SMPL)实际上比基于变形的模型(如BlendSCAPE)基于相同数据进行训练更准确。 测试网格可用于研究目的,因此其他网格可以与SMPL进行定量比较。
我们通过调整Dyna模型来扩展SMPL模型以捕获软组织动力学[Pons-Moll等。 2015]。从与Dyna相同的4D网格数据集中训练生成的Dynamic-SMPL或DMPL模型。但是,DMPL基于顶点而不是三角形变形。我们计算SMPL和Dyna训练网格之间的顶点误差,将其转换为静止姿势,然后使用PCA降低尺寸,生成动态混合形状。然后,我们根据角速度和零件的加速度以及动态变形的历史来训练软组织模型,如[Pons-Moll等。由于软组织动力学强烈依赖于身体形状,因此我们使用体重指数变化的身体训练DMPL,并学习依赖于身体形状的动态变形模型。在标准渲染引擎中对软组织动力学进行动画处理仅需要从姿势序列中计算出动态线性混合形状系数。Dyna和DMPL的并排动画显示DMPL更逼真。 SMPL的这一扩展说明了我们的添加混合形状方法的通用性,显示了变形如何取决于身体形状,并演示了如何为身体形状建模提供可扩展的基础。
使用标准渲染引擎,SMPL模型可以比在CPU上更快地实时动画。因此,SMPL解决了该领域的一个开放性问题。 它使动画师可以访问现实的学习模型。因此,SMPL解决了该领域的一个开放性问题。 它使动画师可以访问现实的学习模型。 SMPL基本模板在设计时考虑了动画; 它具有低多边形数,简单的顶点拓扑,干净的四边形结构,标准装备以及合理的面部和手部细节(尽管这里我们并未对手部或面部进行装备)。 SMPL可以表示为可以导入动画系统的Autodesk Filmbox(FBX)文件。 我们将SMPL模型用于研究目的,并提供脚本来驱动Maya,Blender,Unreal Engine和Unity中的模型。
2 相关工作
线性混合蒙皮和混合形状在整个动画行业中被广泛使用。 尽管研究界提出了许多新颖的铰接式人体模型模型,这些模型可产生高质量的结果,但它们与行业实践不兼容。 正如我们在下面总结的那样,许多作者试图将这些世界结合在一起并取得不同程度的成功。
3 模型
我们的蒙皮多人线性模型(SMPL)如图3所示。与SCAPE一样,SMPL模型将身体形状分解为与身份相关的形状和与姿势无关的刚性形状。与SCAPE不同,我们采用基于顶点的蒙皮方法,该方法使用校正混合形状。 单个混合形状表示为级联顶点偏移的向量。单个混合形状表示为级联顶点偏移的向量。 我们从艺术家创建的网格开始,该网格具有N = 6890个顶点和K = 23个关节。 网格具有男女相同的拓扑结构,空间变化的分辨率,干净的四边形结构,分段,初始混合权重和骨架装备。 分割和初始混合权重如图6所示。
按照标准蒙皮做法,该模型由均值模板形状定义,均值模板形状由零姿势下(zero pose 什么是零姿势?)N个连接的顶点的向量所表示,包含一组混合权重,一组混合形状函数,混合形状函数,将形状参数的向量作为输入,并输出混合形状用于雕刻主体身份;还一个函数可以根据形状参数预测K个关节位置; 以及一个与姿势有关的混合形状函数:该函数将姿势参数的矢量作为输入,并考虑与姿势有关的变形的影响。如图3(c)所示,将这些功能的校正混合形状添加到静止姿势(rest position)中。最后,应用标准混合蒙皮函数W(·)(线性或双四元数)以使顶点围绕估计的关节中心旋转,并由混合权重定义平滑度。结果是一个模型,该模型将形状和姿势参数映射到顶点(图3(d))。
下面,我们将同时使用LBS和DQBS蒙皮方法。 通常,蒙皮方法可以被认为是通用的黑匣子。给定一种特殊的蒙皮方法,我们的目标是学习 来纠正该方法的局限性,从而对训练网格进行建模。请注意,学习的姿势混合形状既可以校正由混合蒙皮功能引起的错误,也可以校正由姿势变化导致的静态软组织变形。
来纠正该方法的局限性,从而对训练网格进行建模。请注意,学习的姿势混合形状既可以校正由混合蒙皮功能引起的错误,也可以校正由姿势变化导致的静态软组织变形。
下面我们描述模型中的每个术语。 为方便起见,附录表1中提供了符号摘要。
Blend skining
为了修正思路并定义符号,我们提供了清晰易懂的LBS版本(SMPL的DQBS版本仅需要更改蒙皮方程式)。网格和混合形状是由粗体大写字母(例如X)表示的顶点的向量,而小写粗体字母(例如xi )是表示特定顶点的向量。顶点有时用齐次坐标表示。无论是在标准坐标系还是同构坐标系中,我们对顶点使用相同的表示法,因为从上下文中应该始终清楚需要哪种形式。
身体的姿势是由标准骨骼装备定义的,其中 ![]() 表示运动学树(kinematic tree?https://www.cnblogs.com/21207-iHome/p/8316030.html)中部分k相对于其父项的相对旋转的轴角表示。我们的设备具有K = 23个关节,因此,姿态
表示运动学树(kinematic tree?https://www.cnblogs.com/21207-iHome/p/8316030.html)中部分k相对于其父项的相对旋转的轴角表示。我们的设备具有K = 23个关节,因此,姿态 由3×23 + 3 = 72个参数定义,即每个部分3个加上根方向3个。令
由3×23 + 3 = 72个参数定义,即每个部分3个加上根方向3个。令![]() 表示单位范数旋转轴。 然后,使用Rodrigues公式将每个关节
表示单位范数旋转轴。 然后,使用Rodrigues公式将每个关节 的轴角转换为旋转矩阵.
的轴角转换为旋转矩阵.

当![]() 是3-向量
是3-向量 的斜对称矩阵,
的斜对称矩阵, 是一个3x3的单位矩阵。使用这个,标准的线性混合蒙皮函数
是一个3x3的单位矩阵。使用这个,标准的线性混合蒙皮函数![]() 可以得到静态姿势中的顶点
可以得到静态姿势中的顶点![]() ,关节位置J,一个姿态
,关节位置J,一个姿态![]() ,混合权重W,并且返回posed的顶点。每个顶点
,混合权重W,并且返回posed的顶点。每个顶点![]() 都会变成
都会变成![]()

其中![]() 是混合权重矩阵里W里的元素,表示第k个部分的旋转对顶点的影响。
是混合权重矩阵里W里的元素,表示第k个部分的旋转对顶点的影响。![]() 表示对应关节
表示对应关节 的局部3x3旋转矩阵。
的局部3x3旋转矩阵。![]() 是关节的世界变换,
是关节的世界变换,![]() 是由静止姿势移除变换后的相同变换,
是由静止姿势移除变换后的相同变换,![]() 。中与单个关节中心对应的每个3元素矢量均表示为
。中与单个关节中心对应的每个3元素矢量均表示为![]() ,最后,A(k)表示关节k的关节祖先的有序集合。 注意,为了与现有渲染引擎兼容,我们假设
,最后,A(k)表示关节k的关节祖先的有序集合。 注意,为了与现有渲染引擎兼容,我们假设 是稀疏的,并且最多允许四个部分影响顶点。
是稀疏的,并且最多允许四个部分影响顶点。
为了保持兼容性,我们保留基本蒙皮功能,而是以累加方式修改模板,并学习预测关节位置的功能。 然后我们的模型变成了

其中![]() 和
和![]() 是代表模板偏移集的顶点向量。 我们将它们分别称为形状混合形状(shape blend shapes)和姿势混合形状(posed blend shapes)。
是代表模板偏移集的顶点向量。 我们将它们分别称为形状混合形状(shape blend shapes)和姿势混合形状(posed blend shapes)。
有了这个定义,顶点转换公式为:

其中,其中![]() 和
和![]() 分别是
分别是![]() 和
和![]() 中的顶点,代表顶点ti的形状混合形状和姿态混合形状的偏移量。因此,关节中心现在是身体形状的函数,并且由于混合蒙皮而变形的模板网格(template mesh)现在是姿势和形状的函数。 下面我们详细描述每个术语。
中的顶点,代表顶点ti的形状混合形状和姿态混合形状的偏移量。因此,关节中心现在是身体形状的函数,并且由于混合蒙皮而变形的模板网格(template mesh)现在是姿势和形状的函数。 下面我们详细描述每个术语。
Shapes blend shapes
不同人的身体形状由线性函数![]() 表示
表示

其中![]() ,
,![]() 是线性形状系数的数目,
是线性形状系数的数目,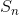 代表形状位移的正交主成分。 然后,线性函数
代表形状位移的正交主成分。 然后,线性函数![]() 由矩阵S完全定义,矩阵S是从已注册的训练网格中获取的。
由矩阵S完全定义,矩阵S是从已注册的训练网格中获取的。
在符号上,分号右边的值表示学习的参数,而左边的值是由动画师设置的参数。 为了符号上的方便,当训练中未明确优化学习的参数时,我们通常会省略它们。图3(b)示出了将这些形状混合形状应用于模板T以产生新的身体形状。
Pose blend shapes
我们将R定义为一个将姿势向量![]() 映射到级联部分相对旋转矩阵
映射到级联部分相对旋转矩阵![]() 的向量的函数。 假设我们的装备有23个关节,则
的向量的函数。 假设我们的装备有23个关节,则![]() 是长度向量(23⇥9 = 207)。
是长度向量(23⇥9 = 207)。![]() 的元素是关节角度的正弦和余弦(方程(19))的函数,因此
的元素是关节角度的正弦和余弦(方程(19))的函数,因此![]() 与
与![]() 有非线性关系。
有非线性关系。
我们的公式与以前的工作不同,在于我们将姿势混合形状的效果定义为![]() 中的线性关系,其中
中的线性关系,其中![]() 表示静止姿态。 令
表示静止姿态。 令![]() 表示
表示![]() 的第n个元素,则其与静态模板的顶点偏差为
的第n个元素,则其与静态模板的顶点偏差为

其中混合形状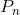 是顶点位移的向量。 这里P = [P1,...,P9K] 2R3N⇥9K是所有207个姿势混合形状的矩阵。 这样,姿势融合形状函数
是顶点位移的向量。 这里P = [P1,...,P9K] 2R3N⇥9K是所有207个姿势混合形状的矩阵。 这样,姿势融合形状函数![]() 完全由矩阵P定义,我们在Sec中学习。
完全由矩阵P定义,我们在Sec中学习。
请注意,减去静止姿势旋转矢量可确保静止姿势中姿势混合形状的贡献为零,这对于动画很重要
Joint locations
不同的身体形状具有不同的关节位置。 每个关节均以其静止姿势中的3D位置表示,这非常重要,要确保它们准确无误,否则当使用蒙皮方程式对模型进行姿势时会出现伪像。 为此,我们将关节定义为身体形状的函数,
 、
、
其中J是将静止顶点转换为静止关节的矩阵。 我们将在许多姿势中从不同人物的例子中学习回归矩阵J,作为我们在Sec中进行整体模型学习的一部分。该矩阵对哪些网格顶点很重要以及如何组合它们以估计关节位置进行建模。
SMPL model:

表示应用混合形状后的顶点i,其中![]() ,
,![]() 是该形状的元素,并构成与模板顶点ti相对应的混合形状。
是该形状的元素,并构成与模板顶点ti相对应的混合形状。
下面我们用LBS和DQBS进行实验,并训练它们的参数。 我们将这些模型称为SMPL-LBS和SMPL-DQBS。 SMPL-DQBS是我们的默认模型,我们将SMPL用作SMPL-DQBS的简写。
4 Training